المبتدئ 4: ضخ قدرات الذكاء الاصطناعي في النموذج الأولي
دليل الفصل
1. المفاهيم الأساسية لـ API
كما ذكرنا سابقًا، هدفنا هو "إدخال قدرات الذكاء الاصطناعي"، بحيث لا يظل النموذج الأولي مجرد عرض ثابت، بل أداة قادرة على استدعاء خدمات ذكاء اصطناعي حقيقية. لتحقيق ذلك، يكمن المفتاح في فهم واستخدام API (واجهة برمجة التطبيقات).
API هو مفهوم تجريدي مهم في مجال الحوسبة، ويمكننا فهمه ببساطة على أنه: "ترسل سؤالاً بالتنسيق الذي يطلبه الطرف الآخر، ويقوم الطرف الآخر بالرد بنتيجة بنفس التنسيق".
- ما ترسله: يتضمن عادةً "مفتاح (API Key)" و"ما تريد توليده"
- ما يردونه عليك: إذا نجح الطلب يعطيك النتيجة؛ وإذا فشل سيخبرك بالسبب (مثل "المفتاح غير صحيح" أو "الرصيد غير كافٍ" أو "المعلمات خاطئة")
على وجه التحديد، تحتاج إلى إتقان العناصر الأساسية التالية:
- API Key: "تصريح مرورك"، وهو أيضًا "مفتاح محفظتك". إذا حصل عليه شخص آخر، يمكنه استدعاء الواجهة نيابة عنك وتكبد رسوم.
- Endpoint (مسار الواجهة): المسار المحدد لطلب API، والذي يخبر الخادم بالوظيفة التي تريد الوصول إليها. يتكون عنوان الطلب الكامل عادةً من "الرابط الأساسي + مسار Endpoint". على سبيل المثال:
- توليد النص: الرابط الأساسي (
https://api.service.com) + Endpoint (/v1/chat/completions) = الرابط الكاملhttps://api.service.com/v1/chat/completions - توليد الصور: الرابط الأساسي (
https://api.service.com) + Endpoint (/v1/images/generations) = الرابط الكاملhttps://api.service.com/v1/images/generations
- توليد النص: الرابط الأساسي (
- الاستدعاء/الطلب: عملية إرسال مهمة إلى خدمة الذكاء الاصطناعي والحصول على نتيجة
- محتوى الطلب: المحتوى المحدد الذي ترسله إلى الذكاء الاصطناعي، مثل موضوع المقالة التي تريد من الذكاء الاصطناعي كتابتها، أو وصف الصورة التي تريد توليدها، إلخ.
- نتيجة الاستجابة: المحتوى الذي يعيده الذكاء الاصطناعي بعد الانتهاء من المعالجة، مثل المقالة أو الصور المولدة، إلخ.
- معالجة الأخطاء: عند حدوث مشاكل (مثل خطأ في مفتاح API، أو طلبات متكررة جدًا، إلخ)، معرفة كيفية التحقيق فيها وحلها.
ℹ️ ما هي API
للحصول على شرح أعمق لواجهة برمجة التطبيقات (API)، يرجى مراجعة الملحق: مقدمة في API.
🔐 ملاحظات أمان API
مفتاح API هو "تصريح المرور" لطلب خدمات الذكاء الاصطناعي، وهو عبارة عن سلسلة نصية سرية تُستخدم للمصادقة والفوترة.
نظرًا لأن مفتاح API مرتبط مباشرة بحسابك وتكاليفك، يجب الانتباه جيدًا إلى:
- عدم مشاركته أبدًا في محادثات جماعية، أو التقاط لقطة شاشة وتحميلها على الإنترنت، أو نشره في منتديات عامة
- عدم كتابته بشكل ثابت في الكود (Hard-coding) ثم رفعه إلى مستودع Git (خاصة المستودعات العامة)
- إذا اشتبهت في تسريب المفتاح، قم بتغييره فورًا
سنقوم في المحتوى التالي بلصق مفتاح API مباشرة في بيئة تطوير الذكاء الاصطناعي (AI IDE) للعمل عليه، لا تفعل ذلك في المشاريع الحقيقية!!، وبما أننا نتدرب يمكننا فعل ذلك. (عندما تصبح أكثر مهارة، ستتمكن من جعل الذكاء الاصطناعي ينشئ ملف تكوين، وتضع مفتاح API في ملف التكوين فقط)
2. ربط واجهة برمجة توليد النصوص: DeepSeek
على الرغم من أن API تتضمن هذه المفاهيم التقنية، إلا أنه في مرحلة تطوير النموذج الأولي، يمكن أن تكون العملية الفعلية بسيطة وفعالة للغاية. الفكرة الأساسية هي:
ابحث عن المثال الرسمي، واحصل على مفتاح API، ودع بيئة تطوير الذكاء الاصطناعي (AI IDE) تساعدك في ربطه بالزر.
بعد إتقان هذه المفاهيم، ستجد أنه سواء كان ربط نموذج نصي أو نموذج صوري، فإن العملية الأساسية هي نفسها: عندما ينقر المستخدم على الزر، تقوم الواجهة الأمامية بتجميع المدخلات وإرسال طلب؛ وبعد أن تعيد الواجهة النتيجة، يتم عرضها على الصفحة. بعد ذلك، سنتحقق من ذلك من خلال العمل الفعلي.
في قسم 1.2 بناء النموذج الأولي عمليًا، قمت بالفعل ببناء نموذج أولي تفاعلي. ما سنقوم به بعد ذلك هو تحويل "الوظائف التي تبدو وكأنها ذكاء اصطناعي" في النموذج الأولي إلى قدرات قابلة للاستخدام فعليًا: عندما ينقر المستخدم على الزر، يرسل النموذج الأولي طلبًا إلى خدمة ذكاء اصطناعي خارجية، ويعرض النص المُعاد.
ℹ️ امتداد للمبادئ
إذا كنت ترغب في معرفة المزيد عن المبادئ ذات الصلة، يرجى مراجعة الملحق: مقدمة في النماذج اللغوية الكبيرة (LLM).
اعرف المزيد: ما هو DeepSeek؟
شركة هانغتشو ديب سيك لأبحاث تكنولوجيا الذكاء الاصطناعي الأساسية المحدودة (Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.)، والمعروفة باسمها التجاري DeepSeek، هي شركة صينية للذكاء الاصطناعي (AI) تطوّر نماذج لغوية كبيرة (LLMs). يقع المقر الرئيسي لـ DeepSeek في هانغتشو بمقاطعة تشجيانغ، وهي مملوكة ومموّلة من صندوق التحوط الصيني High-Flyer. تأسست DeepSeek في يوليو 2023 على يد ليانغ وين فنغ، المؤسس المشارك لـ High-Flyer، والذي يشغل أيضًا منصب الرئيس التنفيذي للشركتين. أطلقت الشركة في يناير 2025 روبوت الدردشة الذي يحمل نفس الاسم ونموذجها DeepSeek-R1.
دعونا نلقي نظرة على مقارنة أداء DeepSeek مع النماذج الرائدة الأخرى في ترتيب معيار GPQA. الجدير بالذكر أن DeepSeek هو نموذج مفتوح المصدر (يمكن للجميع تنزيل النموذج من الإنترنت)، بينما النماذج الشائعة الأخرى مثل Grok و Google Gemini و ChatGPT هي نماذج مغلقة المصدر. كما نرى، اقترب DeepSeek بشكل كبير من مستوى النماذج من الدرجة الأولى.
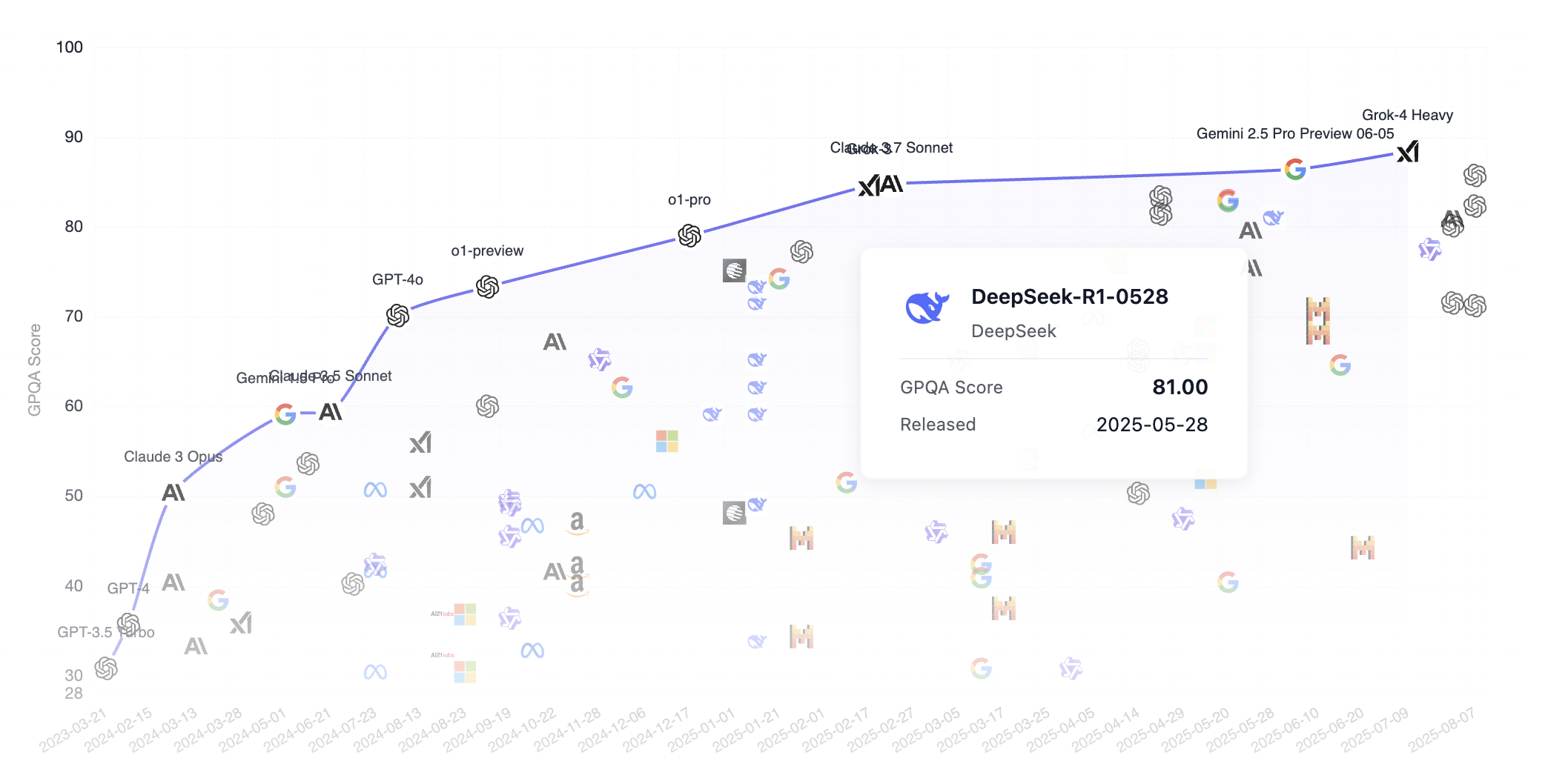
GPQA هو اختصار لـ "Graduate-Level Google-Proof Q&A Benchmark"، وهو معيار بمستوى الدراسات العليا مخصص لمهام الإجابة على الأسئلة العلمية. فيما يلي مقدمة مفصلة.
يحتوي GPQA على 448 سؤالًا من أسئلة الاختيار من متعدد، تغطي مجالات فرعية في علم الأحياء والفيزياء والكيمياء، مثل ميكانيكا الكم، والكيمياء العضوية، وعلم الأحياء الجزيئي، وغيرها. تمت كتابة هذه الأسئلة بواسطة 61 خبيرًا يحملون درجة الدكتوراه أو يدرسون للحصول عليها، وخضعت لعملية تحقق صارمة.
