初級四:為原型注入 AI 能力
章節導讀
1. API 基礎概念
前面提到,我們的目標是「把 AI 能力接進來」,讓原型不再是靜態演示,而是能呼叫真實 AI 服務的工具。要實現這一點,關鍵就在於理解並使用 API(應用程式程式設計介面)。
API 是計算機領域的一個重要抽象概念,我們可以簡單理解為:你按對方要求的格式"發一個問題",對方就按同樣的格式"回一個結果"。
- 你發出去的內容:通常包括"金鑰(API Key)"和"你要生成什麼"
- 對方回給你的內容:成功就給結果;失敗會告訴你原因(比如"金鑰不對""餘額不足""引數寫錯")
具體來說,你需要掌握以下核心要素:
- API Key:你的"通行證",也是"錢包鑰匙"。別人拿到它,就可以替你呼叫介面併產生費用。
- Endpoint(介面路徑):API 請求的具體路徑,告訴伺服器你要訪問哪個功能。完整的請求地址通常由"基礎 URL + Endpoint路徑"構成。例如:
- 文字生成:基礎URL (
https://api.service.com) + Endpoint (/v1/chat/completions) = 完整URLhttps://api.service.com/v1/chat/completions - 影象生成:基礎URL (
https://api.service.com) + Endpoint (/v1/images/generations) = 完整URLhttps://api.service.com/v1/images/generations
- 文字生成:基礎URL (
- 呼叫/請求:向 AI 服務傳送任務並獲取結果的過程
- 請求內容:你發給AI的具體內容,比如你想讓AI寫的文章主題、生成的圖片描述等。
- 響應結果:AI處理完後返回給你的內容,比如生成的文章、圖片等。
- 錯誤處理:當出現問題時(如API Key錯誤、請求太頻繁等),知道如何排查解決。
ℹ️ 什麼是 API
對於 API 的更深入的解釋,請看附錄:API 入門。
🔐 API 安全注意事項
API Key 是你請求 AI 服務的「通行證」,它是一串密碼字串,用於身份驗證和計費。
由於 API Key 直接關聯賬戶和費用,務必注意:
- 絕對不要分享到羣聊、截圖上傳網路或釋出在公開論壇
- 不要硬編碼到程式碼中並提交到 Git 倉庫(尤其是公開倉庫)
- 如懷疑 Key 已洩露,立即更換新 Key
我們會在下面的內容中直接把 API KEY 貼上到 AI IDE 中進行操作,在正規的專案裡不要這麼做!!,由於我們是練習可以這麼做。(等你更加熟練後,你能夠讓 AI 生成一個配置檔案,你只需要把 API KEY 放入配置檔案即可)
