Anfänger IV: AI-Fähigkeiten in den Prototyp integrieren
Kapitelübersicht
1. API-Grundkonzepte
Wir erwähnten, dass unser Ziel ist, "AI-Fähigkeiten zu integrieren" und den Prototypen von einer statischen Demo zu einem Tool zu machen, das echte AI-Dienste aufrufen kann. Der Schlüssel dafür liegt im Verständnis und der Nutzung von APIs (Application Programming Interfaces).
API ist ein wichtiges Abstraktionskonzept im Computerbereich. Man kann es sich einfach vorstellen als: Sie senden "eine Frage" im gewünschten Format und erhalten "ein Ergebnis" im selben Format zurück.
- Was Sie senden: Enthält normalerweise einen "Schlüssel (API Key)" und "was Sie generieren möchten"
- Was Sie zurückbekommen: Bei Erfolg das Ergebnis; bei Fehler die Ursache (z.B. "Schlüssel falsch", "Guthaben unzureichend", "Parameter fehlerhaft")
Konkret müssen Sie folgende Kernelemente beherrschen:
- API Key: Ihr "Ausweis" und zugleich Ihr "Geldschlüssel". Wer ihn hat, kann in Ihrem Namen API-Aufrufe tätigen und Kosten verursachen.
- Endpoint (Schnittstellenpfad): Der spezifische Pfad der API-Anfrage, der dem Server sagt, welche Funktion Sie nutzen möchten. Die vollständige Anfrage-URL besteht normalerweise aus "Basis-URL + Endpoint-Pfad". Zum Beispiel:
- Textgenerierung: Basis-URL (
https://api.service.com) + Endpoint (/v1/chat/completions) = Vollständige URLhttps://api.service.com/v1/chat/completions - Bildgenerierung: Basis-URL (
https://api.service.com) + Endpoint (/v1/images/generations) = Vollständige URLhttps://api.service.com/v1/images/generations
- Textgenerierung: Basis-URL (
- Aufruf/Anfrage: Der Prozess, eine Aufgabe an den AI-Dienst zu senden und Ergebnisse zu erhalten
- Anfrage-Inhalt: Was Sie an AI senden, z.B. das Thema des Artikels, den AI schreiben soll, oder die Beschreibung des zu generierenden Bildes
- Antwort-Ergebnis: Was AI nach der Verarbeitung zurückgibt, z.B. den generierten Artikel oder das Bild
- Fehlerbehandlung: Wissen, wie man Probleme diagnostiziert, wenn etwas schiefgeht (falscher API Key, zu häufige Anfragen etc.)
Was ist eine API?
Eine ausführlichere Erklärung finden Sie im Anhang: API-Einführung.
API-Sicherheitshinweise
API Key ist Ihr "Ausweis" für AI-Dienst-Anfragen – eine Passwort-Zeichenkette zur Authentifizierung und Abrechnung.
Da der API Key direkt mit Ihrem Konto und den Kosten verbunden ist, beachten Sie unbedingt:
- Niemals in Gruppenchats teilen, als Screenshot online stellen oder in öffentlichen Foren veröffentlichen
- Nicht im Code hartcodieren und in ein Git-Repository laden (besonders öffentliche Repos)
- Wenn Sie vermuten, dass der Key kompromittiert wurde: Sofort einen neuen Key erstellen
Wir werden in den folgenden Inhalten den API KEY direkt in die AI IDE einfügen. In echten Projekten nicht so vorgehen!! Da es sich um eine Übung handelt, ist es in Ordnung. (Wenn Sie fortgeschrittener sind, können Sie AI eine Konfigurationsdatei generieren lassen und den API Key dort eintragen.)
2. Textgenerierungs-API integrieren: DeepSeek
Obwohl APIs diese technischen Konzepte beinhalten, kann die praktische Umsetzung in der Prototyp-Phase sehr einfach und effizient sein. Das Kernprinzip:
Offizielles Beispiel finden, API Key besorgen, AI IDE an den Button anbinden lassen.
Mit diesem Verständnis werden Sie feststellen: Ob Text- oder Bildmodell – der grundlegende Ablauf ist derselbe: Wenn der Nutzer auf einen Button klickt, bereitet das Frontend die Eingabe vor und sendet die Anfrage; die Schnittstelle gibt das Ergebnis zurück, das dann auf der Seite angezeigt wird. Als Nächstes werden wir dies durch praktische Anwendung überprüfen.
In "1.2 Prototyp erstellen" haben Sie bereits einen interaktiven Prototypen erstellt. Als Nächstes verwandeln wir die "AI-ähnlichen Funktionen" im Prototyp in echte Fähigkeiten: Wenn der Nutzer auf den Button klickt, sendet der Prototyp eine Anfrage an einen externen AI-Dienst und zeigt den zurückgegebenen Text an.
Prinzip-Erweiterung
Wenn Sie mehr über die Prinzipien erfahren möchten, siehe Anhang: Große Sprachmodelle (LLM) Einführung.
Mehr erfahren: Was ist DeepSeek?
Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., unter dem Handelsnamen DeepSeek, ist ein chinesisches AI-Unternehmen, das große Sprachmodelle (LLMs) entwickelt. DeepSeek hat seinen Hauptsitz in Hangzhou, Provinz Zhejiang, und wird von dem chinesischen Hedgefonds High-Flyer besessen und finanziert. DeepSeek wurde im Juli 2023 von Liang Wenfeng, Mitbegründer von High-Flyer, gegründet, der auch CEO beider Unternehmen ist. Das Unternehmen brachte im Januar 2025 den gleichnamigen Chatbot und das DeepSeek-R1-Modell auf den Markt.
Schauen wir uns an, wie DeepSeek im GPQA-Benchmark-Ranking im Vergleich zu anderen Top-Modellen abschneidet. Bemerkenswert: DeepSeek ist ein Open-Source-Modell (jeder kann das Modell aus dem Internet herunterladen), während andere gängige Modelle wie Grok, Google Gemini und ChatGPT proprietär sind. Wie wir sehen, hat DeepSeek die Spitze bereits weitgehend erreicht.