اتبع هذه الخطوات الثلاث لتحقيق تكامل سريع لواجهة برمجة التطبيقات (API) الخاصة بتوليد النصوص باستخدام النماذج الكبيرة:
- إنشاء API Key على منصة DeepSeek
- العثور على مثال لتوليد النصوص في وثائق DeepSeek (عادةً ما يكون هناك كود جاهز يمكن نسخه مباشرة)
- افتح AI IDE، والصق API Key + المثال الرسمي بداخله، وأخبر الذكاء الاصطناعي بالوظيفة التي تريد تنفيذها:
ساعدني في ربط واجهة برمجة التطبيقات (API) الخاصة بهذا النموذج الكبير، لدعم مهمة توليد النصوص لهذا التطبيق
بعد ذلك سنقوم بعرض توضيحي، يمكنك متابعة الخطوات وتجربة العملية الكاملة. أولاً، قم بتسجيل حساب في DeepSeek وإنشاء API Key، وقم بشحن رصيد صغير للتحقق.
انقر على "API KEYS" وابحث عن "create new API key" في أسفل الشاشة. ستحصل في النهاية على مفتاح API يشبه sk-8573341c39fc44315aadc071c53rh7d2.
بمجرد حصولك على المفتاح، ستكون لديك الصلاحية لاستدعاء النموذج.
في هذه المرحلة، يمكنك قراءة وثائق API مباشرةً، والتي توفر عادةً أمثلة للاستدعاء باستخدام curl أو Python.
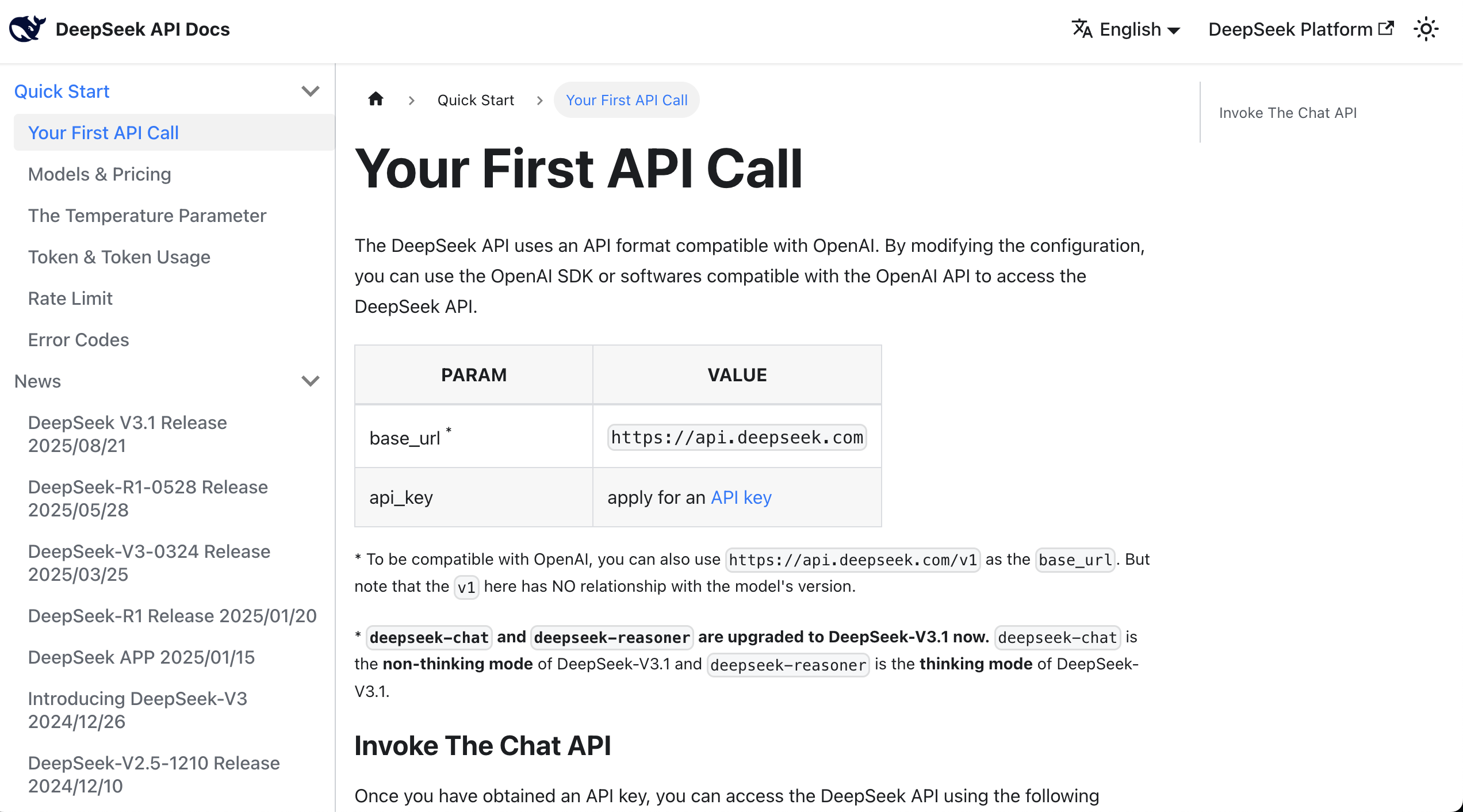
بعد العثور على المثال، يمكنك نسخ جميع المحتويات من الوثائق بالإضافة إلى المفتاح إلى مربع حوار AI IDE، واطلب منه مساعدتك في دمج النموذج اللغوي الكبير في النموذج الأولي الذي قمت بتطويره مسبقًا.
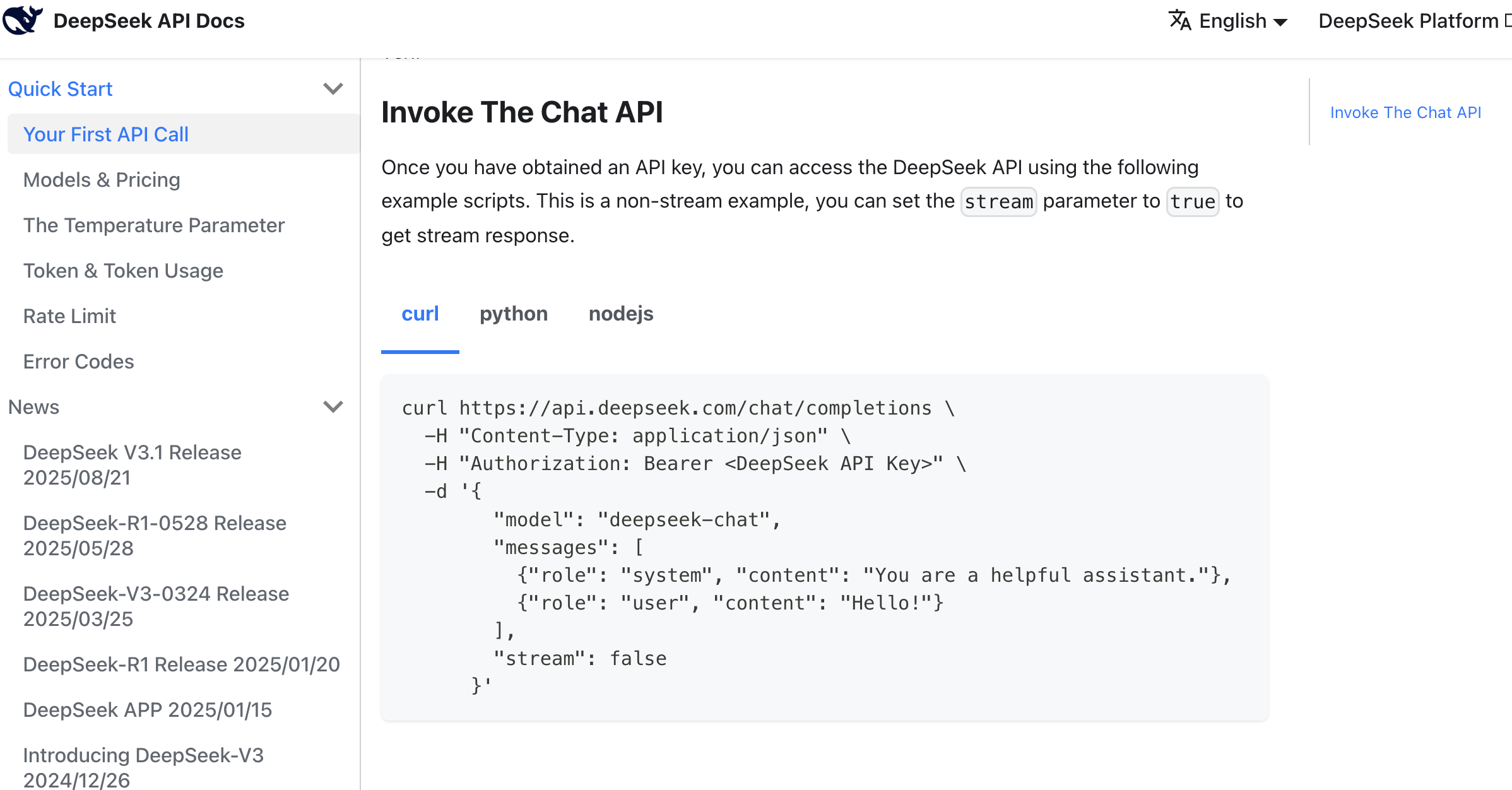
استخدم الرسالة المرجعية التالية:
ارجع إلى طريقة الاستدعاء هذه وساعدني في دعم وظيفة توليد النصوص التسويقية، يمكنها توليد نصوص تسويقية لمنصة Douyin بناءً على معلومات المنتج عند النقر، بأنماط متعددة.
مفتاح API:sk-8573341c39aefa1efe
مرجع طلب API:
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'بعد فترة من توليد الأكواد بالذكاء الاصطناعي، يمكننا بسهولة الحصول على زر توليد النصوص المقابل لاختباره. إذا لم تتمكن من العثور على المدخل، يمكنك أن تطلب من AI IDE أن يخبرك من أي صفحة يمكنك الوصول إلى هذه الصفحة. وإذا لم تتمكن من العثور عليه حقًا، يمكنك أن تطلب من AI IDE إعادة البناء والتحسين مباشرة بناءً على أفكارك، للحصول على نتيجة توليد النصوص النهائية.