2. 接入文字生成 API:DeepSeek
雖然 API 涉及這些技術概念,但在原型開發階段,實際操作可以非常簡單高效。核心思路就是:
找到官方示例、拿到 API Key、讓 AI IDE 幫你接到按鈕上。
掌握了這些概念後,你會發現無論是接入文字模型還是影象模型,其本質流程都是一樣的:當使用者點選按鈕時,前端整理輸入併發起請求;介面返回結果後,再把結果展示到頁面上。接下來,我們就透過實際操作來驗證這一點。
在 1.2 動手做出原型 裡,你已經做出了一個可互動的原型。接下來我們要做的,是把原型裡“看起來像 AI 的功能”變成真正可用的能力:當使用者點選按鈕時,原型會向外部的 AI 服務發出請求,並把返回的文字展示出來。
ℹ️ 原理延伸
如果你想了解更多原理相關的內容,請檢視附錄:大語言模型(LLM)入門。
瞭解更多:DeepSeek 是什麼?
杭州深度求索人工智慧基礎技術研究有限公司(Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.),以 DeepSeek 為商號,是一家開發大語言模型(LLMs)的中國人工智慧(AI)公司。DeepSeek 總部位於浙江杭州,由中國對沖基金幻方量化(High-Flyer)擁有並資助。DeepSeek 由幻方量化的聯合創始人梁文鋒於 2023 年 7 月創立,他也同時擔任這兩家公司的 CEO。該公司於 2025 年 1 月推出了同名聊天機器人及其 DeepSeek-R1 模型。
讓我們看看 DeepSeek 在 GPQA 基準排名中與其他頂級模型的表現對比。值得注意的是,DeepSeek 是一個開源(每個人都可以從網際網路下載模型)模型,而其他常見模型如 Grok、Google Gemini 和 ChatGPT 都是閉源的。正如我們所見,DeepSeek 已經很大程度上接近了第一梯隊的模型。
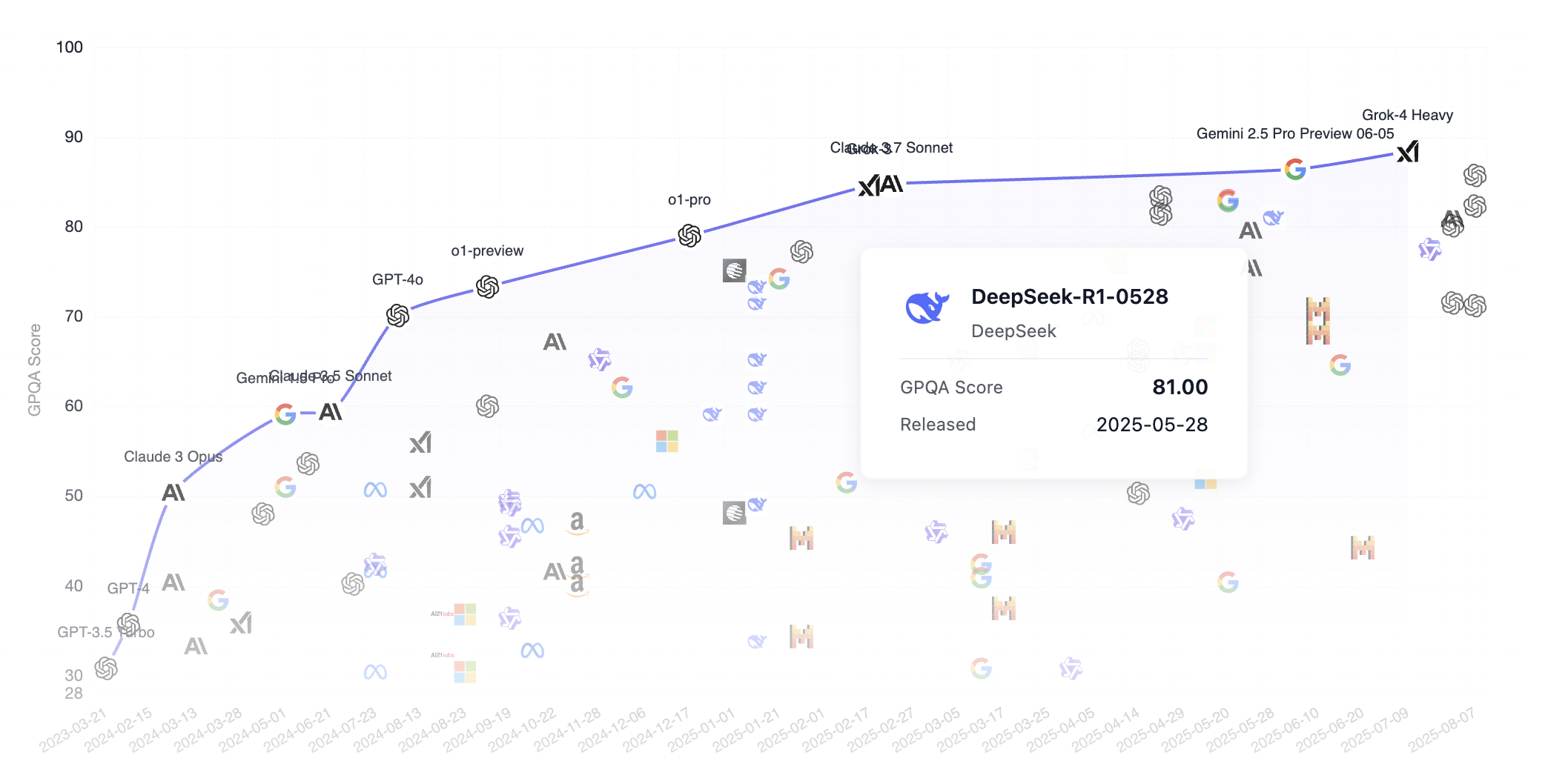
GPQA 是“研究生級 Google-Proof 問答基準”的縮寫,這是一個用於科學問答任務的研究生級基準。以下是詳細介紹。
GPQA 包含 448 個多項選擇題,涵蓋生物學、物理學和化學的子領域,如量子力學、有機化學、分子生物學等。這些問題由 61 位持有博士學位或正在攻讀博士學位的專家編寫,並經過了嚴格的驗證過程。
跟著這 3 步走,就能實現大模型生成 API 的快速整合:
- 在 DeepSeek 平臺建立一個 API Key
- 在 DeepSeek 文件中找到文字生成示例(通常有現成程式碼可直接複製)