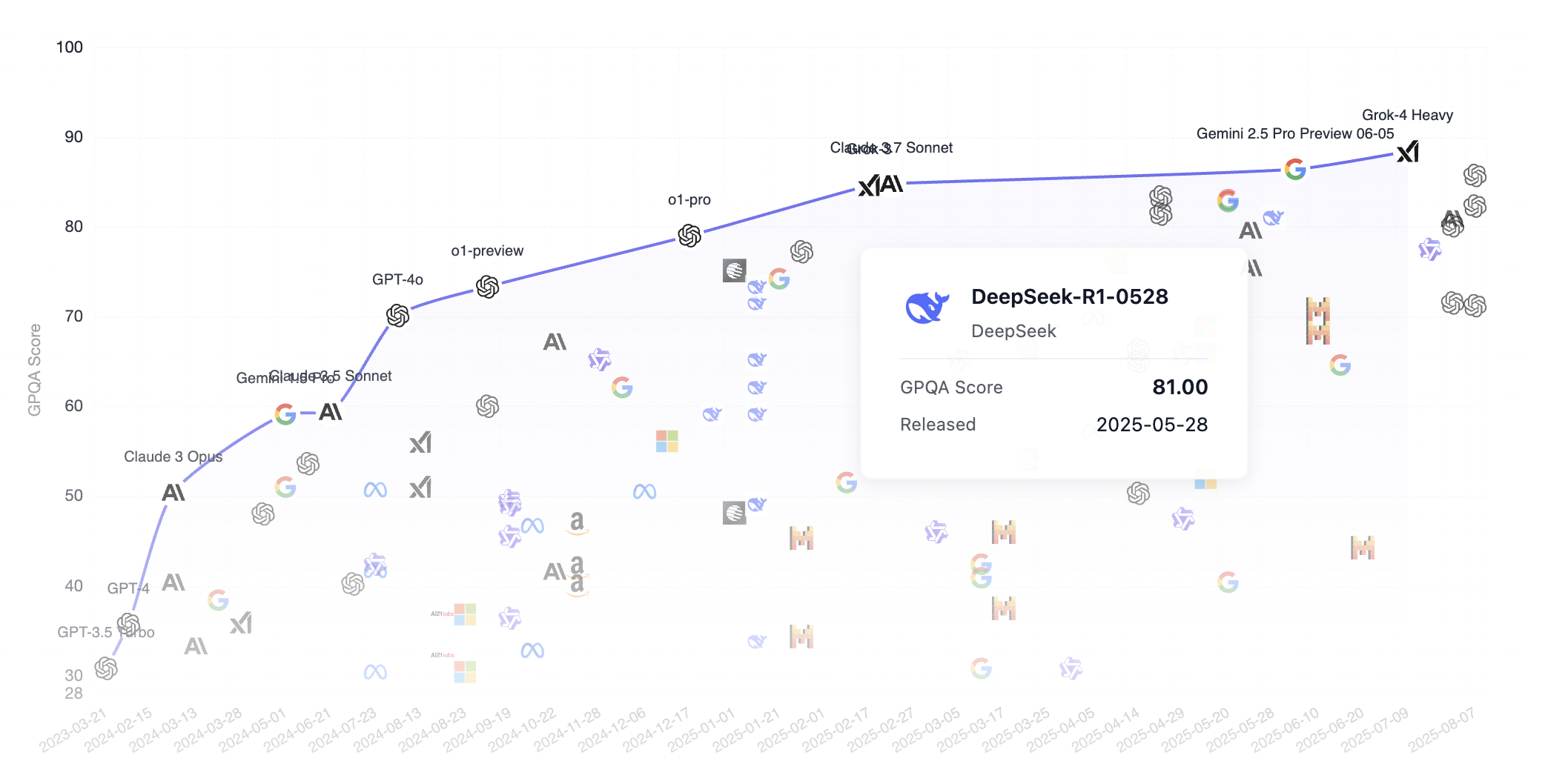
GPQA steht für "Graduate-Level Google-Proof Q&A Benchmark", ein Benchmark für wissenschaftliche Frage-Antwort-Aufgaben auf Graduiertenniveau. Hier ist eine detaillierte Einführung.
GPQA enthält 448 Multiple-Choice-Fragen aus Teilbereichen der Biologie, Physik und Chemie, wie Quantenmechanik, organische Chemie, Molekularbiologie usw. Diese Fragen wurden von 61 Experten mit Doktortitel oder in Doktorandenausbildung verfasst und durchliefen einen strengen Verifizierungsprozess.
Folgen Sie diesen 3 Schritten, um die schnelle Integration der LLM-Generierungs-API zu realisieren:
- Einen API Key auf der DeepSeek-Plattform erstellen
- Das Textgenerierungs-Beispiel in der DeepSeek-Dokumentation finden (oft gibt es fertigen Code zum direkten Kopieren)
- AI IDE öffnen, API Key + offizielles Beispiel einfügen und AI sagen, welche Funktion implementiert werden soll:
Hilf mir, die API dieses großen Modells zu integrieren, unterstütze die Copywriting-Generierung dieser Anwendung
Als Nächstes demonstrieren wir den Ablauf. Sie können den gesamten Prozess einmal mitschreiben. Registrieren Sie zunächst ein DeepSeek-Konto, erstellen Sie einen API Key und laden Sie ein kleines Guthaben auf.
Klicken Sie auf "API KEYS" und finden Sie unten auf dem Bildschirm "create new API key". Sie erhalten schließlich einen API Key wie sk-8573341c39fc44315aadc071c53rh7d2.
Sobald Sie den Schlüssel haben, verfügen Sie über die Berechtigung, das Modell aufzurufen.
Nun können Sie die API-Dokumentation lesen, die normalerweise curl- oder Python-Aufrufbeispiele bietet.