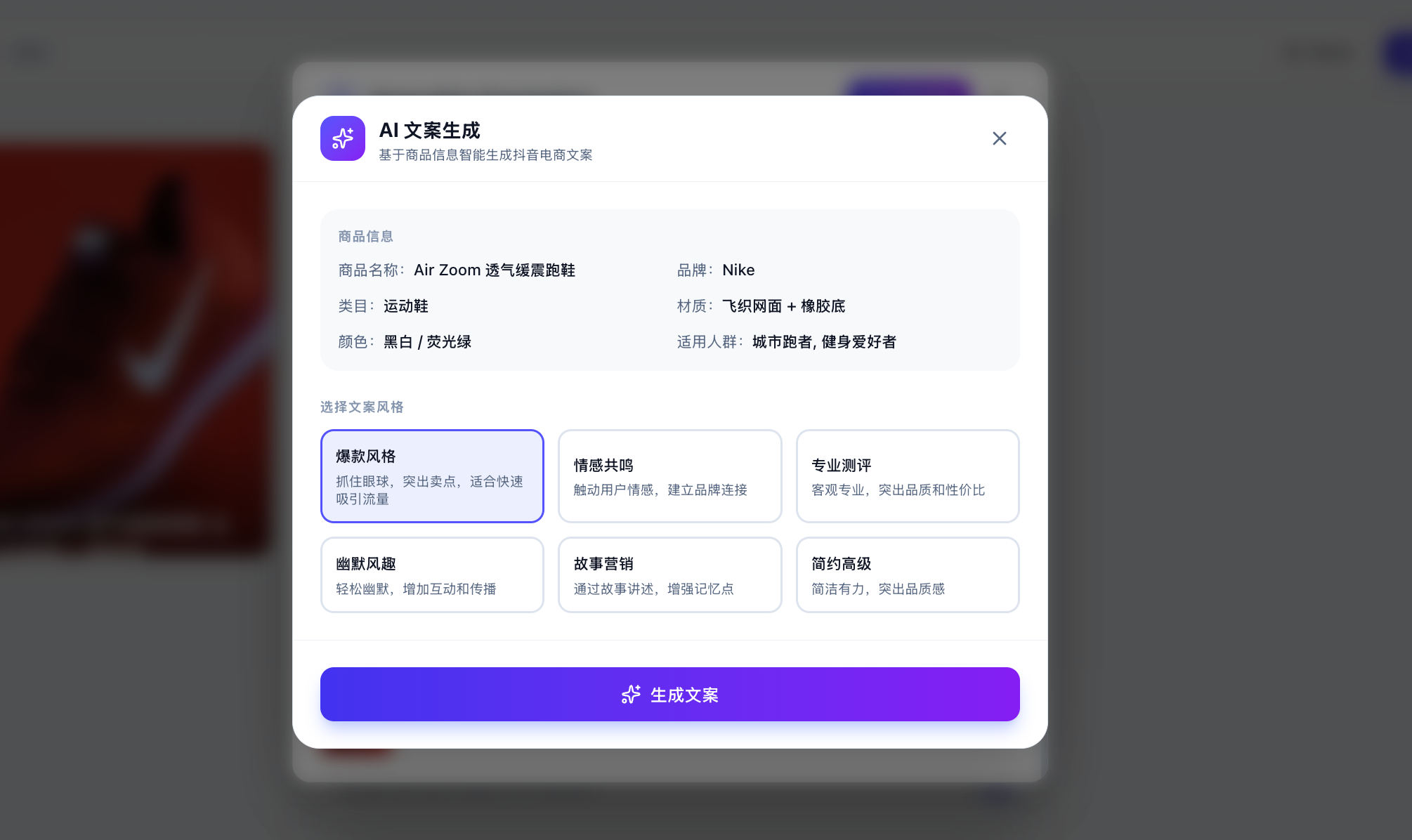
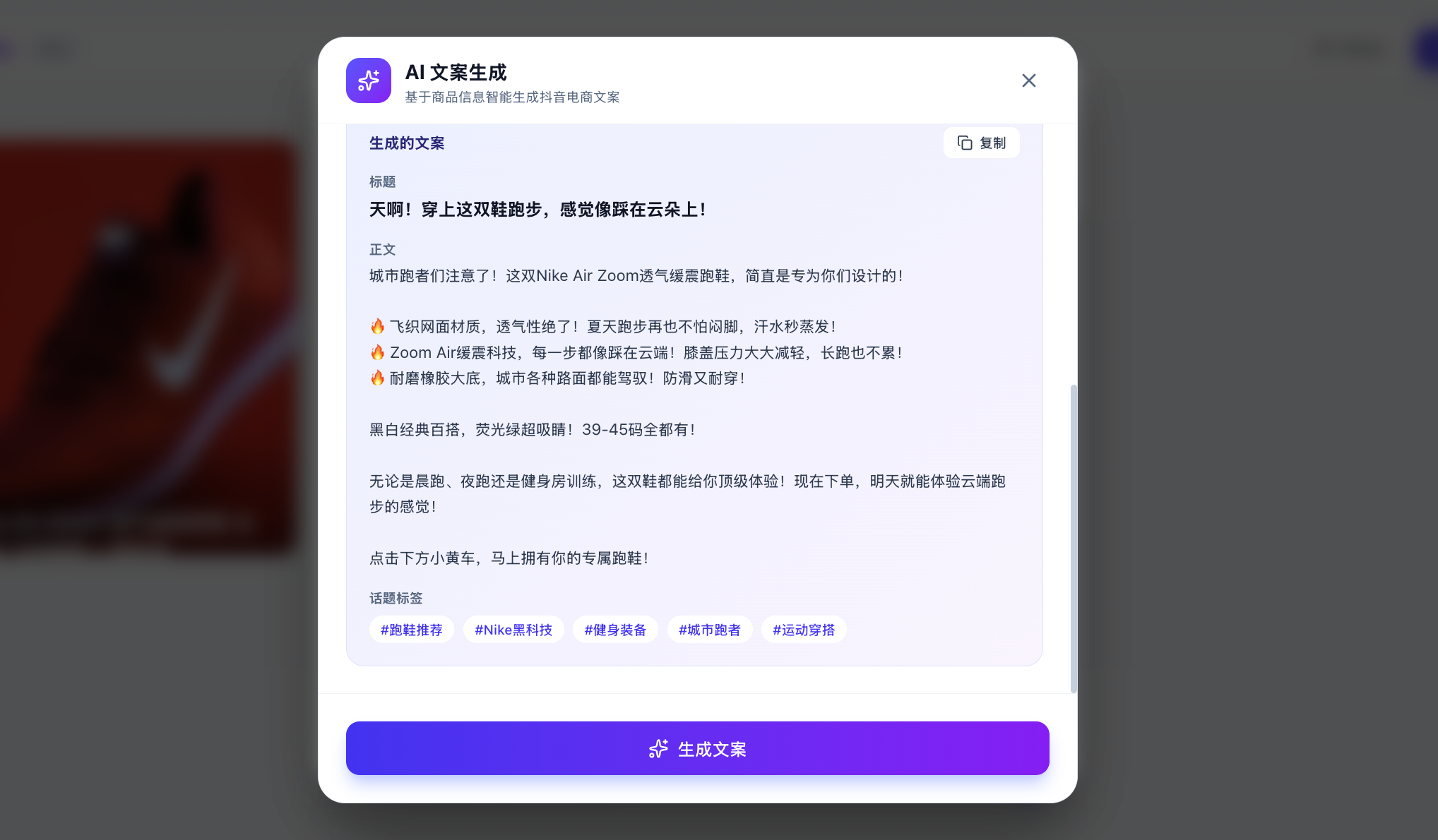
بالطبع، قد تتساءل هنا، كيف أعرف أنه تم استدعاء النموذج الكبير فعلًا بدلاً من مجرد استخدام ردود مبرمجة مسبقًا؟ يمكنك إدخال نصوص مخصصة، والسماح للنموذج الكبير بتوليد النصوص المقابلة بناءً على التحليل المخصص الذي تحدده فورًا.
إذا وجدت أن الردود مختلفة في كل مرة ومنطقية، يمكنك أن تطمئن إلى أن استدعاء API قد تم بشكل طبيعي لتوليد النصوص. يمكنك أيضًا التحقق من نجاح الاستدعاء في منصة إدارة استخدام API (على الرغم من أنه قد تحتاج إلى الانتظار بضع دقائق لتظهر).
المزيد من خيارات نماذج توليد النصوص
بالإضافة إلى DeepSeek، يمكنك أيضًا تجربة نماذج لغوية كبيرة أخرى. نظرًا لأن معظم النماذج توفر واجهة متوافقة مع OpenAI، فإن التبديل بينها سهل للغاية — كل ما عليك فعله هو تغيير API Key وعنوان URL الأساسي واسم النموذج.
تكامل MiniMax
اعرف المزيد: ما هو MiniMax؟
MiniMax هي شركة صينية للذكاء الاصطناعي، تكرس جهودها للبحث وتطوير تقنيات الذكاء الاصطناعي العام. أطلقت MiniMax سلسلة النموذج اللغوي الكبير MiniMax-M2.7 من تطويرها الخاص، والتي حققت أداءً ممتازًا في العديد من اختبارات المعايير، وتتميز بنسبة أداء إلى تكلفة عالية جدًا.
الخصائص الرئيسية لسلسلة MiniMax-M2.7:
- سياق طويل جدًا: يدعم نافذة سياق تصل إلى 204,800 رمز (tokens)، مما يجعله مناسبًا لمعالجة المستندات الطويلة والمحادثات متعددة الأدوار
- نسبة أداء إلى تكلفة عالية: بسعر تنافسي للغاية
- واجهة متوافقة مع OpenAI: يمكن استخدام OpenAI SDK مباشرة للاستدعاء، دون الحاجة لتعلم تنسيق API جديد
- نموذجان متاحان:
MiniMax-M2.7: النموذج الرائد، مناسب للمهام المعقدةMiniMax-M2.7-highspeed: الإصدار عالي السرعة، يحافظ على نفس الأداء ولكنه أسرع
طريقة التوصيل هي نفسها الخاصة بـ DeepSeek، وتتطلب ثلاث خطوات فقط:
- انتقل إلى منصة MiniMax المفتوحة لتسجيل حساب وإنشاء API Key
- ابحث عن مثال الاستدعاء في وثائق MiniMax
- انسخ API Key + المثال والصقهما في AI IDE
نظرًا لأن MiniMax توفر واجهة متوافقة مع OpenAI، يمكنك ببساطة نسخ مثال curl أدناه مع API Key الخاص بك، وإرسالهما إلى AI IDE لإجراء التكامل:
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.7",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'✅ نصيحة
تنسيق واجهة برمجة تطبيقات MiniMax متطابق تقريبًا مع DeepSeek (كلاهما يستخدم تنسيق OpenAI المتوافق)، لذلك إذا كنت قد دمجت DeepSeek بنجاح بالفعل، فإن التبديل إلى MiniMax يتطلب تعديل ثلاثة أشياء فقط:
- عنوان URL الأساسي: غيّره إلى
https://api.minimax.io/v1 - مفتاح API: استخدم مفتاح API الخاص بـ MiniMax
- اسم النموذج: غيّره إلى
MiniMax-M2.7أوMiniMax-M2.7-highspeed
لمزيد من المعلومات، يرجى الرجوع إلى وثائق واجهة MiniMax المتوافقة مع OpenAI.
3. دمج واجهة برمجة تطبيقات تحويل الصور إلى نصوص: Qwen3 VL
ℹ️ امتداد للمبدأ
إذا كنت ترغب في معرفة المزيد عن المبادئ ذات الصلة، يرجى الاطلاع على الملحق: مقدمة إلى نماذج اللغة المرئية (VLM).
معرفة المزيد: ما هو Qwen3 VL؟
Qwen3 VL هو أحدث إصدار من سلسلة نماذج اللغة المرئية متعددة الوسائط التي أطلقتها فريق Qwen التابع لشركة Alibaba Cloud. يشير اختصار VL إلى "Vision-Language"، أي نموذج اللغة المرئية. يمكنه فهم محتوى الصور، وإنشاء أوصاف نصية بناءً على الصور، والإجابة على أسئلة حول الصور، واستخراج المعلومات من الصور، وغير ذلك.


تشمل القدرات الرئيسية لـ Qwen3 VL:
- فهم الصور: القدرة على التعرف على الأشياء والمشاهد والأشخاص والنصوص وغيرها من المحتويات في الصور
- الإجابة المرئية على الأسئلة: الإجابة بدقة على الأسئلة المتعلقة بالصور بناءً على استفسارات المستخدم
- وصف الصور: إنشاء أوصاف نصية مفصلة أو موجزة للصور
- فهم الصور المتعددة: دعم معالجة صور متعددة في نفس الوقت وإجراء تحليل مقارن
- استخراج النصوص: استخراج المحتوى النصي من الصور (قدرة OCR)
لماذا تختار Qwen3 VL؟
مقارنة بالجيل السابق من النماذج، حقق Qwen3 VL تحسنًا كبيرًا في دقة فهم الصور، ويدعم مهام تحليل الصور الأطول والأكثر تعقيدًا. كما يتميز بأداء ممتاز في فهم اللغة الصينية، وتكلفة استدعاء واجهة برمجة التطبيقات (API) منخفضة نسبيًا، مما يمنحه نسبة قيمة عالية مقابل التكلفة. بالإضافة إلى ذلك، فإن نافذة السياق الخاصة به أكبر، مما يتيح له معالجة مهام الاستدلال المرئي الأكثر تعقيدًا.