- 開啟 AI IDE,把 API Key + 官方示例貼上進去,告訴 AI 要實現什麼功能:
幫我接入這個大模型的 API ,支援這個應用的文案生成任務
接下來我們進行演示,你可以跟隨操作走一遍全流程。首先註冊 DeepSeek 賬號並建立一個 API Key,並且充值少量費用進行驗證。
點選“API KEYS”並在螢幕下方找到“create new API key”。你最終會得到一個像 sk-8573341c39fc44315aadc071c53rh7d2 這樣的 API key。
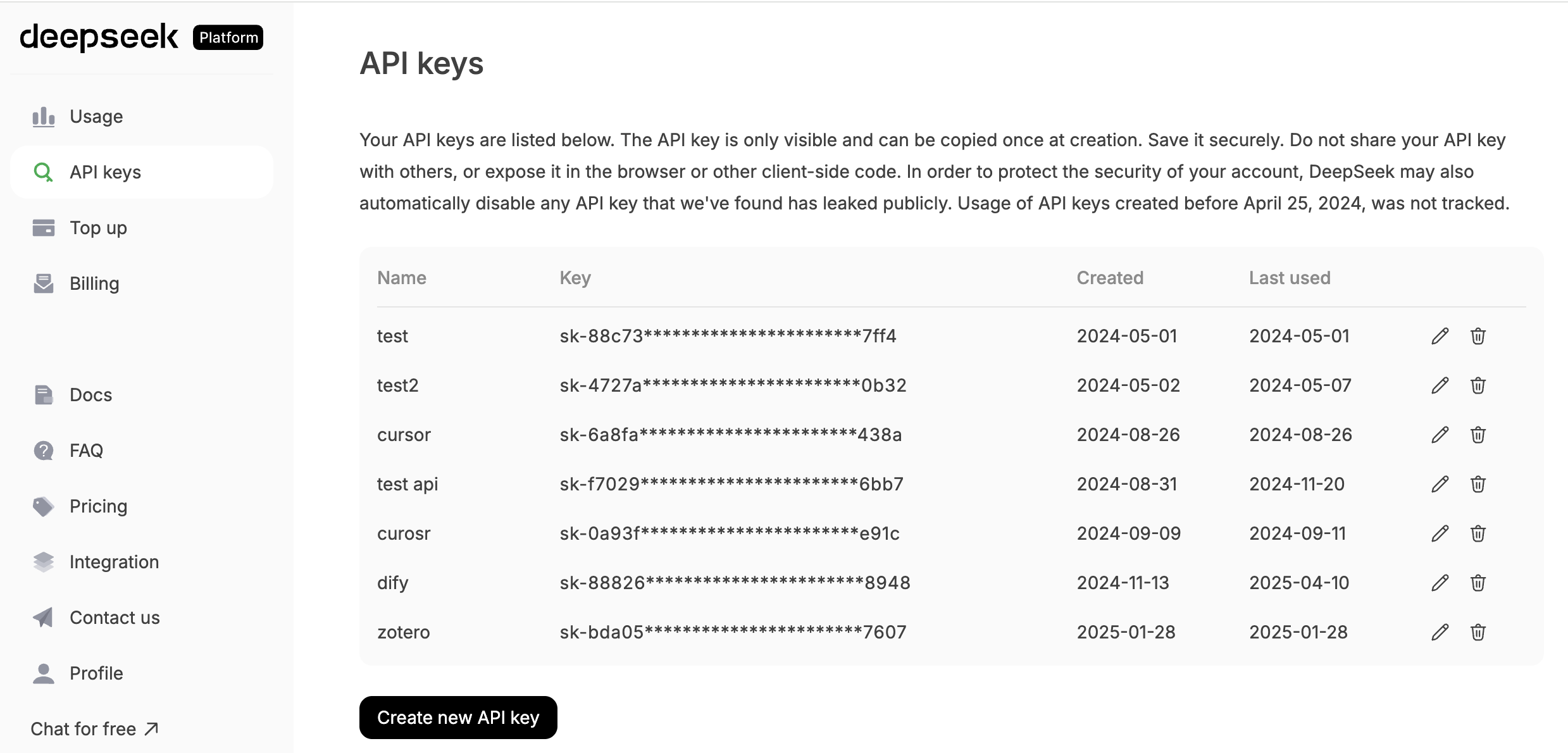
一旦你獲得了金鑰,你就擁有了呼叫模型的許可權。
此時,你可以直接閱讀 API 文件,它通常提供 curl 或 Python 的呼叫示例。
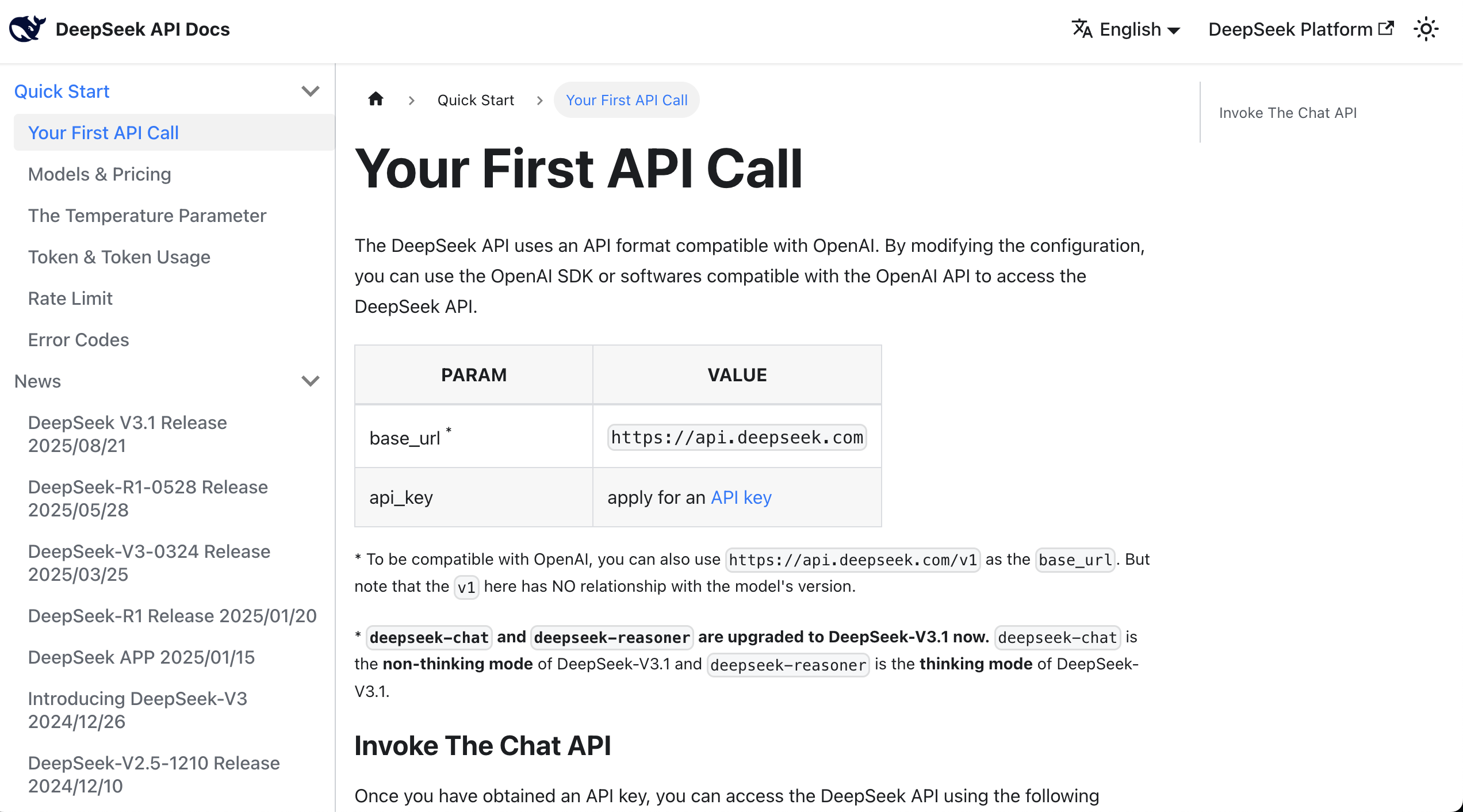
找到示例後,你可以將文件中的所有內容以及金鑰複製到 AI IDE 的對話方塊中,要求它幫你整合大語言模型到之前已經開發的原型中。
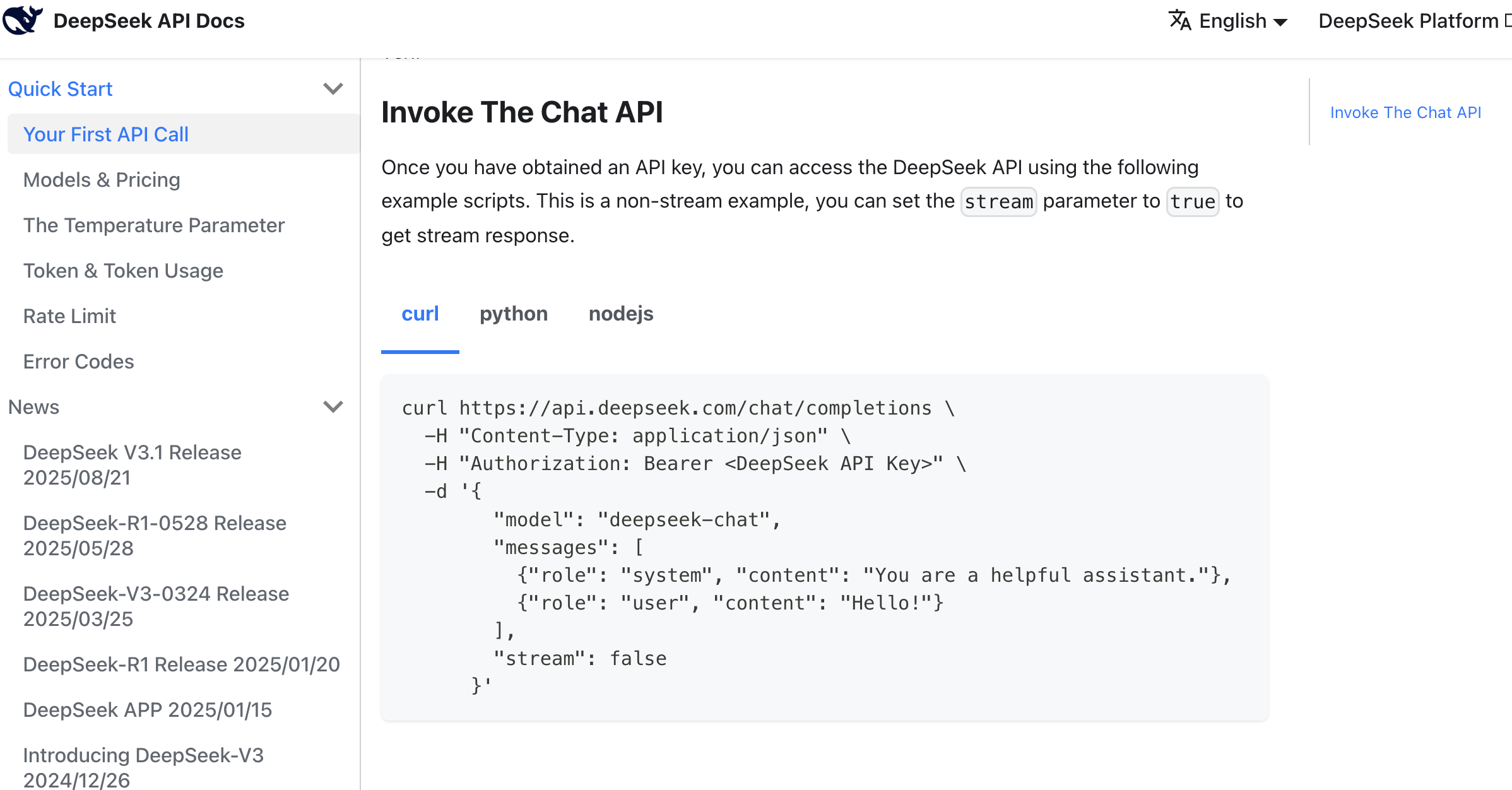
使用提示詞參考如下:
參考這個呼叫方法,幫我支援文案生成功能,可以基於商品資訊點選後生成對應抖音電商文案,多種風格。
以下參考資料:
api key:sk-8573341c39aefa1efe
api 請求參考:
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'經過一段時間的 AI 程式碼生成,我們很容易得到對應的文案生成按鈕進行測試,如果你找不到入口,可以讓 AI IDE 告訴你從什麼頁面可以點到該頁面,如果實在找不到,可以讓 AI IDE 直接基於你的想法重構改進,得到最後的文案生成結果。
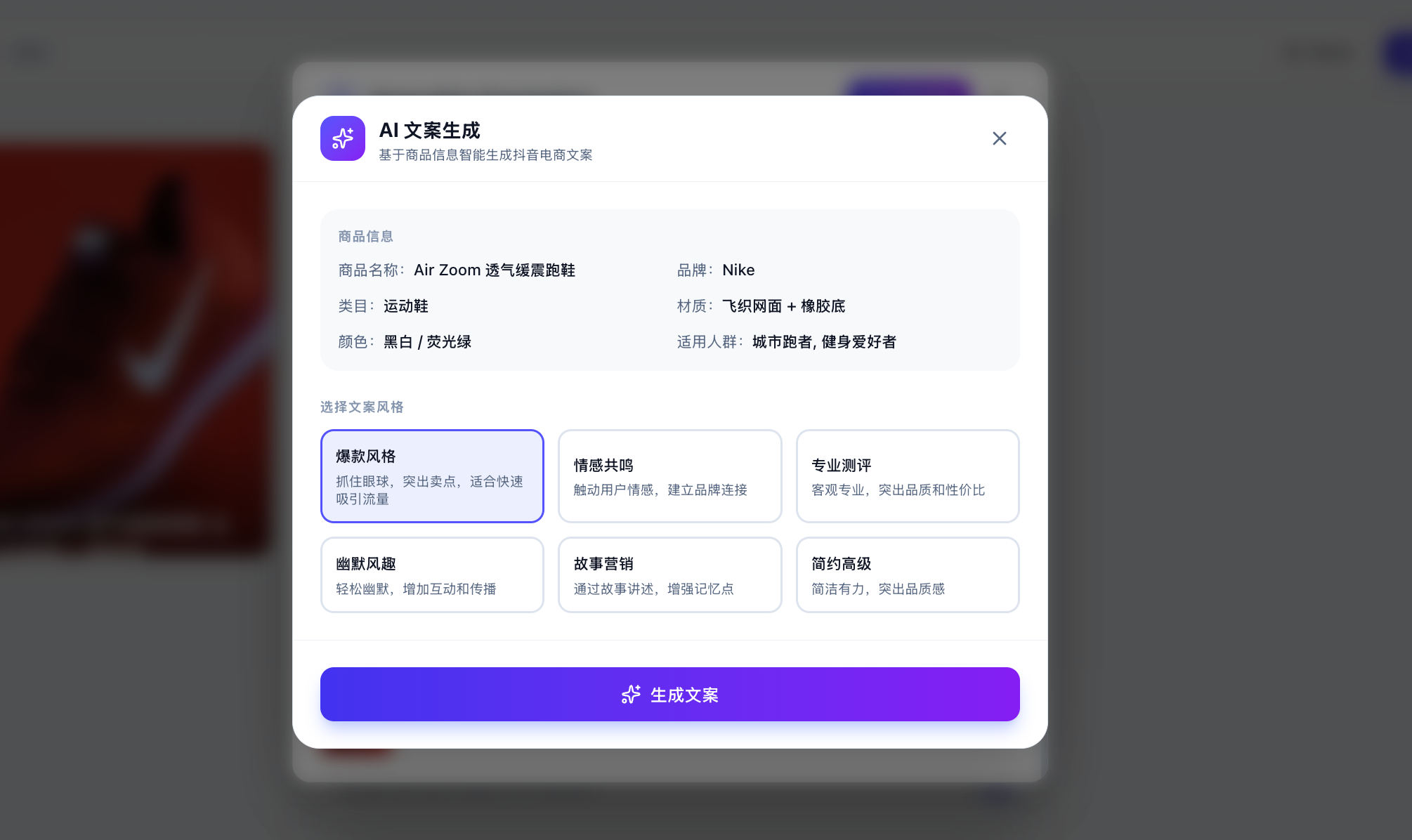
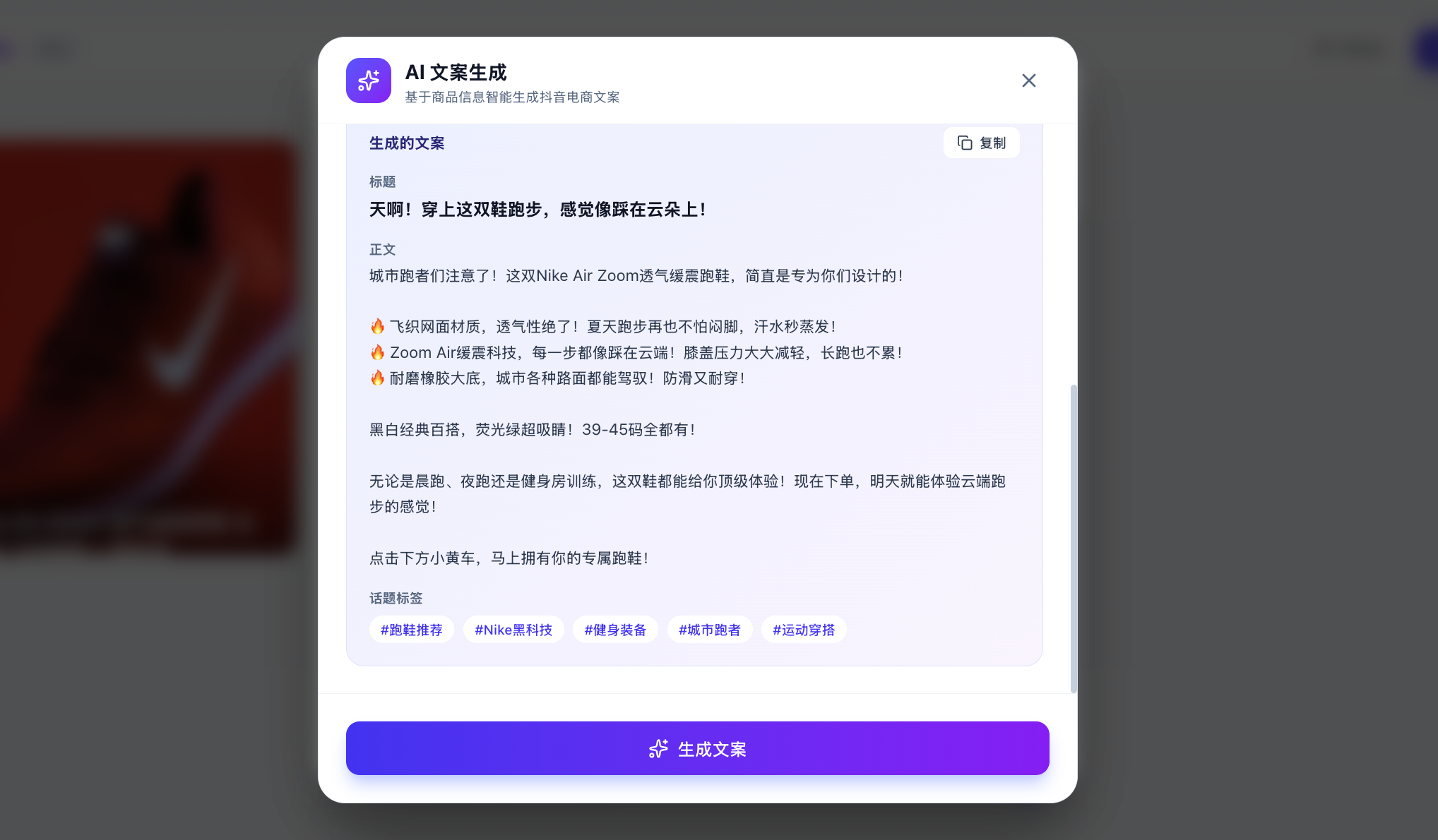
當然,此處你可能想問,我怎麼知道真正呼叫了大模型而不只是內建了固定的回覆?你可以輸入自定義的文案,讓大模型根據你及時指定的自定義分析,生成對應的文案。
如果發現每次不一樣並且合乎邏輯,你可以放心認為此時已經正常呼叫 API 生成。你也可以在 API 使用管理平臺檢視是否成功呼叫(雖然可能需要等幾分鐘才能看到)。
更多文字生成模型選型
除了 DeepSeek 之外,你也可以嘗試其他大語言模型。由於大多數模型都提供了 OpenAI 相容介面,切換起來非常簡單——只需要更換 API Key、基礎 URL 和模型名稱即可。
MiniMax 整合
瞭解更多:MiniMax 是什麼?