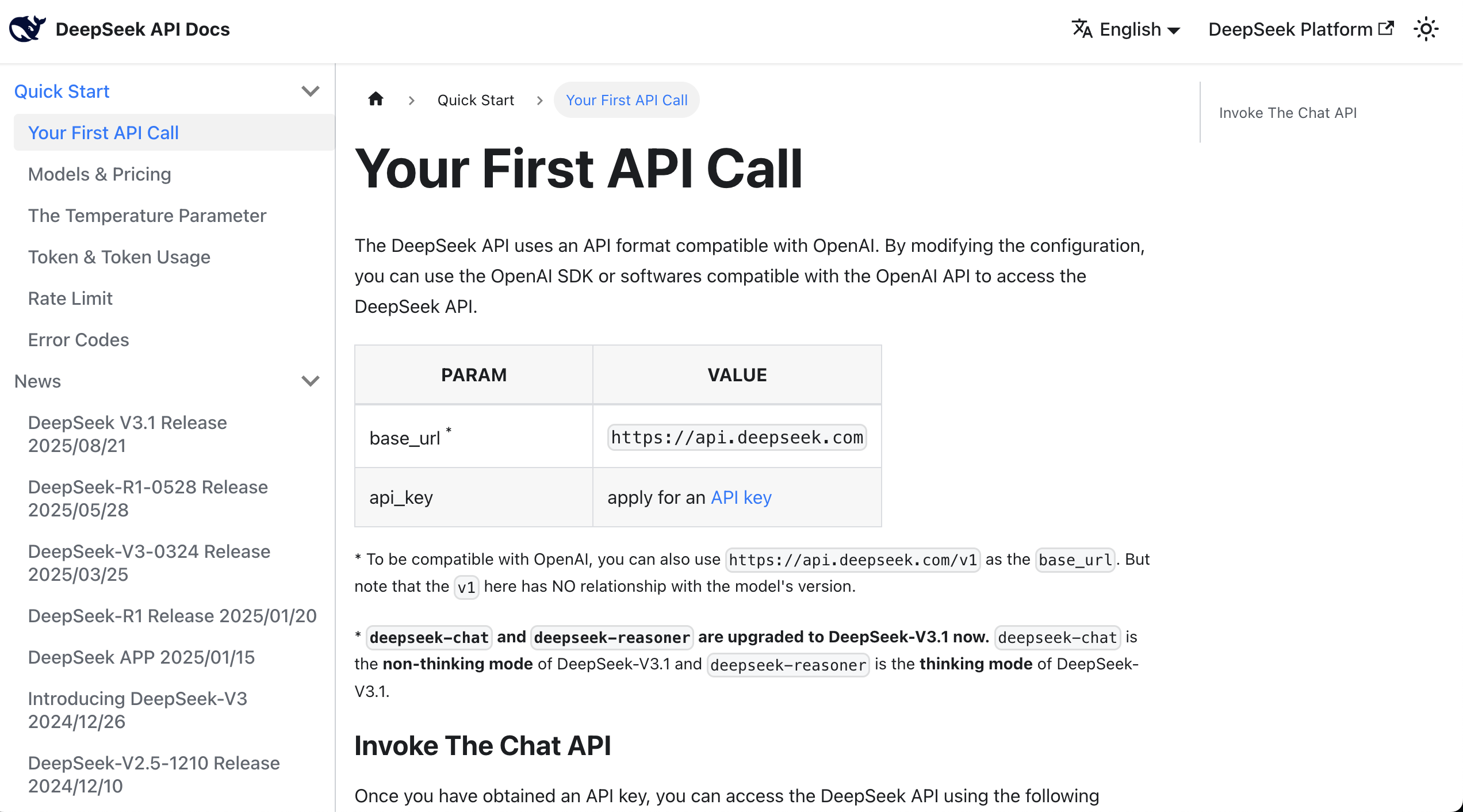
Nachdem Sie das Beispiel gefunden haben, können Sie den gesamten Inhalt der Dokumentation zusammen mit dem Schlüssel in den AI IDE-Dialog kopieren und das LLM in den bereits entwickelten Prototypen integrieren lassen.
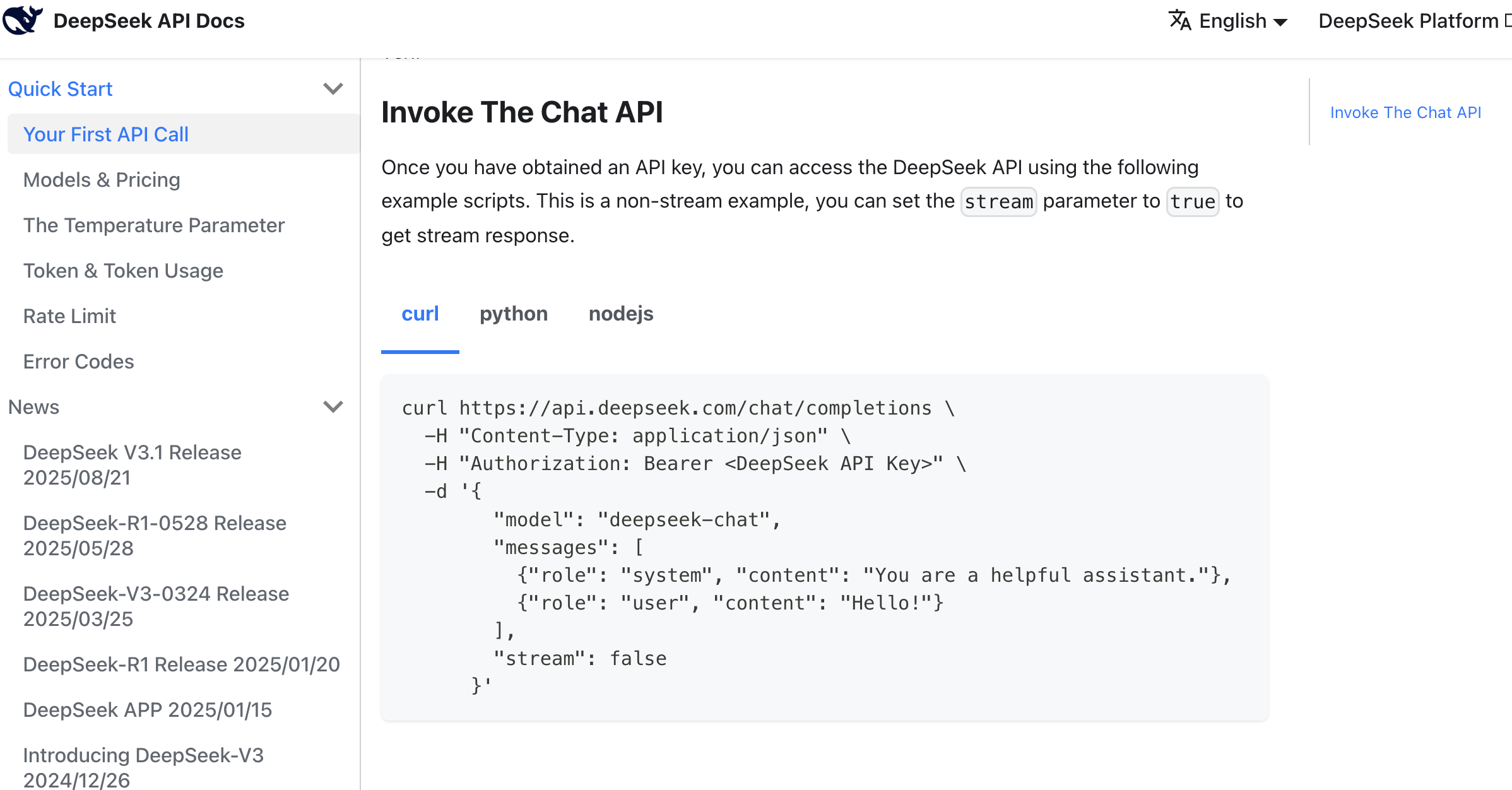
Verwenden Sie folgenden Prompt als Referenz:
Beziehe dich auf diese Aufrufmethode und hilf mir, die Copywriting-Generierung zu unterstützen.