سيناريوهات التطبيق النموذجية:
- التجارة الإلكترونية: إنشاء عناوين وأوصاف ونقاط بيع تلقائيًا لصور المنتجات
- إنشاء المحتوى: إنشاء نصوص أو اقتراحات للصور المرفقة تلقائيًا بناءً على صور المواد
- المكاتب: استخراج محتوى الصور، والتعرف التلقائي على التقارير
- التعليم: التحليل التلقائي لأسئلة الصور، واستخراج نقاط المعرفة
في الأجزاء السابقة، أوضحنا كيفية دمج واجهة برمجة تطبيقات إنشاء النصوص، ولكن بالنسبة لسيناريوهات التطبيق المذكورة سابقًا، سنلاحظ مشكلة واحدة: نحن نقوم برفع صورة، وإذا استخدمنا النماذج اللغوية الكبيرة (LLM) فقط، فلن تتمكن من فهم محتوى الصورة بشكل جيد، ومن المرجح أن تختلف النتائج المُنشأة.
نأمل أن يكون هناك نموذج يمكنه مساعدتنا في تحويل الصورة إلى وصف نصي، وهذا يتطلب استخدام نماذج اللغة المرئية (VLM). في هذه الحالة، سنستخدم نموذج اللغة المرئية لإنشاء أوصاف لنقاط بيع المنتجات، مما يعزز تجربة المستخدم.
للراحة، سنستخدم واجهة برمجة التطبيقات (API) التي توفرها منصة SiliconFlow السحابية لدمج واجهة برمجة تطبيقات تحويل الصور إلى نصوص.
معرفة المزيد: ما هي Siliconflow
SiliconFlow هي منصة تجميع نماذج ذكاء اصطناعي معروفة محليًا، وتوفر خدمات واجهة برمجة تطبيقات (API) لمجموعة متنوعة من نماذج اللغة الكبيرة ونماذج اللغة المرئية السائدة.
ميزات المنصة:
- دعم نماذج متعددة: دمج مجموعة متنوعة من نماذج الذكاء الاصطناعي السائدة، بما في ذلك نماذج مفتوحة المصدر مثل سلسلة DeepSeek و Qwen و Llama وغيرها
- التحسين التقني: التحسين للاستدلال للنماذج مفتوحة المصدر، وتوفير خدمات API بزمن استجابة منخفض وتزامن عالٍ
- توافق الواجهة: توفير واجهات API متوافقة مع تنسيق OpenAI، مما يسهل التكامل مع التطبيقات الحالية
- الدفع عند الطلب: دعم الاستخدام بطريقة الدفع بناءً على حجم الاستدعاءات
تعتبر SiliconFlow ناضجة نسبيًا في خدمات استدلال النماذج الكبيرة مفتوحة المصدر، وهي واحدة من الخيارات الشائعة لاستخدام نماذج الذكاء الاصطناعي المحلية مفتوحة المصدر.
بالدخول إلى الصفحة الرئيسية لمنصة SiliconFlow، يمكننا رؤية العديد من النماذج للاختيار من بينها. ابحث عن الفلتر في الزاوية اليسرى العليا، وانقر لتوسيع الفلتر، ثم حدد علامة التبويب "الرؤية" (Vision)، ويمكننا رؤية العديد من نماذج تحويل الصور إلى نصوص، مثل Zhipu GLM-4.6V أو Qwen3-VL.
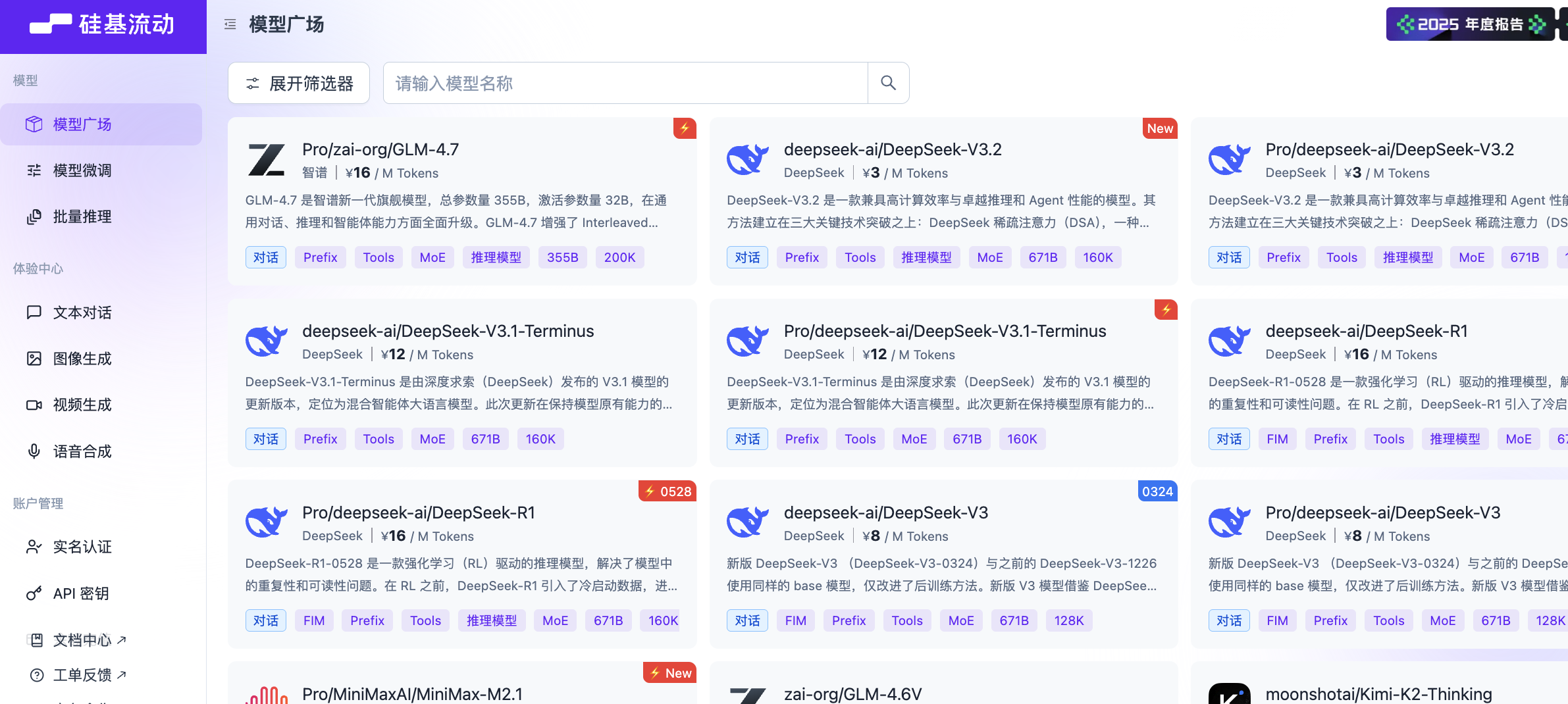
يمكننا اختيار أي نموذج لاختباره، وهنا نأخذ Qwen/Qwen3-VL-8B-Instruct كمثال.
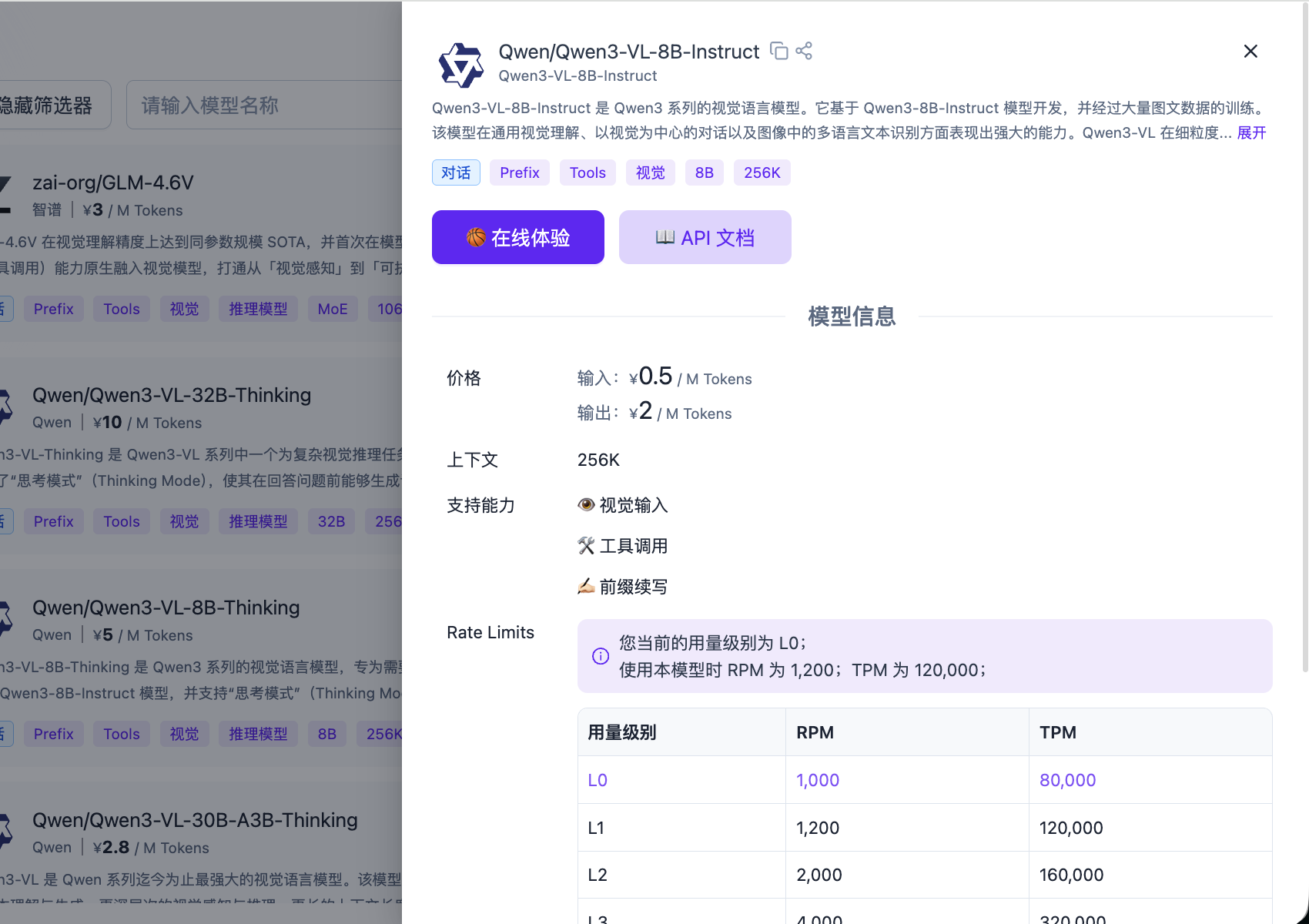
ادخل إلى منصة SiliconFlow، وفي قسم مفاتيح API، انقر على "إنشاء مفتاح API جديد" لإنشاء مفتاح API (API Key) جديد.
يمكنك استخدام الكود أدناه مباشرة ككود مرجعي، وإرساله مع مفتاح API الذي أنشأته إلى بيئة تطوير الذكاء الاصطناعي (AI IDE) لإجراء تكامل الوظائف.