MiniMax 是一家中國人工智慧公司,致力於通用人工智慧技術的研發。MiniMax 推出了自研的 MiniMax-M2.7 大語言模型系列,在多項基準測試中表現優異,具有極高的價效比。
MiniMax-M2.7 系列的主要特點:
- 超長上下文:支援 204,800 tokens 的上下文視窗,適合處理長文件、多輪對話
- 高價效比:價格極具競爭力
- OpenAI 相容介面:可以直接使用 OpenAI SDK 呼叫,無需額外學習新的 API 格式
- 兩個可用模型:
MiniMax-M2.7:旗艦模型,適合複雜任務MiniMax-M2.7-highspeed:高速版本,保持同樣的效能但更快
接入方式與 DeepSeek 一致,只需要三步:
- 前往 MiniMax 開放平臺 註冊賬號並建立 API Key
- 在 MiniMax 文件中找到呼叫示例
- 把 API Key + 示例貼上到 AI IDE 中
由於 MiniMax 提供了 OpenAI 相容介面,你可以直接複製下面的 curl 示例和你的 API Key,發給 AI IDE 進行整合:
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.7",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'✅ 提示
MiniMax 的 API 格式與 DeepSeek 幾乎完全一致(都是 OpenAI 相容格式),所以如果你已經成功接入了 DeepSeek,切換到 MiniMax 只需要修改三個地方:
- 基礎 URL:改為
https://api.minimax.io/v1 - API Key:使用 MiniMax 的 API Key
- 模型名稱:改為
MiniMax-M2.7或MiniMax-M2.7-highspeed
更多資訊請參考 MiniMax OpenAI 相容介面文件。
3. 接入影象轉文字 API:Qwen3 VL
ℹ️ 原理延伸
如果你想了解更多原理相關的內容,請檢視附錄:視覺語言模型(VLM)入門。
瞭解更多:Qwen3 VL 是什麼?
Qwen3 VL 是阿里雲通義千問團隊推出的多模態視覺語言模型系列中的最新版本。VL 代表「Vision-Language」,即視覺語言模型。它能夠理解影象內容,並根據影象生成文字描述、回答關於影象的問題、提取影象資訊等。


Qwen3 VL 的主要能力包括:
- 影象理解:能夠識別圖片中的物體、場景、人物、文字等內容
- 視覺問答:根據使用者提問,準確回答關於影象的問題
- 影象描述:生成詳細或簡潔的影象文字描述
- 多圖理解:支援同時處理多張影象,進行對比分析
- 文字提取:從影象中提取文字內容(OCR 能力)
為什麼選擇 Qwen3 VL?
相比上一代模型,Qwen3 VL 在影象理解準確性上有顯著提升,支援更長、更復雜的影象分析任務。它在中文理解方面表現優異,API 呼叫成本相對較低,價效比較高。此外,它的上下文視窗更大,能處理更復雜的視覺推理任務。
典型應用場景:
- 電商:商品圖片自動生成標題、描述、賣點
- 內容創作:根據素材圖自動生成文案或配圖建議
- 辦公:圖片內容提取、報表自動識別
- 教育:圖片題目自動解析、知識點提取
在前面的部分我們說明瞭如何接入文字生成 API, 但對於前面的應用場景我們會發現一個問題,我們上傳的是一張圖片,如果只用大語言模型,它沒辦法很好的理解圖片中的內容,生成的結果很可能會有差別。