Basierend auf Produktinformationen soll nach Klick Douyin E-Commerce-Copywriting in verschiedenen Stilen generiert werden.
Referenzmaterialien:
api key: sk-8573341c39aefa1efe
api Anfrage-Referenz:
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'Nach einer Weile der AI-Codegenerierung erhalten Sie leicht den entsprechenden Copywriting-Generierungs-Button zum Testen. Wenn Sie den Einstieg nicht finden, können Sie AI IDE nach der relevanten Seite fragen. Wenn Sie wirklich nicht weiterkommen, können Sie AI IDE direkt basierend auf Ihren Ideen umgestalten lassen, um das endgültige Copywriting-Generierungsergebnis zu erhalten.
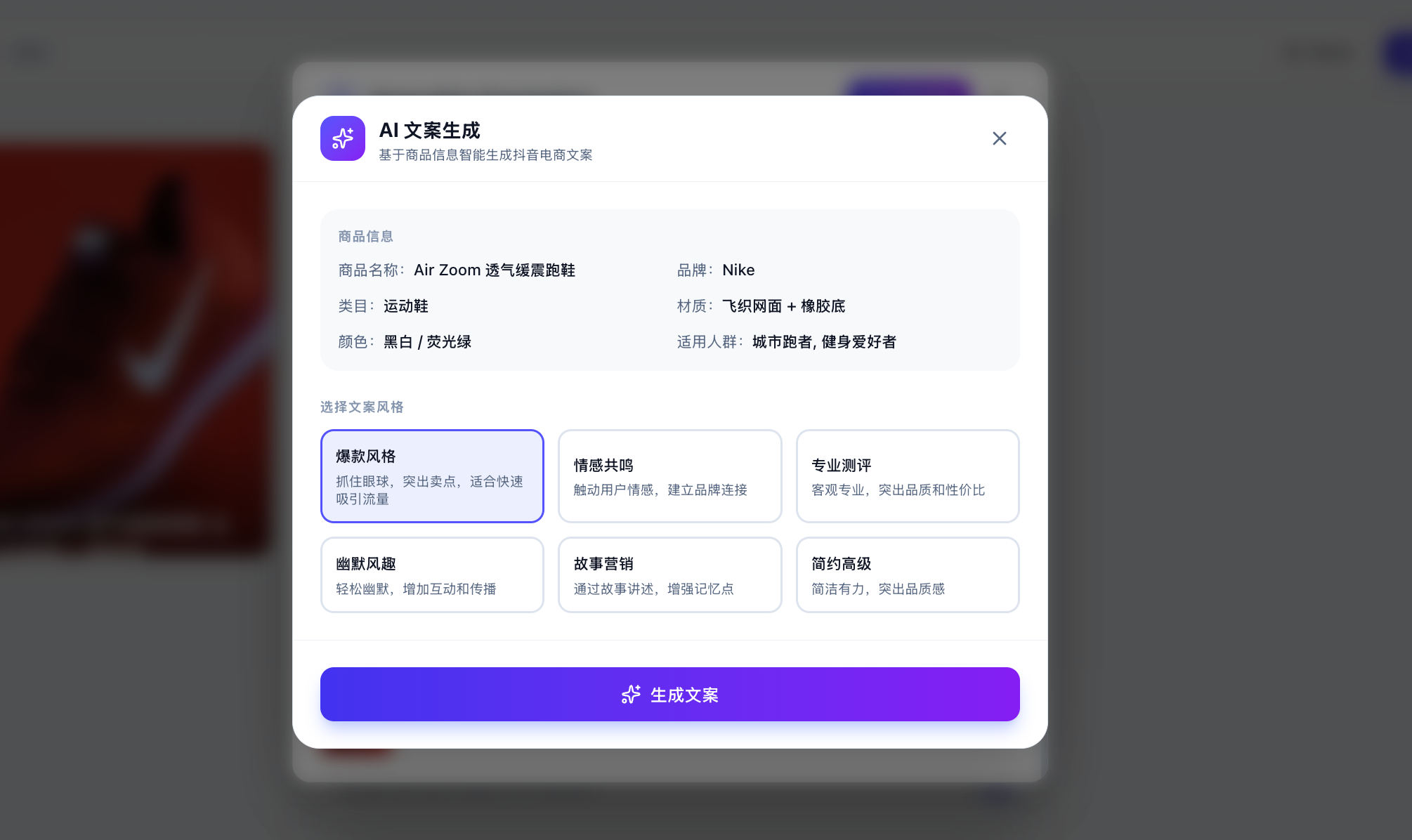
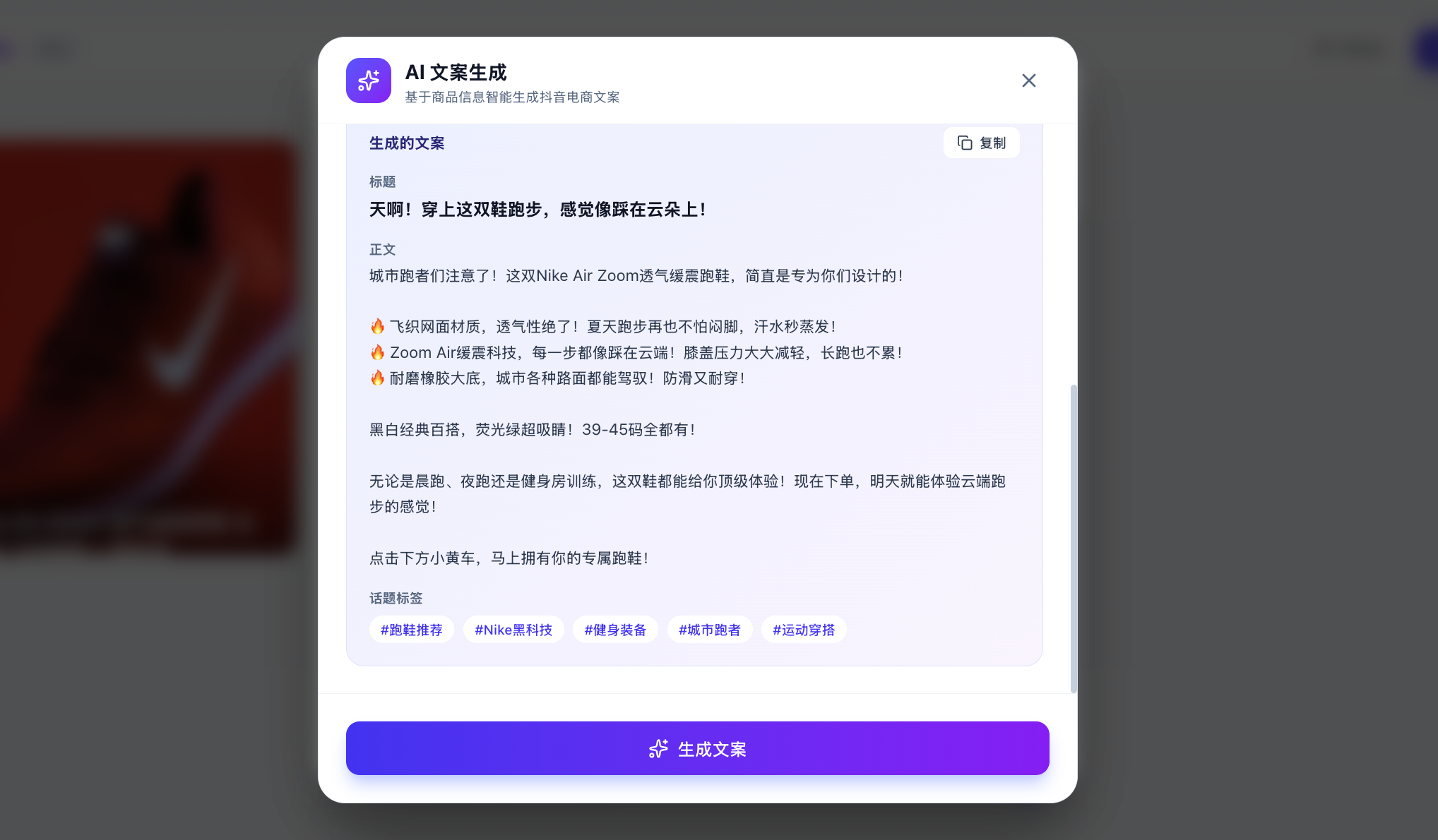
Sie fragen sich vielleicht: Woher weiß ich, ob das große Modell wirklich aufgerufen wurde und nicht nur eine feste Antwort eingebaut ist? Sie können benutzerdefiniertes Copywriting eingeben und das große Modell bitten, basierend auf Ihrer angegebenen benutzerdefinierten Analyse entsprechendes Copywriting zu generieren.
Wenn die Ergebnisse bei jedem Aufruf unterschiedlich, aber logisch sind, können Sie zuversichtlich annehmen, dass die API erfolgreich aufgerufen wird. Sie können auch die API-Nutzungsverwaltungsplattform prüfen, ob der Aufruf erfolgreich war (es kann einige Minuten dauern, bis die Daten angezeigt werden).
Weitere Textgenerierungs-Modelle
Neben DeepSeek können Sie auch andere große Sprachmodelle ausprobieren. Da die meisten Modelle eine OpenAI-kompatible Schnittstelle bieten, ist der Wechsel sehr einfach – nur API Key, Basis-URL und Modellname müssen geändert werden.
MiniMax-Integration
Mehr erfahren: Was ist MiniMax?