كود مرجعي لتحويل الصور إلى نصوص
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
caption = caption_image(image_path)في هذا السيناريو، نحاول مباشرةً جعل AI IDE يساعدنا في تنفيذ وظيفة توليد نصوص نقاط البيع للتجارة الإلكترونية والكلمات المفتاحية تلقائيًا من الصور المرفوعة، كما هو موضح أدناه:
بناءً على واجهة برمجة تطبيقات تحويل الصورة إلى نص أدناه، ساعدنا في تنفيذ وظيفة توليد نصوص نقاط البيع للتجارة الإلكترونية والكلمات المفتاحية تلقائيًا من الصور المرفوعة
<تم حذف الكود هنا، يجب عليك لصق المفتاح والكود المرجعي بنفسك>أخيرًا نحصل على نتيجة التوليد: 
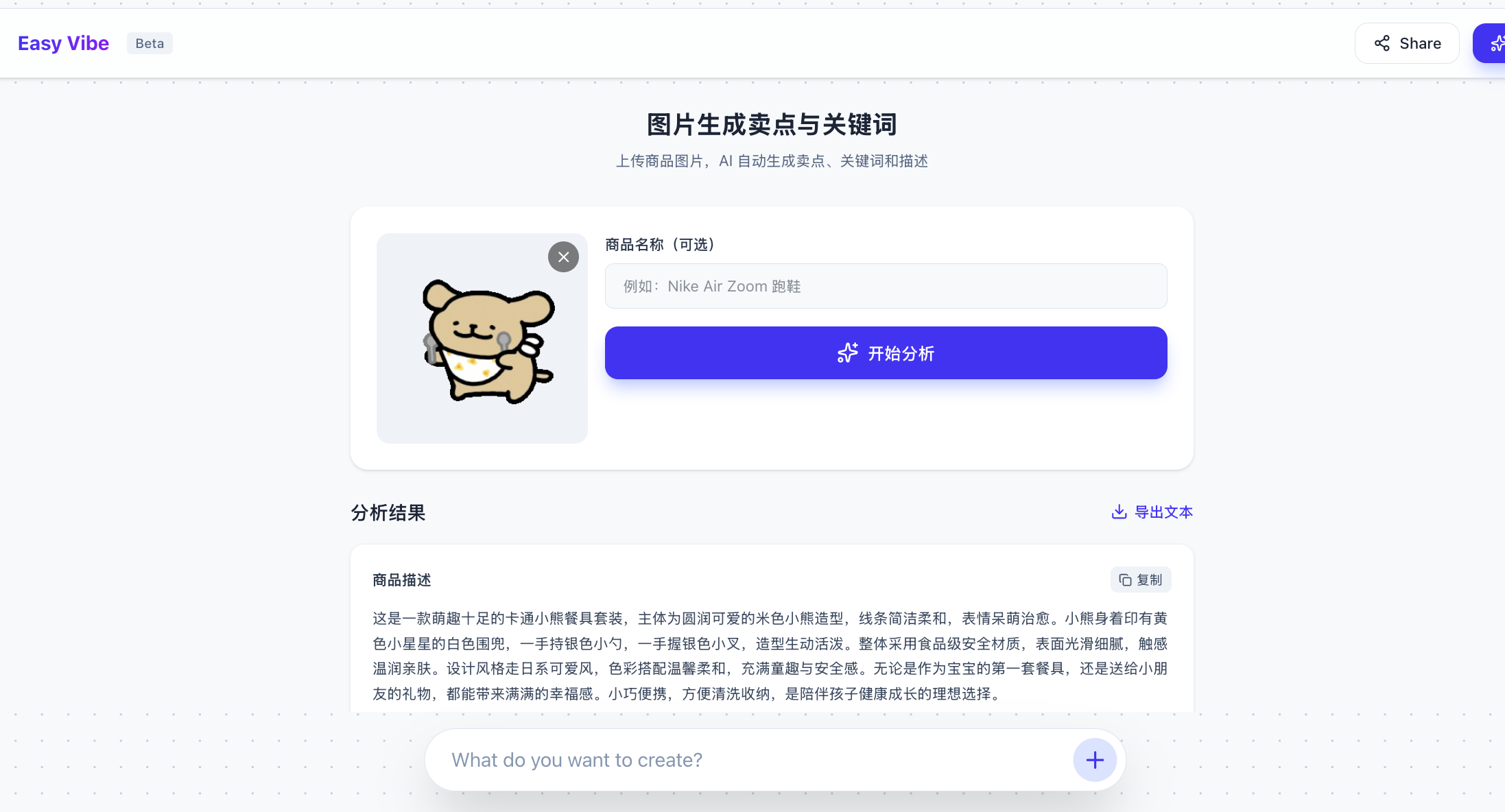
4. ربط واجهة برمجة تطبيقات توليد الصور: Seedream
في الأجزاء السابقة تعاملنا بشكل أساسي مع المهام المتعلقة بالنص، بعد ذلك سنحاول ربط وظيفة توليد الصور، التي تدعم توليد الصور من الأوصاف النصية، أو تعديل الصور.
ℹ️ امتداد للمبدأ
إذا كنت ترغب في معرفة المزيد عن المحتوى المتعلق بالمبادئ، يرجى الاطلاع على الملحق: مقدمة في توليد الصور.
اعرف المزيد: ما هو Seedream؟

ربما تعرف بالفعل Nano Banana (الذي طورته Google)، لكن من الأفضل ألا تفوت Seedream. Seedream 4.5 هو نموذج إنشاء صور من الجيل الجديد الذي طورته ByteDance. إنه يدمج قدرات توليد الصور وتحريرها في بنية موحدة. يتيح له ذلك التعامل بمرونة مع المهام متعددة الوسائط المعقدة، مثل التوليد القائم على المعرفة، والاستدلال المعقد، واتساق المرجع. بالإضافة إلى ذلك، فإن سرعة الاستدلال لديه أسرع بكثير من الجيل السابق، ويمكنه إنشاء صور عالية الدقة مذهلة بدقة تصل إلى 4K.


القدرات الرئيسية:
- توليد الصور من النص: توليد صور من أوصاف نصية، ودعم أنماط متعددة (واقعي، كرتوني، رسم حبر، سايبربانك، إلخ)
- نقل الأسلوب: تحويل صورة إلى أسلوب فني محدد
- متغيرات الصور: إنشاء صور جديدة بأسلوب مشابه بناءً على صورة مرجعية
- تحسين الدقة: تعزيز وضوح الصورة وتفاصيلها
- تحرير الصور: تحرير وتعديل الصور الحالية من خلال تعليمات اللغة الطبيعية
لماذا تختار Seedream؟
- استقرار الشبكة المحلية: سرعة وصول محلية عالية، وزمن استجابة منخفض
- نتائج ممتازة: أداء مستقر وموثوق في سيناريوهات التجارة الإلكترونية والمواد
- تحسين اللغة الصينية: فهم أكثر دقة للكلمات المفتاحية الصينية، مناسب للمستخدمين المحليين
- سرعة عالية: كفاءة توليد عالية، وقت استجابة قصير
- جودة مستقرة: إنشاء صور عالية الدقة بدقة تصل إلى 4K
سيناريوهات التطبيق النموذجية:
- التجارة الإلكترونية: إنشاء الصور الرئيسية، وصور صفحات التفاصيل، وملصقات الترويج
- وسائل التواصل الاجتماعي: إنشاء الصور الرمزية، والرموز التعبيرية، والصور المصاحبة
- التصميم: إنشاء صور المفاهيم، وصور المواد، وصور الخلفيات بسرعة
- التسويق: إنشاء صور الإعلانات، وبانرات الأنشطة، وملصقات الأعياد
التكامل مع Qwen3 VL:
يمكن استخدام واجهتي برمجة التطبيقات هاتين بشكل تسلسلي: استخدم أولاً Qwen3 VL لتحليل الصورة المرجعية وفهم محتوى الصورة؛ ثم استخدم Seedream لإنشاء صور جديدة بناءً على محتوى الكلمات المفتاحية للصورة المرجعية المحللة.
ربما تكون قد رأيت الكثير من "ملصقات AI / صور AI الرئيسية / صور شخصيات AI" على Douyin أو Bilibili أو YouTube، والتي تستخدم في جوهرها التقنية المقدمة في هذا القسم. ما تحتاج إلى القيام به بسيط للغاية: قم بتنظيم إدخال المستخدم في جملة واحدة، واطلب واجهة برمجة تطبيقات الصور، ثم اعرض الصورة المُعادة. النموذج المستخدم في هذا الوقت يسمى نموذج توليد الصور / تحرير الصور.
سنوضح خطوة بخطوة كيفية دمج Seedream API في مشروعك (بمساعدة AI IDE).
بعد زيارة الصفحة الرئيسية، انقر لتسجيل الدخول.
بعد تسجيل الدخول، ابحث عن خيار الشحن في الزاوية العلوية اليمنى من الصفحة.
يتطلب الشحن مصادقة الاسم الحقيقي.
بعد نجاح المصادقة، يمكنك شحن 1 يوان للاختبار.
ارجع إلى الواجهة الأولية وانقر على الوصول عبر API.
أولاً، قم بإنشاء مفتاح API، ثم انقر لتحديد الخيار.