我們希望有一個模型能夠幫助我們把一個圖片變成文字描述,這就需要用到視覺語言模型(VLM)。在案例中,我們將會使用視覺語言模型生成商品的賣點描述,提升使用者體驗。
為了方便,我們使用雲平臺 SiliconFlow 提供的 API 介面進行圖生文 API 的接入。
瞭解更多:什麼是 Siliconflow
矽基流動(SiliconFlow) 是國內知名的 AI 模型聚合平臺,提供多種主流大語言模型和視覺語言模型的 API 介面服務。
平臺特點:
- 多模型支援:整合多種主流 AI 模型,包括 DeepSeek、Qwen、Llama 系列等開源模型
- 技術最佳化:針對開源模型進行推理最佳化,提供低延遲、高併發的 API 服務
- 介面相容:提供相容 OpenAI 格式的 API 介面,便於現有應用整合
- 按需付費:支援按呼叫量計費的方式使用
SiliconFlow 在開源大模型的推理服務方面較為成熟,是使用國產開源 AI 模型的常見選擇之一。
進入到 SiliconFlow 平臺的首頁,我們可以看到有很多模型可以選擇,左上角找到篩選器,點選展開篩選器,選擇視覺標籤,我們能看到很多圖片轉文字模型,比如智譜 GLM-4.6V,或者是 Qwen3-VL。
我們可以選擇任意一個進行測試,這裡以 Qwen/Qwen3-VL-8B-Instruct 為例。
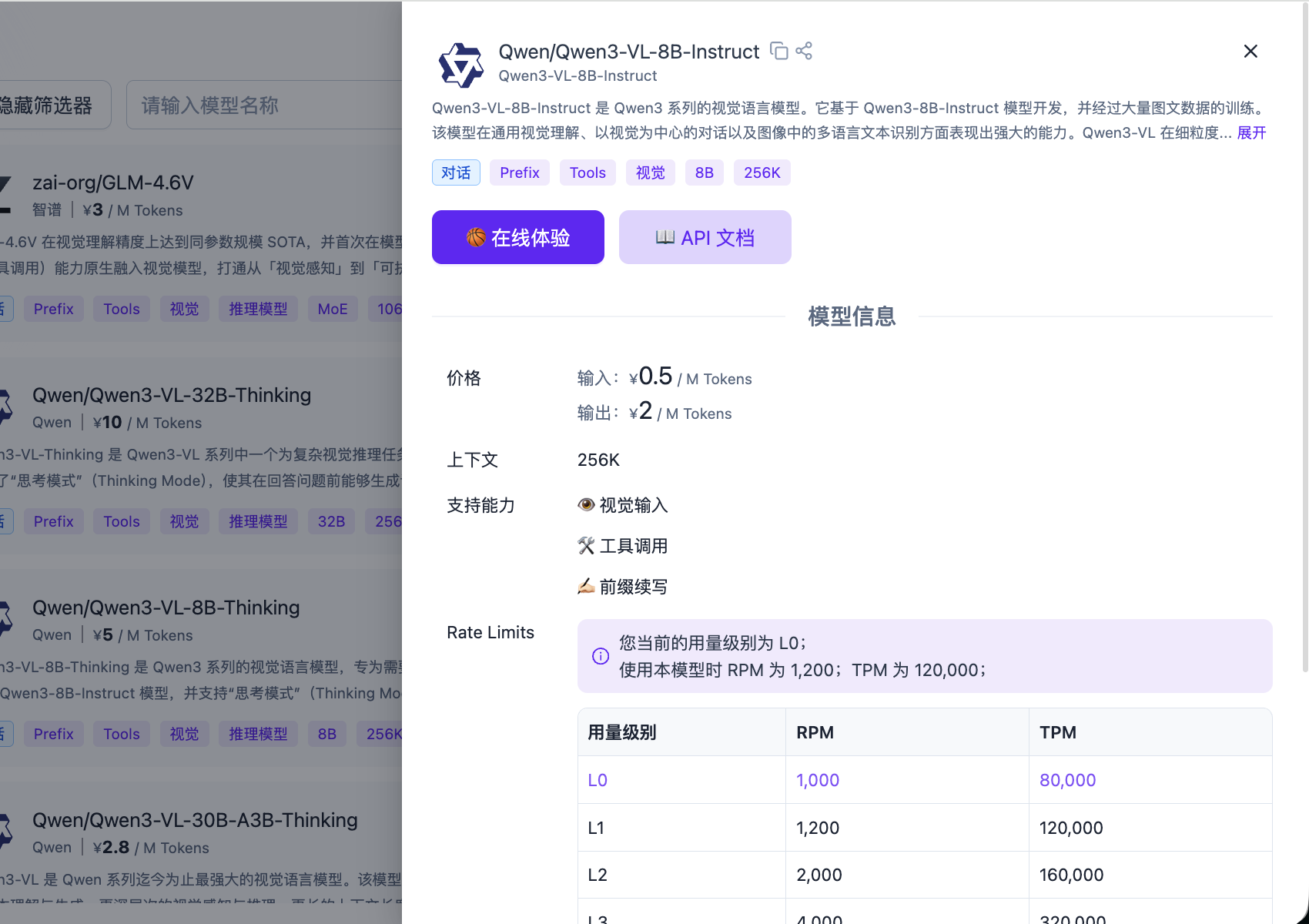
進入 SiliconFlow 平臺,在 API 金鑰中點選「新建 API 金鑰」,建立一個新的 API Key。
你可以直接使用下面的程式碼作為參考程式碼,和生成的 API Key 一起,傳送給 AI IDE ,進行功能整合。
圖片轉文字參考程式碼
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
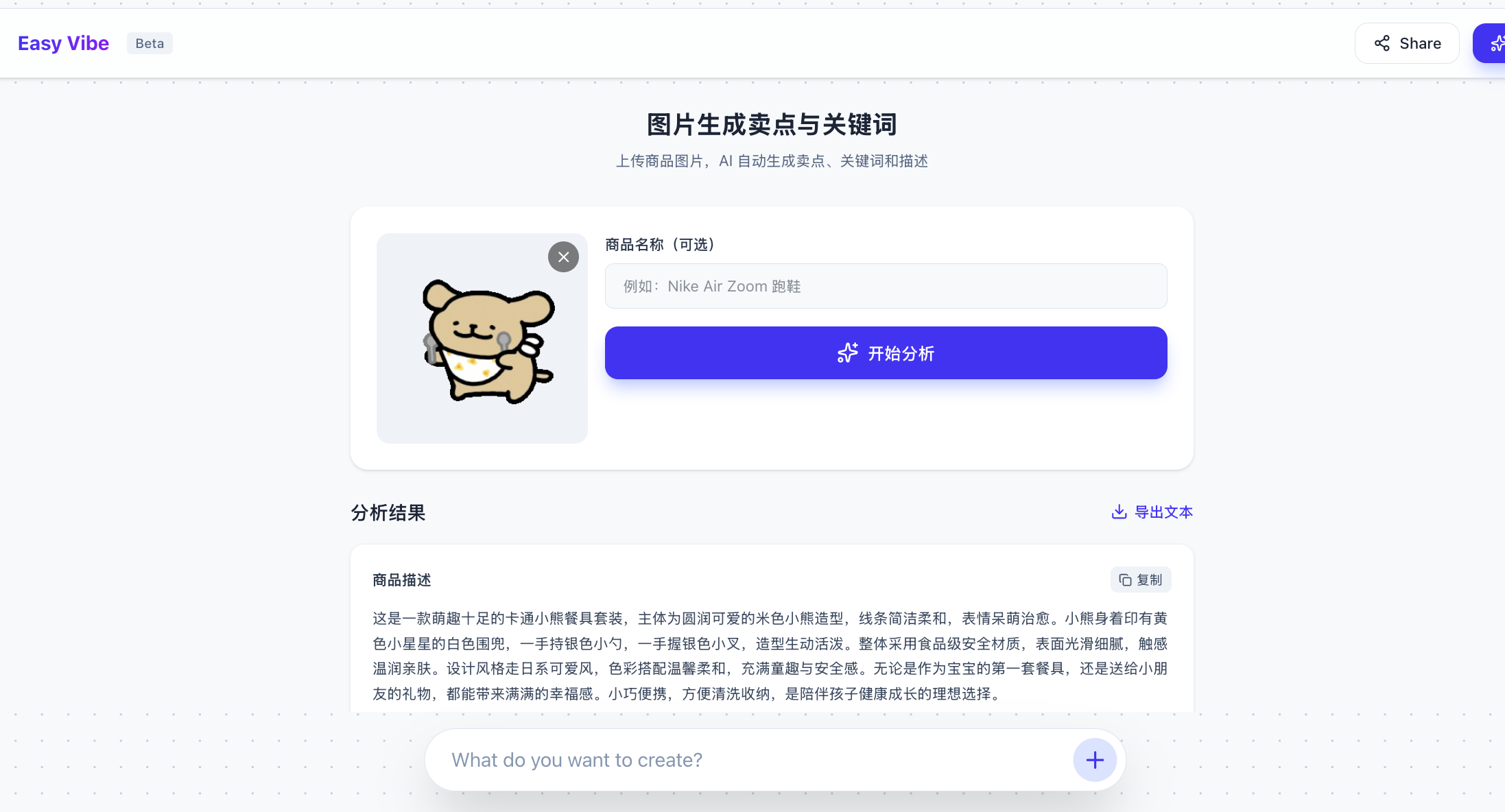
caption = caption_image(image_path)在這個場景中,我們直接嘗試讓 AI IDE 幫我們實現將上傳的圖片,自動生成電商賣點文字、關鍵詞的功能,如下所示:
基於下面的圖生文介面 API ,幫我們實現將上傳的圖片,自動生成電商賣點文字、關鍵詞的功能
<此處省略程式碼,你需要自行貼上金鑰和參考程式碼>最後得到生成結果: 
4. 接入影象生成 API:Seedream 即夢
在前面的部分我們主要和文字相關的任務打交道,接下來我們將嘗試接入圖片生成的功能,支援從文字描述生成圖片,或者對圖片進行修改。
ℹ️ 原理延伸
如果你想了解更多原理相關的內容,請檢視附錄:影象生成入門。
瞭解更多:什麼是 Seedream 即夢?

也許你已經知道 Nano Banana(Google 開發),但你最好不要錯過 Seedream。Seedream 4.5 是位元組跳動打造的新一代影象創作模型。它將影象生成和影象編輯能力整合到一個統一的架構中。這使得它能夠靈活處理複雜的多模態任務,如基於知識的生成、複雜推理和參考一致性。此外,它的推理速度比前代產品快得多,並且可以生成解析度高達 4K 的令人驚歎的高畫質影象。


主要能力:
- 文生圖:用文字描述生成圖片,支援多種風格(寫實、卡通、水墨、賽博朋克等)
- 風格遷移:將一張圖片轉換成指定的藝術風格
- 影象變體:基於參考圖生成相似風格的新圖
- 解析度提升:增強圖片清晰度和細節
- 影象編輯:在現有圖片上進行編輯和修改,透過自然語言指令
為什麼選擇 Seedream?