MiniMax ist ein chinesisches AI-Unternehmen, das an der Entwicklung allgemeiner KI-Technologie forscht. MiniMax hat die selbstentwickelte MiniMax-M2.7 LLM-Serie auf den Markt gebracht, die in mehreren Benchmarks hervorragende Ergebnisse erzielt und ein exzellentes Preis-Leistungs-Verhältnis bietet.
Hauptmerkmale der MiniMax-M2.7-Serie:
- Ultra-langer Kontext: Unterstützt ein Kontextfenster von 204.800 Tokens, ideal für lange Dokumente und Multi-Runden-Dialoge
- Hervorragendes Preis-Leistungs-Verhältnis: Sehr wettbewerbsfähige Preise
- OpenAI-kompatible Schnittstelle: Direkt mit OpenAI SDK aufrufbar, ohne neues API-Format lernen zu müssen
- Zwei verfügbare Modelle:
MiniMax-M2.7: Flaggschiff-Modell für komplexe AufgabenMiniMax-M2.7-highspeed: Hochgeschwindigkeitsversion mit gleicher Leistung aber schneller
Die Integration erfolgt wie bei DeepSeek in drei Schritten:
- Auf der MiniMax Open Platform registrieren und API Key erstellen
- Aufrufbeispiel in der MiniMax-Dokumentation finden
- API Key + Beispiel in die AI IDE einfügen
Da MiniMax eine OpenAI-kompatible Schnittstelle bietet, können Sie direkt das folgende curl-Beispiel mit Ihrem API Key kopieren und an die AI IDE zur Integration senden:
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.7",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'Hinweis
MiniMax API-Format ist nahezu identisch mit DeepSeek (beide verwenden das OpenAI-kompatible Format). Wenn Sie DeepSeek bereits erfolgreich integriert haben, müssen Sie nur drei Dinge ändern:
- Basis-URL: Ändern zu
https://api.minimax.io/v1 - API Key: MiniMax API Key verwenden
- Modellname: Ändern zu
MiniMax-M2.7oderMiniMax-M2.7-highspeed
Weitere Informationen finden Sie in der MiniMax OpenAI-kompatiblen Schnittstellendokumentation.