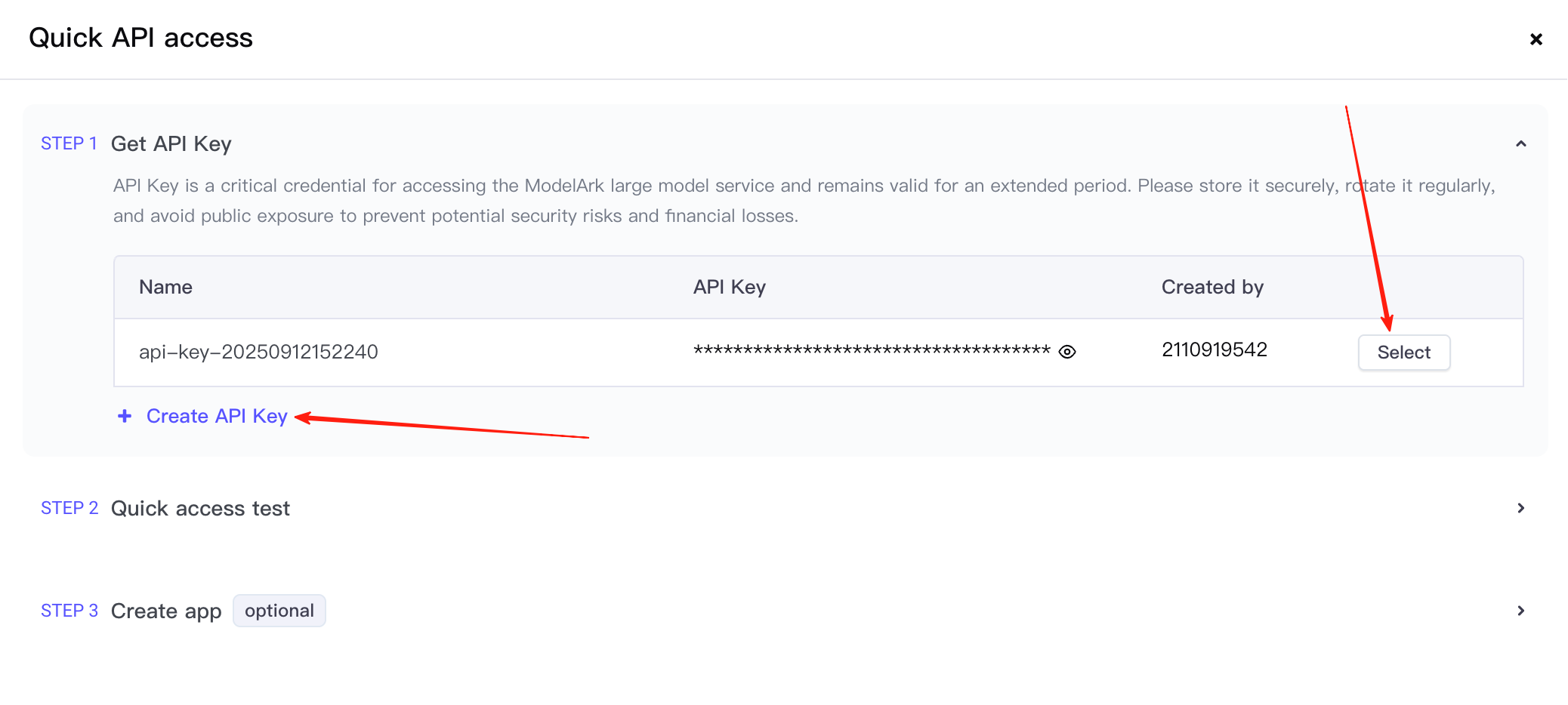
سيأخذك هذا إلى الخطوة الثانية. هنا، تحتاج إلى التأكد من أن الخدمة التي تستدعيها هي Seedream 4.5، ونسخ مثال الاستدعاء المقدم. (لقطة الشاشة هنا التُقطت في وقت مبكر، لذا لا يزال إصدار النموذج 4.0)
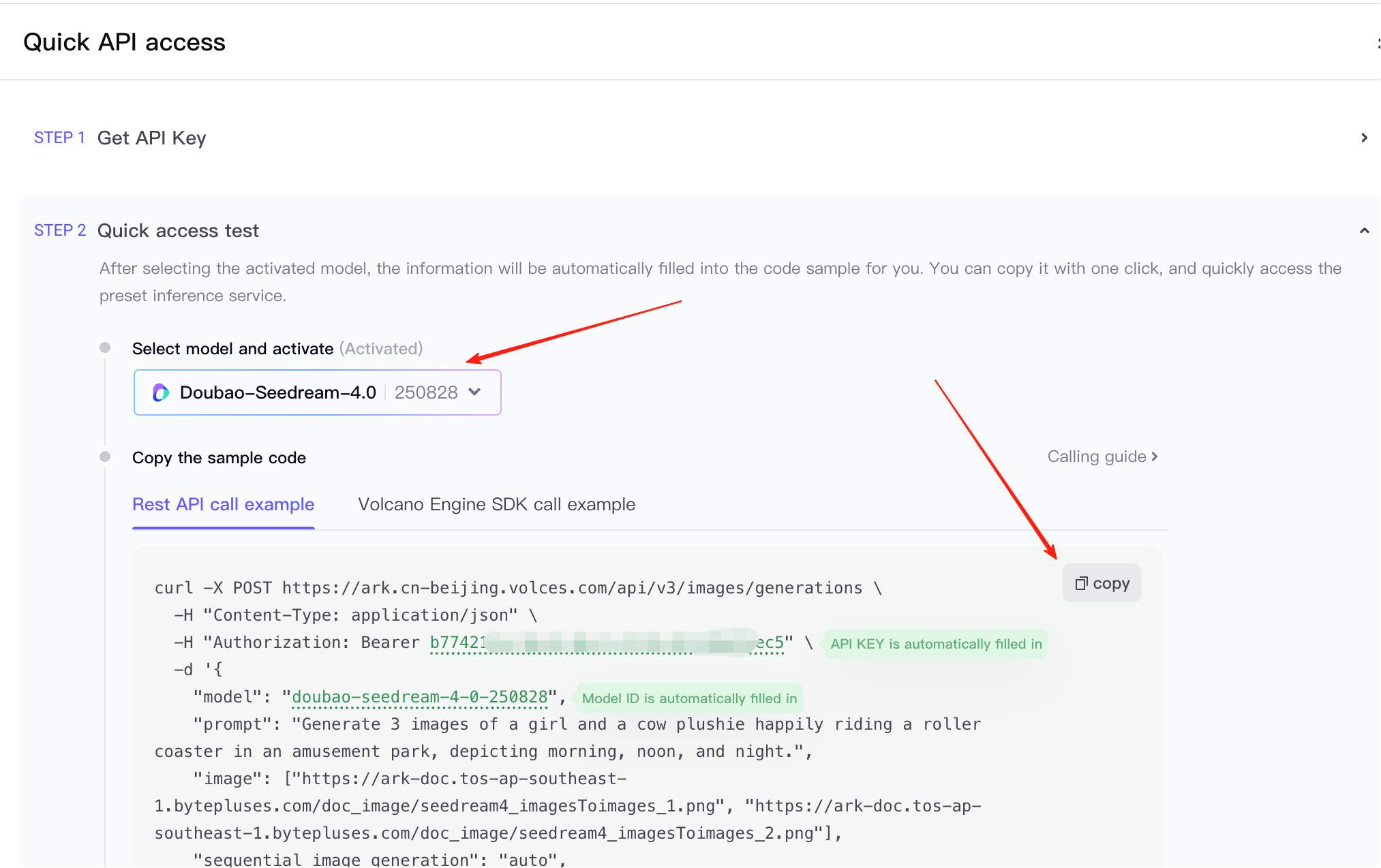
بعد تجهيز مفتاح API ومثال الاستدعاء، يمكنك لصقهما مباشرة في AI IDE، والسماح له بإنشاء عرض تفاعلي للواجهة الأمامية أو دمج القدرة في النموذج الأولي الحالي. لاحظ أنه في الصورة يمكنك اختيار ما إذا كان توليد صورة من نص أو توليد صورة واحدة من صور متعددة، تحتاج إلى اختيار الكود المرجعي بناءً على المتطلبات الحالية.
⚠️ تلميح مهم
المثال الافتراضي هنا معقد نسبيًا. تذكر تعطيل "إضافة علامة مائية" و**"الاستجابة المتدفقة"**، لضمان عدم إنشاء علامة مائية وعدم فشل الطلب.
نظرًا لأننا سنستخدم وضع إنشاء الصور المرجعية لاحقًا، فإننا نذهب أولاً إلى وظيفة إنشاء صورة واحدة من صور متعددة. يتم نسخ الكود المرجعي على النحو التالي:
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "غيّر ملابس الصورة الأولى لتصبح مثل ملابس الصورة الثانية",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'بعد الحصول على كود مرجعي للصور، نجعل AI IDE يدعم وظائف مهام الصور الشائعة في التجارة الإلكترونية:
يرجى بناءً على واجهة برمجة التطبيقات أدناه، مساعدتي في تنفيذ الوظائف الشائعة لأعمال التجارة الإلكترونية في هذا المشروع (مثل إنشاء الملصقات، وإنشاء الصورة الرئيسية لتجارة Douyin الإلكترونية، إلخ)
<الصق مفتاح API وكود تحرير الصور هنا>تأثير التنفيذ كالتالي:
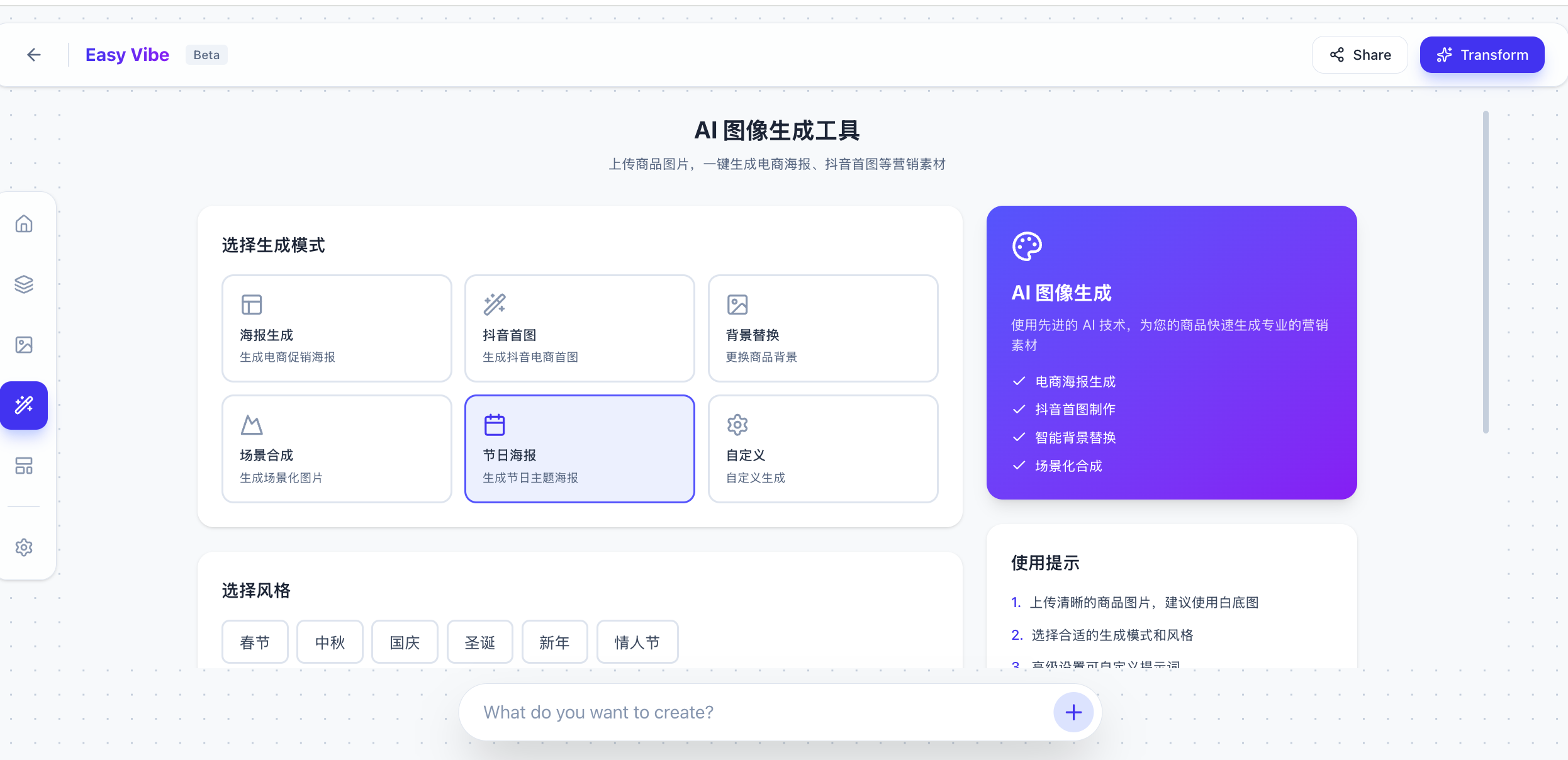 من الجدير بالذكر أنه نظرًا لأن إنشاء الصور قد يواجه غالبًا بعض المشاكل الغريبة، يُنصح بأن تسمح لـ AI IDE بعرض رسائل الخطأ الكاملة لتسهيل النسخ واللصق لإجراء التعديلات (وإلا فقد يظهر فشل الإنشاء بشكل متكرر دون معرفة السبب)، على سبيل المثال يمكنك أن تقول:
من الجدير بالذكر أنه نظرًا لأن إنشاء الصور قد يواجه غالبًا بعض المشاكل الغريبة، يُنصح بأن تسمح لـ AI IDE بعرض رسائل الخطأ الكاملة لتسهيل النسخ واللصق لإجراء التعديلات (وإلا فقد يظهر فشل الإنشاء بشكل متكرر دون معرفة السبب)، على سبيل المثال يمكنك أن تقول:
لا تعرض فقط فشل إنشاء الصورة، بل اعرض السبب الكامل للفشل في كل مرة، مثل عدم تطابق الصور، خطأ في الطلب، انتهاء المهلة، إلخ!في بعض الأحيان لا يتم تطبيق التحديثات بعد التعديل على صفحة الويب. إذا لاحظت أن صفحة الويب تستمر في إظهار الأخطاء بعد التعديل (بشكل متكرر)، يمكنك أيضًا محاولة القول مباشرةً لـ AI IDE: يرجى إعادة تشغيل هذا المشروع.