- 國內網路穩定:國內訪問速度快,延遲低
- 效果優秀:在電商、素材場景下表現穩定可靠
- 中文最佳化:對中文提示詞理解更準確,適合國內使用者
- 速度快:生成效率高,響應時間短
- 質量穩定:生成解析度高達 4K 的高畫質影象
典型應用場景:
- 電商:生成主圖、詳情頁配圖、促銷海報
- 社交媒體:生成頭像、表情包、配圖
- 設計:快速出概念圖、素材圖、背景圖
- 營銷:製作廣告圖、活動 banner、節日海報
與 Qwen3 VL 的配合:
這兩個 API 可以串聯使用:先用 Qwen3 VL 分析參考圖,理解畫面內容;再用 Seedream 基於分析參考圖的提示詞內容生成新圖片。
你可能在抖音、B 站或 YouTube 上看到的很多 "AI 海報 / AI 主圖 / AI 角色圖",本質上都是用到這部分介紹的技術。你需要做的事情很簡單:把使用者輸入整理成一句話,請求圖片 API,然後把返回的圖片展示出來。此時用到的模型叫做圖片生成 / 圖片編輯模型。
我們將逐步演示如何將 Seedream API 整合到你的專案中(透過 AI IDE 輔助完成)。
訪問首頁頁面後,點選登入。
登入後,找到頁面右上角的充值選項。
進行充值需要實名認證。
認證成功後,你可以充值 1 元用於測試。
返回初始介面並點選 API 訪問。
首先,建立一個 API key,然後點選選擇選項。
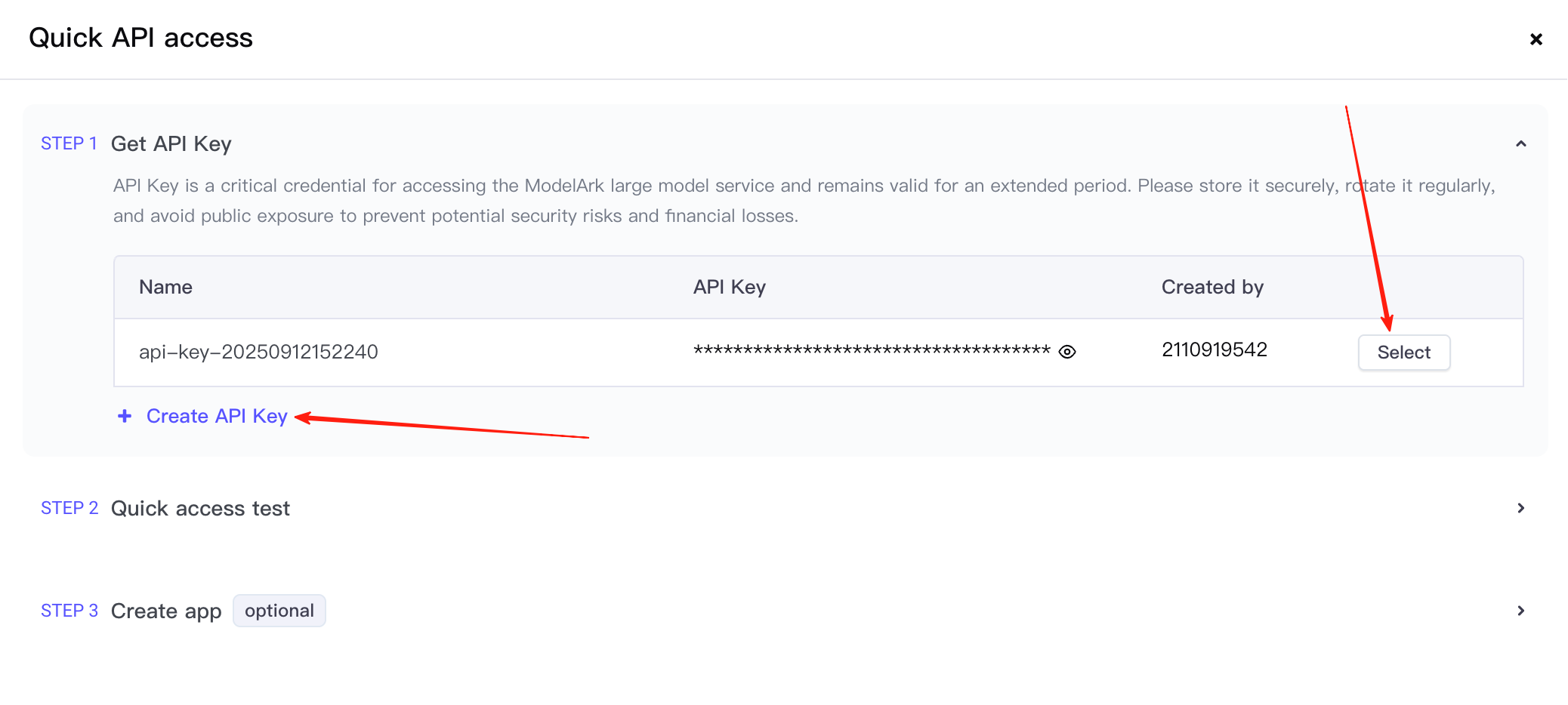
這將帶你進入第 2 步。在這裡,你需要確認呼叫的服務是 Seedream 4.5,並複製提供的呼叫示例。(此處截圖時間比較早起,故而模型版本仍然是 4.0)
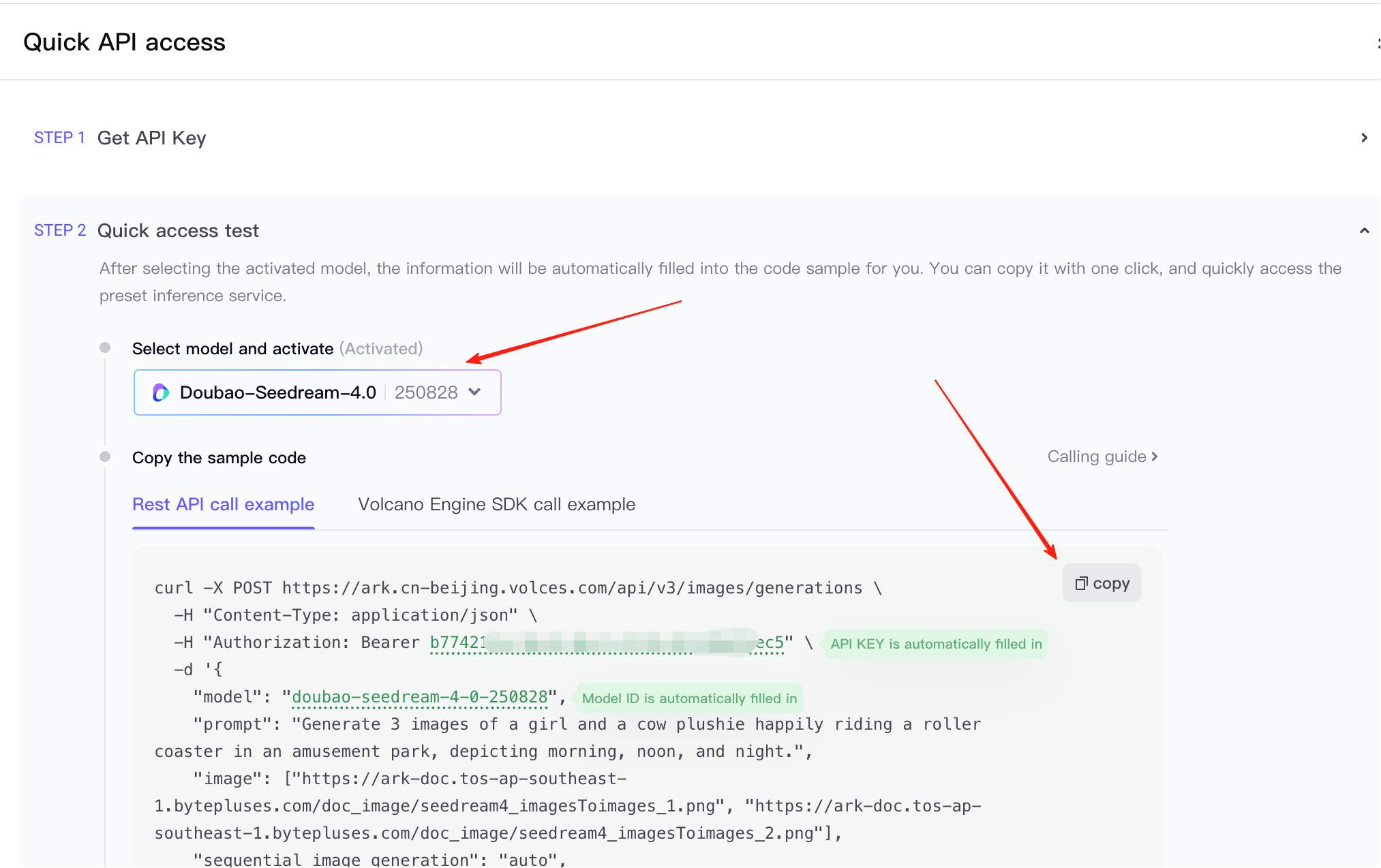
準備好 API Key 和呼叫示例後,你可以直接將它們貼上到 AI IDE 中,讓它生成前端互動演示或把能力接入現有原型。注意到在圖片中可以選擇是文生圖還是多張圖片生成單張圖,你需要根據當前的需求進行選擇參考程式碼。
⚠️ 重要提示
這裡的預設示例相對複雜。記得禁用 "新增水印" 和 "流式響應",以確保不生成水印且不會發生請求失敗。
由於我們之後使用的是參考圖生成模式,我們先去的是多張圖生成單張圖的功能。參考程式碼複製如下:
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "將圖1的服裝換為圖2的服裝",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'有了影象參考程式碼後,我們讓 AI IDE 支援電商中常用的影象任務功能:
請你基於下面 API,幫我實現這個工程中,電商業務的常見功能(例如海報生成、抖音電商首圖生成等等)
<此處貼上 API KEY以及影象編輯程式碼>實現效果如下:
值得注意的是,由於生成圖片可能會經常遇到一些奇怪的問題,建議你需要讓 AI IDE 能夠顯示完整的報錯資訊,方便複製貼上進行修改(否則可能會反覆顯示生成失敗但是不知道為什麼),例如你可以說:
不要只顯示圖片生成失敗,每次都顯示完整的失敗原因,比如圖片不匹配、請求錯誤、超時等等!有時候修改後更新並不會應用到網頁中,如果你發現修改後網頁一直還在報錯(反覆多次),也可以試試直接對 AI IDE 說:請你重啟這個專案。
在電商的業務中,我們可能會想讓使用者上傳的衣服能夠自動穿在人物身上,又或者是自動生成商品吸引人的售賣圖、海報。這裡我們嘗試的提示詞是讓它生成一個電商海報:
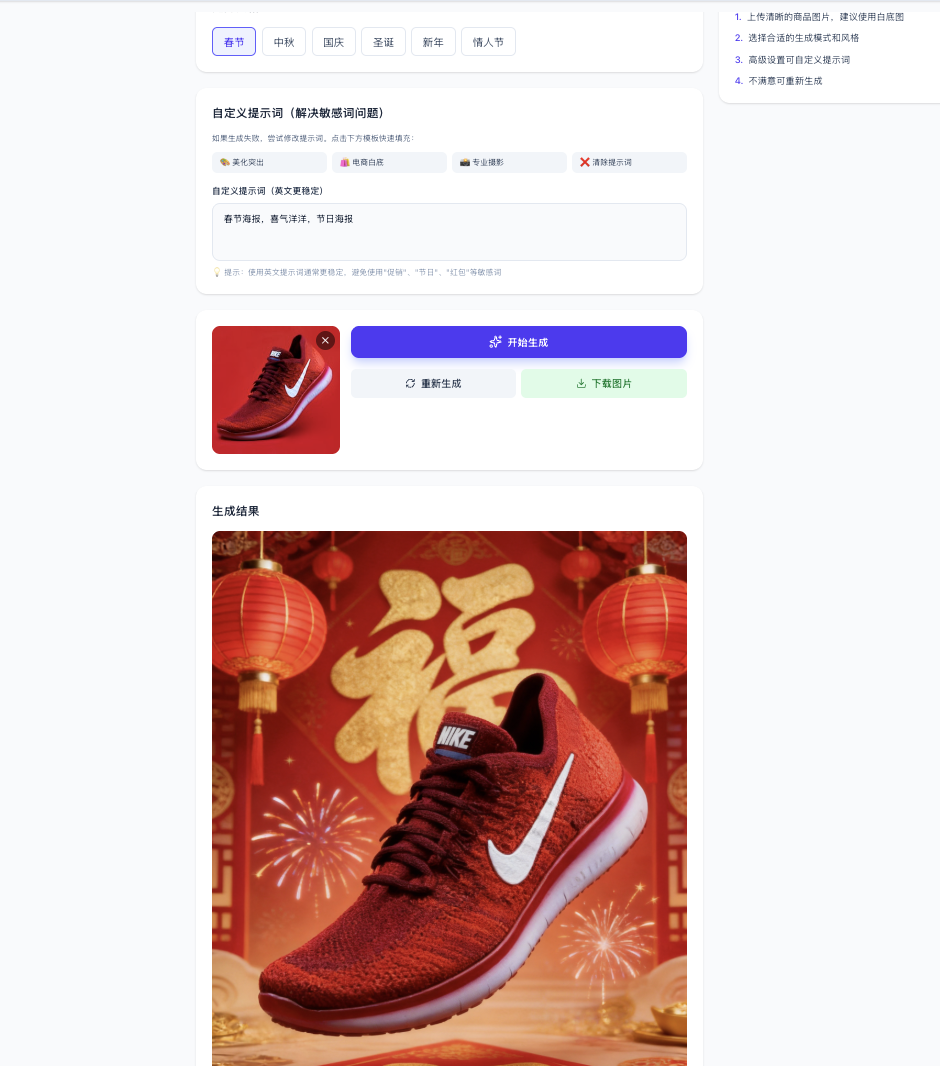
你可以根據自己想象的業務場景,使用文生圖或者圖生圖 API 實現不同的功能。
更多不同影象服務選型
下面給出其他選擇。建議你先跑通 Qwen 生圖的結果,再根據效果與成本使用下列服務做替換(根據實際使用感受選擇)。
Recraft 整合