3. Bild-zu-Text-API integrieren: Qwen3 VL
Prinzip-Erweiterung
Wenn Sie mehr über die Prinzipien erfahren möchten, siehe Anhang: Visuelle Sprachmodelle (VLM) Einführung.
Mehr erfahren: Was ist Qwen3 VL?
Qwen3 VL ist die neueste Version der multimodalen visuellen Sprachmodellserie, die vom Qwen-Team von Alibaba Cloud entwickelt wurde. VL steht für "Vision-Language", also visuelles Sprachmodell. Es kann Bildinhalte verstehen und basierend auf Bildern Textbeschreibungen generieren, Fragen zu Bildern beantworten und Bildinformationen extrahieren.


Hauptfähigkeiten von Qwen3 VL:
- Bildverstehen: Kann Objekte, Szenen, Personen und Text in Bildern erkennen
- Visuelle Frage-Antwort: Basierend auf Nutzerfragen präzise Antworten zu Bildern geben
- Bildbeschreibung: Detaillierte oder kompakte Textbeschreibungen von Bildern generieren
- Multi-Bild-Verständnis: Unterstützt die gleichzeitige Verarbeitung mehrerer Bilder für Vergleichsanalysen
- Textextraktion: Textinhalte aus Bildern extrahieren (OCR-Fähigkeit)
Warum Qwen3 VL wählen?
Im Vergleich zur vorherigen Generation hat Qwen3 VL die Genauigkeit des Bildverstehens deutlich verbessert und unterstützt längere, komplexere Bildanalyseaufgaben. Es zeichnet sich durch hervorragendes Chinesisch-Verständnis aus, und die API-Aufrufkosten sind relativ niedrig mit einem guten Preis-Leistungs-Verhältnis. Außerdem ist das Kontextfenster größer und kann komplexere visuelle Schlussfolgerungsaufgaben bewältigen.
Typische Anwendungsszenarien:
- E-Commerce: Automatische Generierung von Titeln, Beschreibungen und Selling-Points für Produktbilder
- Content-Erstellung: Automatische Copywriting- oder Bildvorschläge basierend auf Materialbildern
- Büro: Bildinhalts-Extraktion, automatische Berichtserkennung
- Bildung: Automatische Analyse von Bildaufgaben, Extraktion von Wissenspunkten
Im vorherigen Abschnitt haben wir erklärt, wie man eine Textgenerierungs-API integriert. Für unsere Anwendungsszenarien stellen wir jedoch ein Problem fest: Wir laden ein Bild hoch, und wenn wir nur ein großes Sprachmodell verwenden, kann es den Bildinhalt nicht gut verstehen, was zu abweichenden Ergebnissen führen kann.
Wir möchten ein Modell, das uns hilft, ein Bild in eine Textbeschreibung umzuwandeln. Dafür benötigen wir ein visuelles Sprachmodell (VLM). In unserem Beispiel werden wir das visuelle Sprachmodell verwenden, um Selling-Point-Beschreibungen für Produkte zu generieren und die Nutzererfahrung zu verbessern.
Der Einfachheit halber verwenden wir die API-Schnittstelle der SiliconFlow Cloud-Plattform für die Integration der Bild-zu-Text-API.
Mehr erfahren: Was ist SiliconFlow?
SiliconFlow ist eine bekannte inländische AI-Modell-Aggregationsplattform, die API-Schnittstellendienste für verschiedene gängige große Sprachmodelle und visuelle Sprachmodelle anbietet.
Plattform-Features:
- Multi-Modell-Unterstützung: Integriert verschiedene gängige AI-Modelle, einschließlich Open-Source-Modelle wie DeepSeek, Qwen, Llama-Serie usw.
- Technologische Optimierung: Inferenzoptimierung für Open-Source-Modelle mit API-Diensten für niedrige Latenz und hohe Parallelität
- Schnittstellenkompatibilität: Bietet eine mit dem OpenAI-Format kompatible API-Schnittstelle für einfache Integration in bestehende Anwendungen
- Nutzungsabhängige Abrechnung: Unterstützt nutzungsabhängige Abrechnung nach API-Aufrufen
SiliconFlow ist im Bereich der Inferenzdienste für Open-Source-Großmodelle relativ etabliert und eine der gängigen Optionen für die Nutzung inländischer Open-Source-AI-Modelle.
Auf der Startseite der SiliconFlow-Plattform sehen wir viele verfügbare Modelle. Finden Sie den Filter oben links, klicken Sie, um den Filter zu öffnen, und wählen Sie das Tag "Vision". Wir sehen dann viele Bild-zu-Text-Modelle, wie z.B. Zhipu GLM-4.6V oder Qwen3-VL.