في أعمال التجارة الإلكترونية، قد نرغب في جعل الملابس التي يحملها المستخدم يتم ارتداؤها تلقائيًا على شخصية، أو إنشاء صور بيع وجذابة للمنتجات أو ملصقات تلقائيًا. هنا المطالبة التي نحاول استخدامها هي جعلها تنشئ ملصقًا للتجارة الإلكترونية:
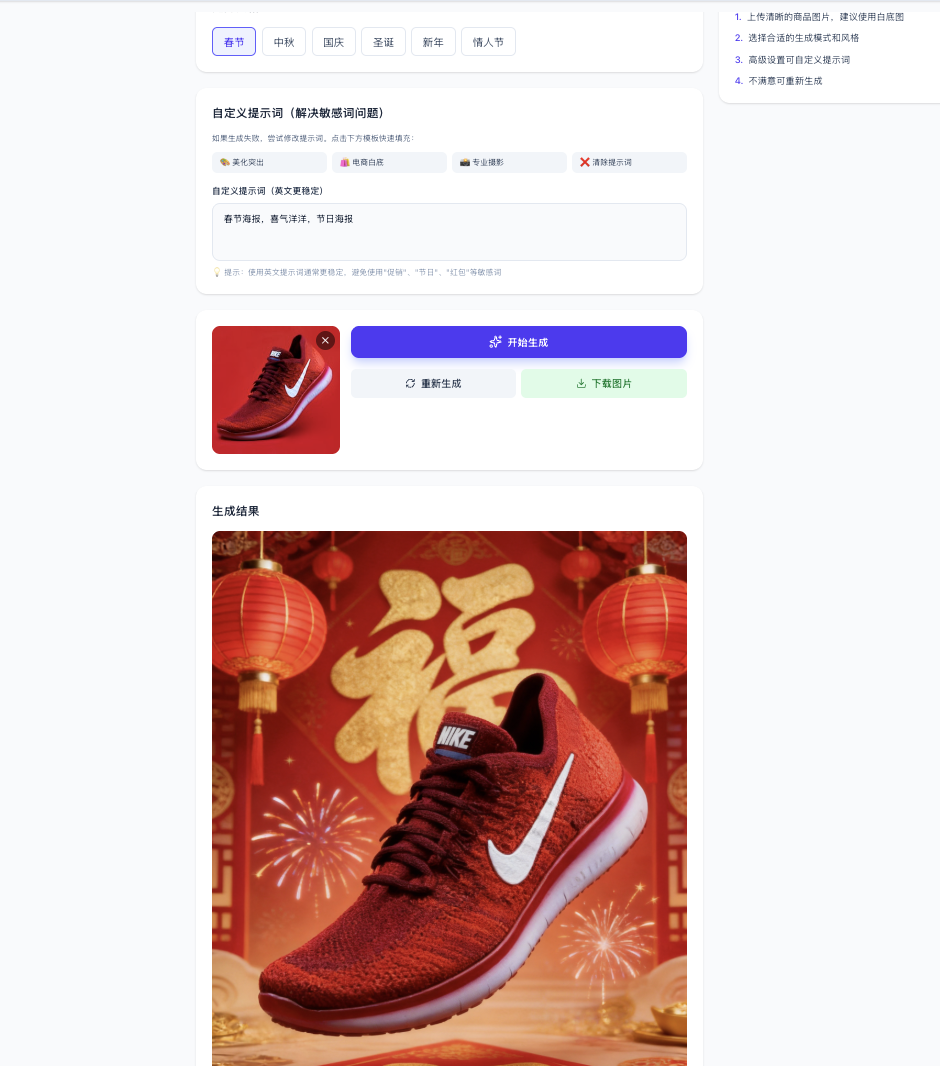
يمكنك، بناءً على سيناريو العمل الذي تتخيله، استخدام واجهة برمجة تطبيقات تحويل النص إلى صورة أو تحويل الصورة إلى صورة لتحقيق وظائف مختلفة.
المزيد من الخيارات المختلفة لخدمات الصور
فيما يلي خيارات أخرى. يُنصح بأن تقوم بتشغيل نتائج إنشاء الصور من Qwen أولاً، ثم استخدام الخدمات التالية كبديل بناءً على التأثير والتكلفة (اختر بناءً على تجربة الاستخدام الفعلية).
تكامل Recraft
إذا كان نموذجك الأولي يميل أكثر إلى "إنتاج التصميم" (مثل إنشاء رسوم توضيحية بأسلوب العلامة التجارية، ملصقات تسويقية، مواد بأسلوب متجهي)، فإن Recraft غالبًا سيكون أكثر ملاءمة. طريقة التكامل هي نفسها تمامًا كما في القسم السابق: الحصول على المفتاح + العثور على المثال الرسمي + جعل AI IDE يطبق المثال على الزر/الصفحة الخاصة بك.
معرفة المزيد: ما هو Recraft؟
Recraft هي أداة AI موجهة للمصممين والرسامين والمسوقين - تأسست في عام 2022 في الولايات المتحدة، ومقرها في لندن. تساعد في إنشاء/تكرار المرئيات (الصور، الفن المتجهي، الرسومات ثلاثية الأبعاد)، مع ميزات مثل مخرجات عالية الجودة (أي حجم/طول للنص)، وتحديد دقيق للعناصر، وتصميم متسق مع العلامة التجارية. موثوق بها من قبل أكثر من 3 ملايين مستخدم في 200 دولة (بما في ذلك Ogilvy و Netflix)، وتم إنشاء أكثر من 350 مليون صورة، ويهدف فريقها إلى جعلها أداة لا غنى عنها للمصممين، مما يضمن قدرة المبدعين على التحكم في سير عملهم المدعوم بالـ AI.


أولاً، لا يزال يتعين علينا العثور على مدخل API للحصول على مفتاح API.
نظرًا لعدم توفير رصيد مجاني هنا، نحتاج إلى شحن 1,000 نقطة بأنفسنا. يدعم هذا الموقع Alipay و WeChat Pay، لذلك من السهل الحصول على 1,000 نقطة (ملاحظة: لا تشحن أكثر من الضروري).

بعد ذلك، لا نزال نتبع نفس الطريقة: الذهاب إلى الوثائق الرسمية للعثور على مثال الطلب المقابل:
تكامل Qwen Image / Qwen Image Edit
إ كنت ترغب في استخدام طريقة أبسط للاتصال بخدمة إنشاء الصور، يمكنك التفكير في Qwen Image (Tongyi Wanxiang). يبقى النهج كما هو: تعامله كـ "واجهة برمجة تطبيقات لإنشاء الصور"، وقم بتوصيله بزر النموذج الأولي الخاص بك.
معرفة المزيد: ما هو Qwen Image / Qwen Image Edit؟
Qwen Image (المعروف أيضًا باسم Tongyi Wanxiang) هي سلسلة نماذج إنشاء الصور التي أطلقتها فريق Tongyi التابع لـ Alibaba Cloud، وتتضمن بشكل أساسي نموذجين كبيرين:
1. Qwen Image —— نموذج تحويل النص إلى صورة (Text-to-Image)
ينشئ صورًا جديدة بناءً على وصف نصي. تقوم بإدخال مطالبة، ويفهم النموذج نيتك ويقوم بإنشاء صورة تتطابق مع الوصف.

القدرات الرئيسية:
- تحويل النص إلى صورة: إنشاء صور من وصف نصي، ودعم أنماط متعددة (واقعي، كرتوني، رسم بالحبر، سايبربانك، إلخ)
- نقل الأسلوب: تحويل صورة إلى أسلوب فني محدد
- متغيرات الصورة: إنشاء صور جديدة بأسلوب مشابه بناءً على صورة مرجعية
- تحسين الدقة: تعزيز وضوح الصورة وتفاصيلها
2. Qwen Image Edit —— نموذج تحويل الصورة إلى صورة (Image-to-Image)
تحرير وتعديل الصور الحالية. من خلال تعليمات اللغة الطبيعية، دع النموذج يفهم نية التعديل الخاصة بك ويقوم بإنشاء النتيجة.
القدرات الرئيسية:
- الاستبدال المحلي: استبدال كائن أو شخص معين في الصورة (مثل "تغيير الخلفية إلى شاطئ البحر")
- إزالة العناصر: إزالة العناصر غير المرغوب فيها من الصورة
- تحويل الأسلوب: إضافة فلاتر أو تأثيرات فنية إلى الصورة
- توسيع الصورة: توسيع حدود الصورة لإنشاء محتوى جديد
- تحرير ذكي للصور: تجميل تلقائي، ضبط الإضاءة والظلال، إصلاح العيوب



لماذا تختار سلسلة Qwen Image؟
- مُحسّن للصينية: فهم أكثر دقة للمطالبات الصينية، ومناسب للمستخدمين المحليين
- تكلفة منخفضة: مقارنة بالمنتجات التنافسية الدولية، السعر أكثر بأسعار معقولة
- سرعة عالية: كفاءة إنشاء عالية، وقت استجابة قصير
- جودة مستقرة: أداء مستقر وموثوق في سيناريوهات التجارة الإلكترونية والمواد
- أنماط متنوعة: دعم مجموعة متنوعة من الأنماط الفنية والتأثيرات الإبداعية
سيناريوهات التطبيق النموذجية:
- التجارة الإلكترونية: إنشاء الصور الرئيسية، صور صفحات التفاصيل، ملصقات ترويجية
- وسائل التواصل الاجتماعي: إنشاء صور الملف الشخصي، الرموز التعبيرية، الصور المصاحبة
- التصميم: إنشاء سريع للرسومات المفاهيمية، صور المواد، صور الخلفية
- التسويق: إعلانات، لافتات الأنشطة، ملصقات الأعياد
تحقق من الموقع الرسمي لـ SiliconFlow. يوجد قسم "Playground" على الجانب الأيسر، حيث يمكنك تجربة نماذج مختلفة دون إجراء استدعاءات API. يوجد زر "Filters" في أعلى صفحة الويب؛ انقر فوقه لتصفية قائمة النماذج الموجودة على اليمين.
إذا اخترت "Image"، فسترى فقط جميع نماذج تحويل النص إلى صورة المدعومة حاليًا. في هذه الحالة، سنستخدم Qwen/Qwen-Image.
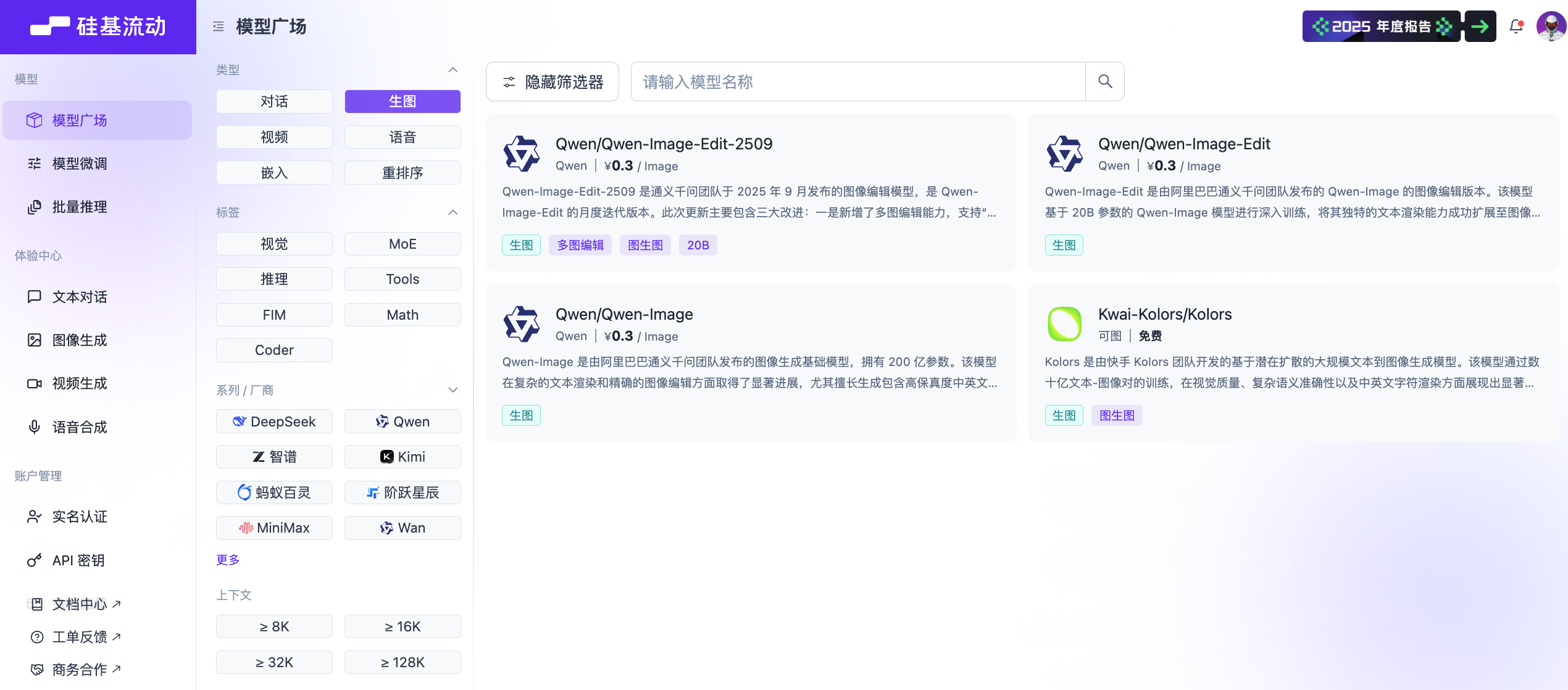
بعد إعداد كل شيء، نحتاج إلى الرجوع إلى وثائق واجهة برمجة تطبيقات إنشاء الصور المقابلة. يمكنك العثور على أي قسم يحمل علامة "API Reference" في صفحة الوثائق الرسمية. انقر فوقه، ثم انتقل إلى قسم API لإنشاء الصور وابحث عن مثال الطلب ذي الصلة.