如果你的原型更偏“設計生產”(例如生成品牌風格插畫、營銷海報、向量風格素材),Recraft 往往會更順手。接入方式與上一節完全一致:拿到 Key + 找到官方示例 + 讓 AI IDE 把示例落到你的按鈕/頁面裡。
瞭解更多:什麼是 Recraft?
Recraft 是一款面向設計師、插畫師和營銷人員的 AI 工具——於 2022 年在美國成立,總部位於倫敦。它幫助生成/迭代視覺效果(影象、向量藝術、3D 圖形),具有高質量輸出(任何文字大小/長度)、精確元素定位和品牌一致性設計等優勢。受到 200 個國家/地區 300 多萬使用者(包括奧美、Netflix)的信任,並已建立了 3.5 億多張影象,其團隊旨在使其成為必備的設計師工具,確保創作者能夠控制他們的 AI 輔助工作流程。


首先,我們仍然需要找到 API 入口以獲取 API Key。
由於這裡沒有提供免費額度,我們需要自己充值 1,000 積分。這個網站支援支付寶和微信支付,所以很容易獲得 1,000 積分(注意:不要充值超過必要的金額)。

之後,我們仍然遵循同樣的方法:去官方文件找到相應的請求示例:
Qwen Image / Qwen Image Edit 整合
如果你希望使用更簡單的方式接入影象生成服務,可以考慮 Qwen Image(通義萬相)。思路同樣不變:把它當成一個"圖片生成 API",接到你的原型按鈕上即可。
瞭解更多:Qwen Image / Qwen Image Edit 是什麼?
Qwen Image(也稱通義萬相)是阿里雲通義團隊推出的影象生成模型系列,主要包括兩大模型:
1. Qwen Image——文生圖(Text-to-Image)模型
根據文字描述生成全新的圖片。你輸入一段提示詞,模型會理解你的意圖並生成符合描述的影象。

主要能力:
- 文生圖:用文字描述生成圖片,支援多種風格(寫實、卡通、水墨、賽博朋克等)
- 風格遷移:將一張圖片轉換成指定的藝術風格
- 影象變體:基於參考圖生成相似風格的新圖
- 解析度提升:增強圖片清晰度和細節
2. Qwen Image Edit——圖生圖(Image-to-Image)模型
在現有圖片上進行編輯和修改。透過自然語言指令,讓模型理解你的修改意圖並生成結果。
主要能力:
- 區域性替換:替換圖片中的某個物體或人物(如「把背景換成海邊」)
- 元素移除:去除圖片中不需要的元素
- 風格轉換:給圖片新增濾鏡或藝術效果
- 影象擴充套件:擴充套件圖片邊界,生成新內容
- 智慧修圖:自動美化、調整光影、修復瑕疵



為什麼選擇 Qwen Image 系列?
- 中文最佳化:對中文提示詞理解更準確,適合國內使用者
- 成本低:相比國際競品,價格更實惠
- 速度快:生成效率高,響應時間短
- 質量穩定:在電商、素材場景下表現穩定可靠
- 風格多樣:支援多種藝術風格和創意效果
典型應用場景:
- 電商:生成主圖、詳情頁配圖、促銷海報
- 社交媒體:生成頭像、表情包、配圖
- 設計:快速出概念圖、素材圖、背景圖
- 營銷:製作廣告圖、活動 banner、節日海報
檢視 SiliconFlow 的官網。左側有一個"Playground"部分,你可以在不進行 API 呼叫的情況下試用不同的模型。在網頁頂部有一個"Filters"按鈕;點選它可以篩選右側的模型列表。
如果你選擇"Image",你將只看到當前支援的所有文生圖模型。在這種情況下,我們將使用 Qwen/Qwen-Image。
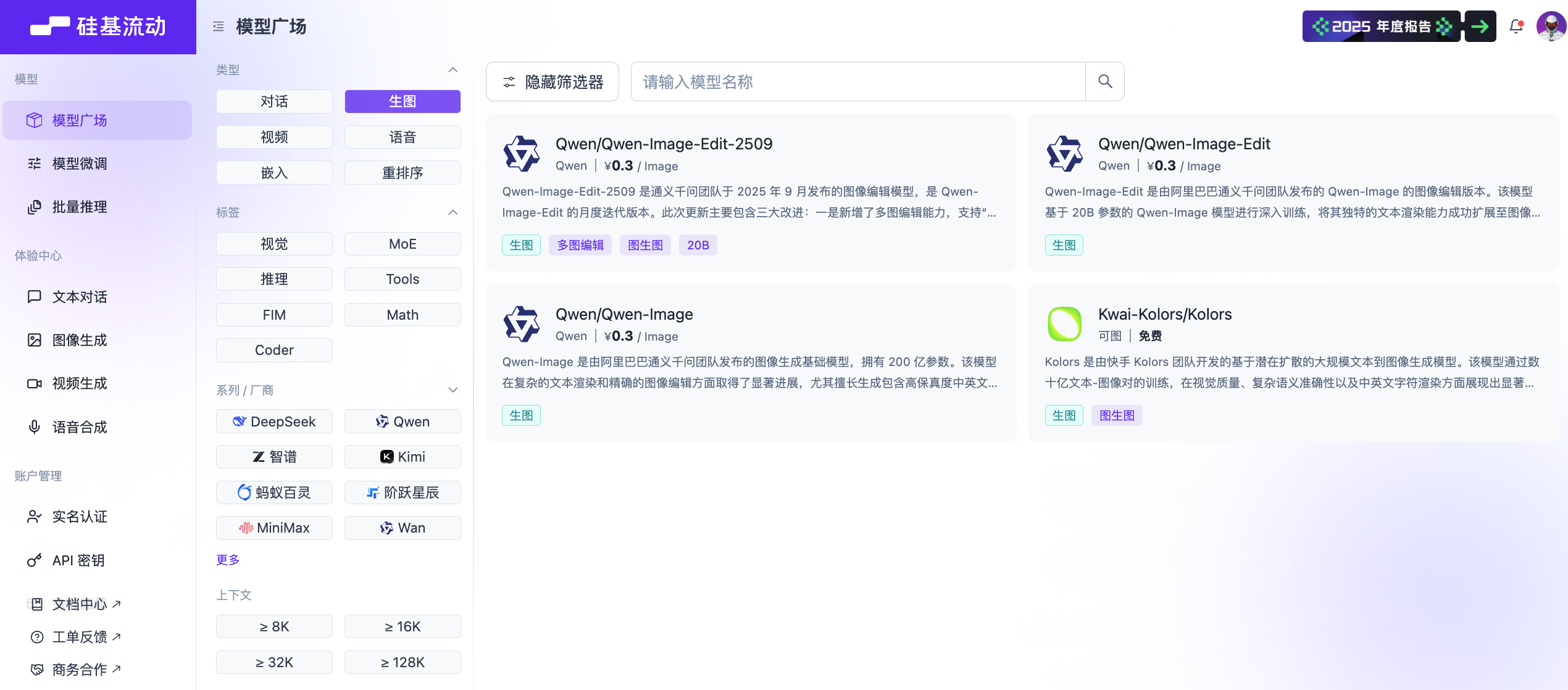
一切設定好後,我們需要參考相應的影象生成 API 文件。你可以在官方文件頁面找到任何標記為"API Reference"的部分。點選它,然後導航到影象生成的 API 部分並找到相關的請求示例。
你可以把下列請求示例和 API KEY 一起發給 AI IDE, 即可實現影象生成的功能。
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'這裡的模型可以使用 Qwen/Qwen-Image 或者 Qwen/Qwen-Image-Edit-2509。