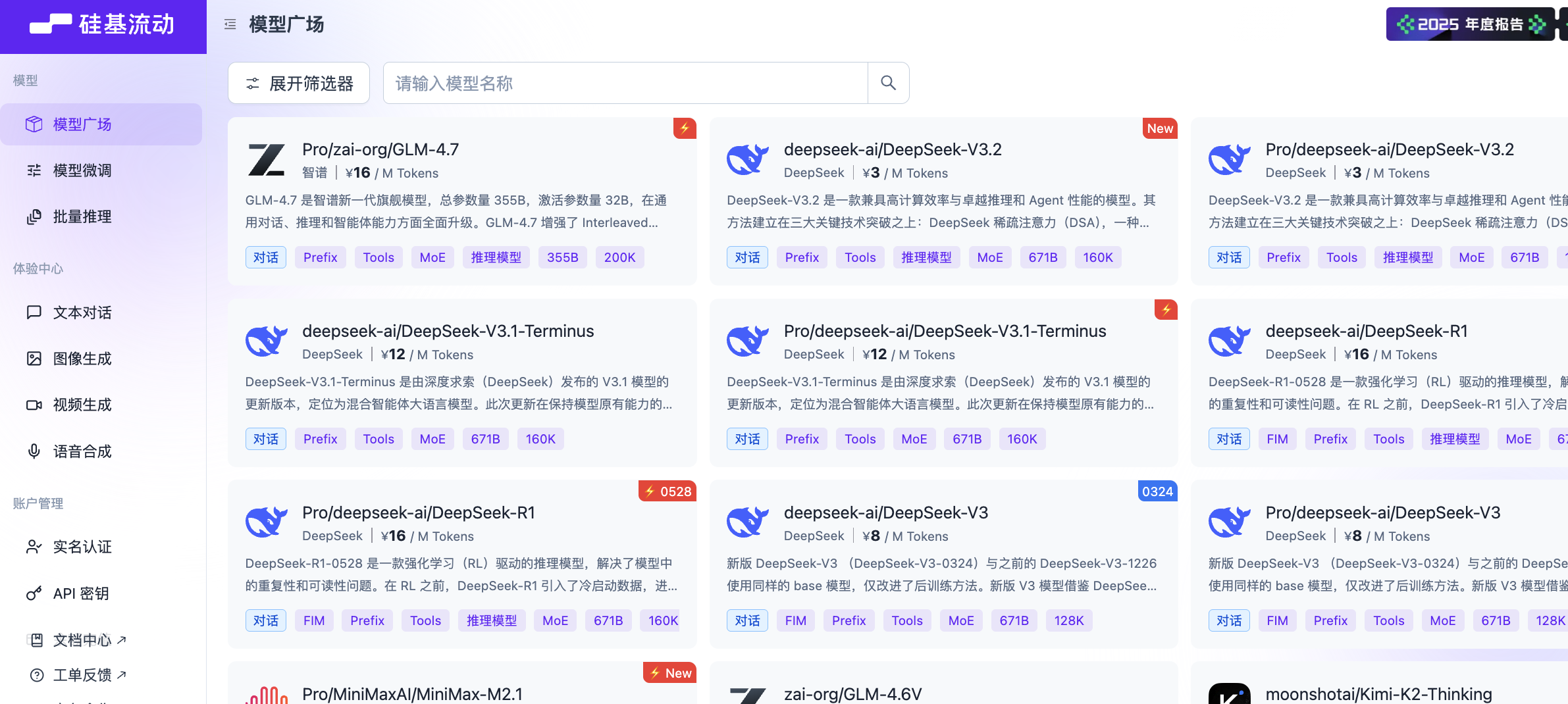
Wir können ein beliebiges Modell zum Testen auswählen. Hier verwenden wir Qwen/Qwen3-VL-8B-Instruct als Beispiel.
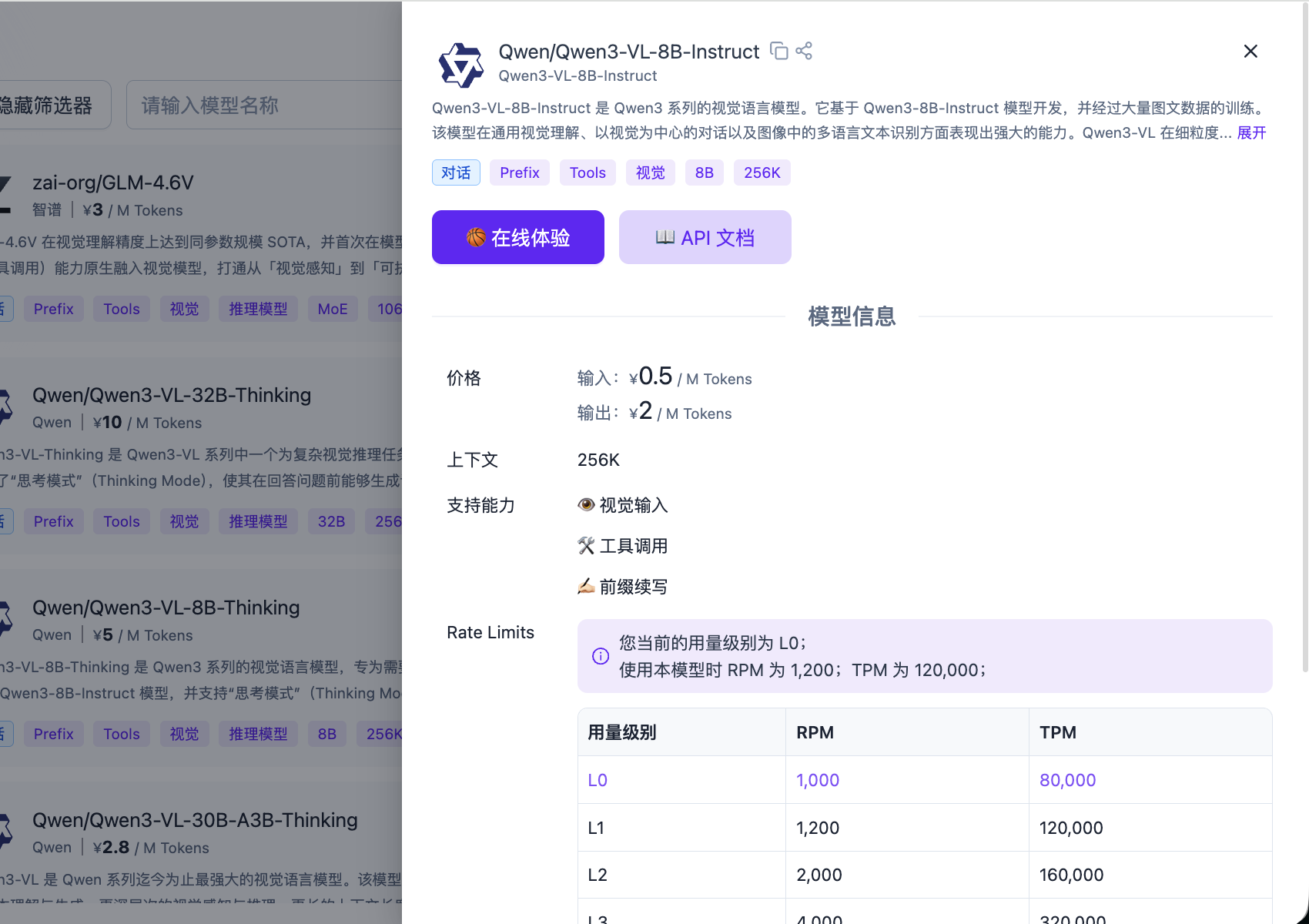
Gehen Sie zur SiliconFlow-Plattform, klicken Sie unter API-Schlüssel auf "Neuen API-Schlüssel erstellen", um einen neuen API Key zu erstellen.