يمكنك إرسال مثال الطلب التالي مع API KEY إلى AI IDE، لتحقيق وظيفة إنشاء الصور.
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'يمكن استخدام النموذج Qwen/Qwen-Image أو Qwen/Qwen-Image-Edit-2509 هنا.
كود مرجعي لتحرير الصور
انسخ الكود التالي والمفتاح (key)، وأرسلهما معًا إلى AI IDE:
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "اجعل السماء في وقت المساء، مع قمر ونجوم، بأسلوب حالم"
negative_prompt: str = "ضبابي، جودة منخفضة، مشوّه"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")الملحق: كيفية العثور على نموذج AI "الأقوى حالياً"
تتطور النماذج النصية (والتي تُعرف غالباً بـ "النماذج اللغوية الكبيرة" أو LLMs) بسرعة كبيرة، ونحتاج دائماً إلى التأكد من أننا نستخدم أحد النماذج ذات الأداء الأفضل. من خلال الموقعين التاليين، يمكنك بسهولة رؤية "النماذج الشائعة الاستخدام حالياً والتي تحظى بتقييمات أفضل".
بشكل عام، يمكن فهم هذه المواقع على أنها "ساحة منافسة للنماذج": حيث يتم وضع مخرجات نموذجين معاً، وتصوت للنموذج الذي تفضله. النموذج الحاصل على أصوات أعلى، يعني عادةً أن المزيد من الناس يرون أنه "أفضل في الاستخدام".
بالإضافة إلى ذلك، قد تلاحظ أحياناً في هذه الساحات نماذج مجهولة وغامضة ("Unknown Model"). هذا يعني عادةً: أن شخصاً ما قام بإدخال "نموذج اختبار داخلي" سراً لإجراء اختبار أعمى، وقد تتيح لك الفرصة لتجربة قدرات أقوى مسبقاً.
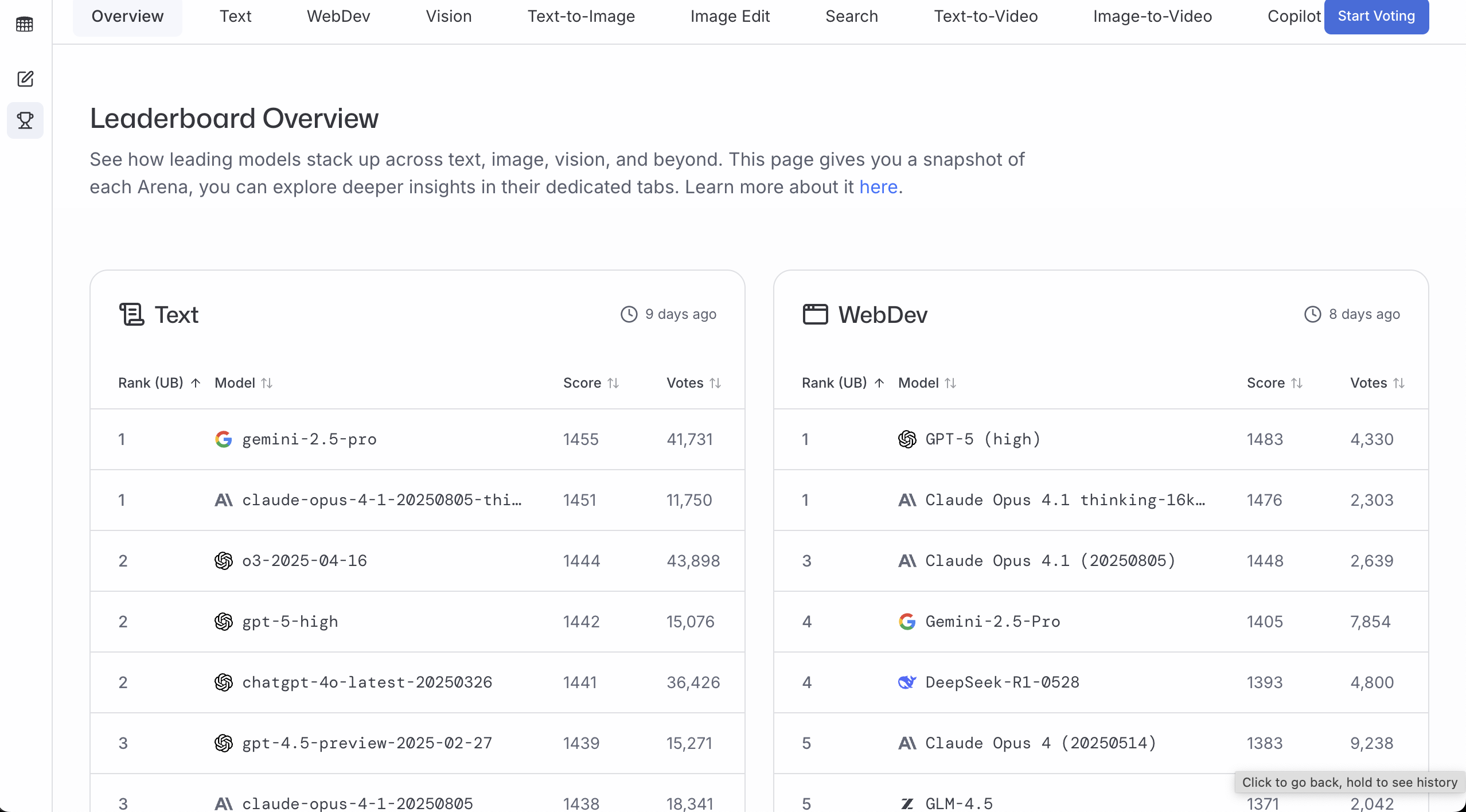
LMArena
الموقع: https://lmarena.ai/
يناسب LMArena بشكل أفضل لتحديد "الإجابة التي يفضلها معظم الناس لنموذج معين". كلما زادت الأصوات وارتفعت النتيجة، يعني ذلك عادةً أنه أكثر استقراراً في سيناريوهات الاستخدام الفعلية.
طريقة استخدام بسيطة هي:
- النظر مباشرة إلى لوحة المتصدرين (Leaderboard)
- اختيار التوجه الذي ترغب فيه أولاً (على سبيل المثال: محادثة عامة / برمجة / رؤية حاسوبية)
- اختيار النموذج المتاح لك من بين أفضل 3 (يمكنك الوصول إليه، وسعره مقبول، و زمن الاستجابة مقبول)
Artificial Analysis
الموقع: https://artificialanalysis.ai/
يناسب Artificial Analysis بشكل أفضل لمقارنة "الأداء / السعر / السرعة" في جدول واحد، ويمكنك اعتباره كجدول مواصفات لاختيار النموذج.
طرق الاستخدام الشائعة هي:
- العثور على فئة النموذج التي تهتم بها (نص / توليد صور، إلخ)
- النظر إلى مؤشرات الجودة (Quality) + السعر (Price) + زمن الاستجابة/الإنتاجية (Latency/Throughput)
- اختيار نموذج يمثل "أفضل قيمة شاملة" يناسب منتجك
✅ نصيحة
لا تتجادل بناءً على الشعور حول "أيهما أقوى". النهج الأكثر موثوقية هو: اختبار 2~3 نماذج في نفس الوقت باستخدام نفس مجموعة المدخلات، ثم اتخاذ القرار بناءً على لوحات المتصدرين والأسعار.
الخلاصة
عند التكامل مع مختلف خدمات AI، لا داعي لتخيل أن الـ API معقد للغاية. من خلال إمساك المفاهيم الأساسية التالية، يمكنك التعامل مع معظم السيناريوهات بشكل أساسي:
جوهر الـ API هو جسر اتصال. ما يفعله بسيط جداً: إرسال طلبك، ثم إعادة استجابة النموذج إليك. لا تحتاج إلى الاهتمام بما يحدث في الخلفية، كل ما عليك فعله هو تنظيم تنسيق الطلب بشكل صحيح.
الـ SDK هو تغليف للـ API. إذا كان الـ API هو الواجهة الخام (raw)، فإن الـ SDK هو مجموعة أدوات جاهزة - حيث يقوم بإنجاز التفاصيل المملة مثل توقيع الطلبات، ومعالجة الأخطاء، والتحقق من المعلمات نيابةً عنك. في التطوير اليومي، يُفضل اختيار الـ SDK بدلاً من استدعاء الـ API مباشرة، مما يوفر عليك الكثير من المتاعب.
عند قراءة الوثائق، يكفي التركيز على ثلاثة أشياء فقط: عنوان الخدمة (endpoint)، وبيانات الاعتماد (API key)، وكيفية ملء معلمات الاستدعاء. بمجرد توضيح هذه النقاط الثلاث، فإن نجاح الاستدعاء هو مسألة وقت فقط.
باقي العمل، ستقوم بيئة التطوير المتكاملة (IDE) وأدوات التطوير الحديثة بمساعدتك في إنجازه. ركز على منطق عملك، واترك أمور الاستدعاءات الأساسية لهذه الـ SDKs وسلاسل الأدوات الناضجة.
5. 📚 الواجب: تكامل قدرتك الأولى في AI
بالرجوع إلى الـ prompts ومحتوى هذا الدرس، قم بإكمال دورة كاملة مغلقة:
- ممارسة الدورة الكاملة المغلقة
- اختر واتصل بخدمة AI (LLM / نص لصورة / صورة لصورة) → قم بتنفيذ التفاعل بين الواجهة الأمامية والخلفية → قم بدمجها في النموذج الأولي الخاص بك
- مشاركة النتائج
- التقط لقطة شاشة لصفحة وظيفتك وشاركها مع الجميع
- سؤال تفكيري
- اترك مساحة للدرس التالي "ممارسة مشروع كامل"، وفكر مسبقاً: كيف تنوي دمج هذه قدرات AI معاً لصنع وظيفة ممتعة؟
الخطوة التالية
في القسم التالي، سنربط هذه قدرات AI المتباينة معاً، ونبني منتجاً كاملاً بالجمع بين سيناريوهات العمل الفعلية:
- ربط مراحل مثل تخطيط المحتوى، ورفع المنتجات، وتحليل البيانات في مسار عمل كامل
- تضمين قدرات AI التي تعلمناها في هذا الدرس (توليد النصوص عبر LLM، نص لصورة، تحرير الصور، إلخ) في عقد العمل الفعلية
- بناء "مساحة عمل AI للتجارة الإلكترونية" قابلة للاستخدام فعلياً، وليس مجرد demo معزول