影象編輯參考程式碼
複製下列程式碼和 key,一起傳送給 AI IDE:
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "讓天空變成傍晚,有月亮和星星,夢幻風格"
negative_prompt: str = "模糊, 低質量, 扭曲"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")附錄:如何找到“當前更強”的 AI 模型
文字模型(也常被叫作“大語言模型”)的發展速度非常快,我們總是需要確保我們用的是表現更好的模型之一。透過以下兩個網站,你可以很方便地看到“現在大家常用、評價也更好的模型”。
一般來說,這類網站可以理解為 “模型競技場”:它會把兩個模型的輸出放在一起,你投票選你更喜歡的那個。票數高的模型,通常意味著更多人覺得它“更好用”。
此外,你偶爾可能會在這些大模型競技場中看到神祕的匿名模型(“Unknown Model”)。這通常意味著:有人把“內部測試模型”悄悄放進來做盲測,你可能有機會提前體驗到更強的能力。
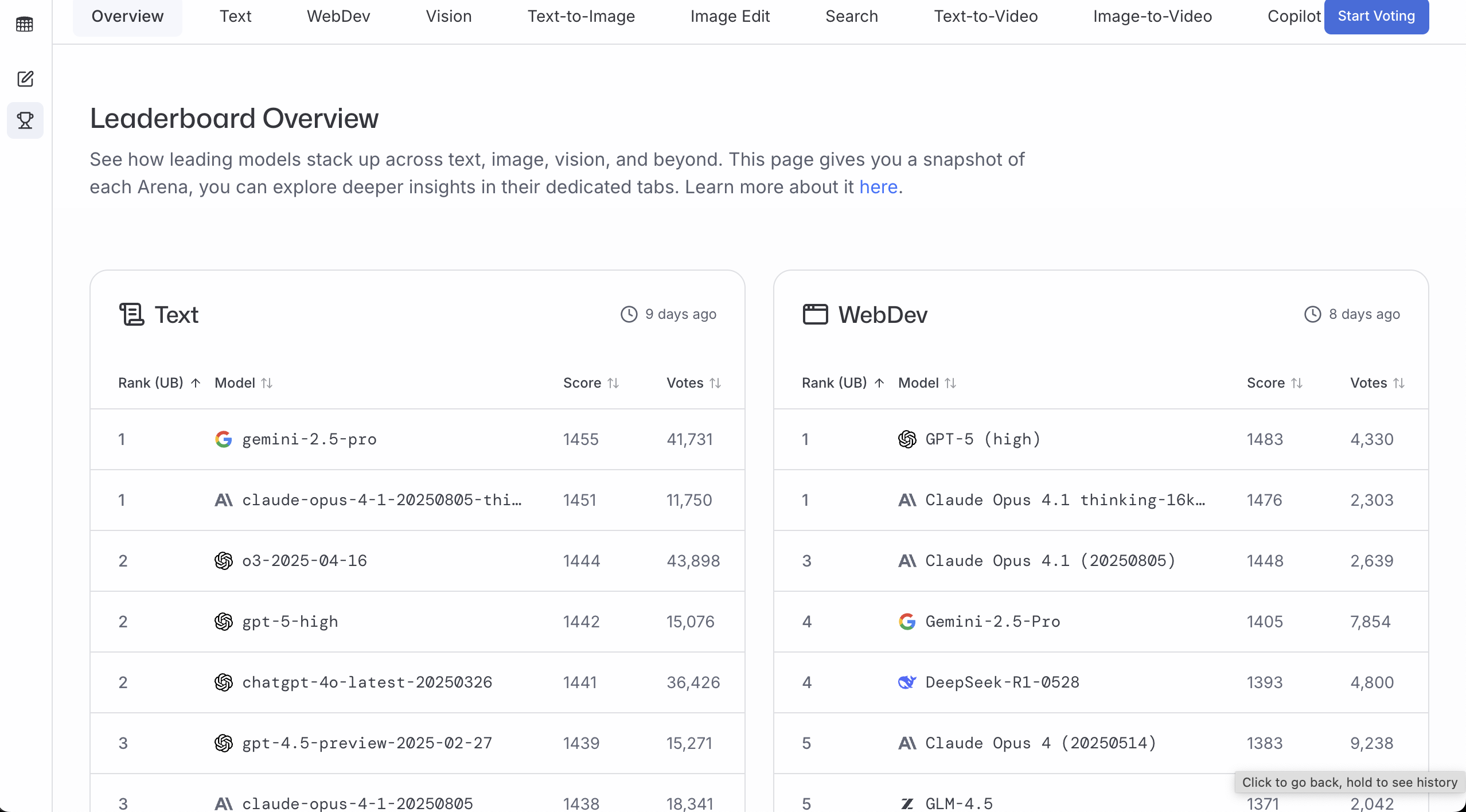
LMArena
LMArena 更適合用來判斷“多數人更偏好哪個模型的回答”。投票越多、分數越高,通常意味著它在真實使用場景裡更穩。
一個簡單的用法是:
- 直接看排行榜(Leaderboard)
- 先選一個你要做的方向(例如通用對話 / 程式設計 / 視覺)
- 選 Top 3 裡你能用的那個(能訪問、價格能接受、延遲能接受)
Artificial Analysis
網站:https://artificialanalysis.ai/
Artificial Analysis 更適合把“效果 / 價格 / 速度”放在同一張表裡對比,你可以把它當作模型選型的參數列。
常用的用法是:
- 找到你關心的模型類別(文字 / 生圖等)
- 看質量指標(Quality)+ 價格(Price)+ 延遲/吞吐(Latency/Throughput)
- 選一個“綜合價效比”最符合你產品的
✅ 建議
不要憑感覺爭論“哪個更強”。更可靠的做法是:用同一組輸入同時測試 2~3 個模型,再結合榜單與價格做決定。
總結
在接入各類 AI 服務時,不必把 API 想象得太複雜。把握住以下幾個核心概念,基本就能應對大多數場景:
API 的本質是通訊橋樑。它做的事情很簡單:把你的請求傳送出去,再把模型的響應帶回來。你不需要關心背後發生了什麼,只需要正確地組織請求格式。
SDK 是對 API 的封裝。如果說 API 是 raw 介面,SDK 就是一套現成的工具箱——它把請求籤名、錯誤處理、引數校驗這些繁瑣的細節都替你做好了。日常開發中,優先選擇 SDK 而不是直接調 API,能省去不少麻煩。
閱讀文件時,盯住三樣東西就夠了:服務地址(endpoint)、身份憑證(API key)以及呼叫引數怎麼填。把這三點弄清楚,調通只是時間問題。
剩下的工作,IDE 和現代化的開發工具會幫你完成。專注於你的業務邏輯,底層呼叫的事交給這些成熟的 SDK 和工具鏈。
5. 📚 作業:整合你的第一個 AI 能力
參考本節課的提示詞和內容,完成一次完整閉環:
- 完整閉環實踐
- 選擇並接入一個 AI 服務(LLM / 文生圖 / 圖生圖)→ 實現前後端互動 → 整合到你的原型中
- 成果分享
- 截圖你的功能頁面分享給大家看
- 思考題
- 為下一節"完整專案實踐"預留空間,提前思考:你打算如何把這些 AI 能力組合起來,做出什麼有意思的功能?
下一步
在下一節中,我們將把這些分散的 AI 能力串聯起來,結合實際業務場景做一個完整的產品:
- 把內容策劃、商品上架、資料分析等環節串聯成一條完整的業務流程
- 將本節課學到的 AI 能力(LLM 文案生成、文生圖、影象編輯等)嵌入到實際業務節點中
- 實現一個真正可用的"電商 AI 工作臺",而不是孤立的 demo