Sie können den folgenden Code als Referenzcode verwenden und ihn zusammen mit dem generierten API Key an die AI IDE senden, um die Funktionsintegration durchzuführen.
Bild-zu-Text-Referenzcode
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
caption = caption_image(image_path)In diesem Szenario lassen wir AI IDE direkt helfen, die Funktion zum automatischen Generieren von E-Commerce-Selling-Point-Texten und Keywords aus hochgeladenen Bildern zu implementieren, wie folgt:
Basierend auf der folgenden Bild-zu-Text-API, hilf uns, eine Funktion zu implementieren,
die aus hochgeladenen Bildern automatisch E-Commerce-Selling-Point-Texte und Keywords generiert.
<Code hier ausgelassen, Sie müssen den Schlüssel und den Referenzcode selbst einfügen>Schließlich erhalten wir das Generierungsergebnis: 
4. Bildgenerierungs-API integrieren: Seedream
In den vorherigen Abschnitten haben wir hauptsächlich mit textbezogenen Aufgaben gearbeitet. Als Nächstes werden wir die Integration der Bildgenerierungsfunktion ausprobieren, die die Generierung von Bildern aus Textbeschreibungen oder die Bearbeitung von Bildern unterstützt.
Prinzip-Erweiterung
Wenn Sie mehr über die Prinzipien erfahren möchten, siehe Anhang: Bildgenerierung Einführung.
Mehr erfahren: Was ist Seedream?

Vielleicht kennen Sie bereits Nano Banana (von Google entwickelt), aber Sie sollten Seedream nicht verpassen. Seedream 4.5 ist ein neues Bildgenerierungsmodell von ByteDance. Es integriert Bildgenerierung und Bildbearbeitungsfähigkeiten in einer einheitlichen Architektur. Dies ermöglicht die flexible Bearbeitung komplexer multimodaler Aufgaben wie wissensbasierte Generierung, komplexes Schlussfolgern und Referenzkonsistenz. Außerdem ist die Inferenzgeschwindigkeit deutlich schneller als bei der Vorgängerversion, und es kann hochauflösende Bilder mit bis zu 4K-Auflösung generieren.


Hauptfähigkeiten:
- Text-zu-Bild: Bilder aus Textbeschreibungen generieren, unterstützt verschiedene Stile (realistisch, Cartoon, Tuschmalerei, Cyberpunk usw.)
- Stiltransfer: Ein Bild in einen bestimmten Kunststil umwandeln
- Bildvarianten: Neue Bilder im ähnlichen Stil basierend auf einem Referenzbild generieren
- Auflösungsverbesserung: Bildklarheit und Details verbessern
- Bildbearbeitung: Bestehende Bilder durch natürlichsprachliche Anweisungen bearbeiten und verändern
Warum Seedream wählen?
- Stabiles Inlandsnetzwerk: Schnelle Zugriffszeiten im Inland, niedrige Latenz
- Hervorragende Ergebnisse: Stabile und zuverlässige Leistung in E-Commerce- und Material-Szenarien
- Chinesisch-Optimierung: Genaueres Verständnis für chinesische Prompts, geeignet für inländische Nutzer
- Hohe Geschwindigkeit: Hohe Generierungseffizienz, kurze Antwortzeiten
- Stabile Qualität: Generierung hochauflösender Bilder bis zu 4K
Typische Anwendungsszenarien:
- E-Commerce: Hauptbilder, Detailseiten-Illustrationen, Werbeplakate generieren
- Social Media: Avatare, Memes, Illustrationen generieren
- Design: Schnelle Konzeptbilder, Materialbilder, Hintergrundbilder erstellen
- Marketing: Werbebilder, Event-Banner, Festtagsplakate erstellen
Kombination mit Qwen3 VL:
Diese beiden APIs können in Reihe geschaltet werden: Zuerst Qwen3 VL verwenden, um ein Referenzbild zu analysieren und den Bildinhalt zu verstehen; dann Seedream verwenden, um basierend auf den analysierten Prompts des Referenzbildes neue Bilder zu generieren.
Viele "AI-Plakate / AI-Hauptbilder / AI-Charakterbilder", die Sie möglicherweise auf Douyin, Bilibili oder YouTube sehen, nutzen im Wesentlichen die in diesem Abschnitt vorgestellte Technik. Was Sie tun müssen, ist einfach: Die Nutzereingabe zu einem Satz zusammenfassen, die Bild-API anfragen und das zurückgegebene Bild anzeigen. Das hier verwendete Modell wird als Bildgenerierungs-/Bildbearbeitungsmodell bezeichnet.
Wir werden schrittweise demonstrieren, wie Sie die Seedream API in Ihr Projekt integrieren (mit Unterstützung durch AI IDE).
Nachdem Sie die Startseite aufgerufen haben, klicken Sie auf Anmelden.
Nach der Anmeldung finden Sie die Aufladeoption oben rechts auf der Seite.
Für die Aufladung ist eine Identitätsverifizierung erforderlich.
Nach erfolgreicher Verifizierung können Sie 1 Yuan zum Testen aufladen.
Kehren Sie zur ursprünglichen Seite zurück und klicken Sie auf API-Zugriff.
Erstellen Sie zunächst einen API Key und klicken Sie dann auf die Auswahloption.
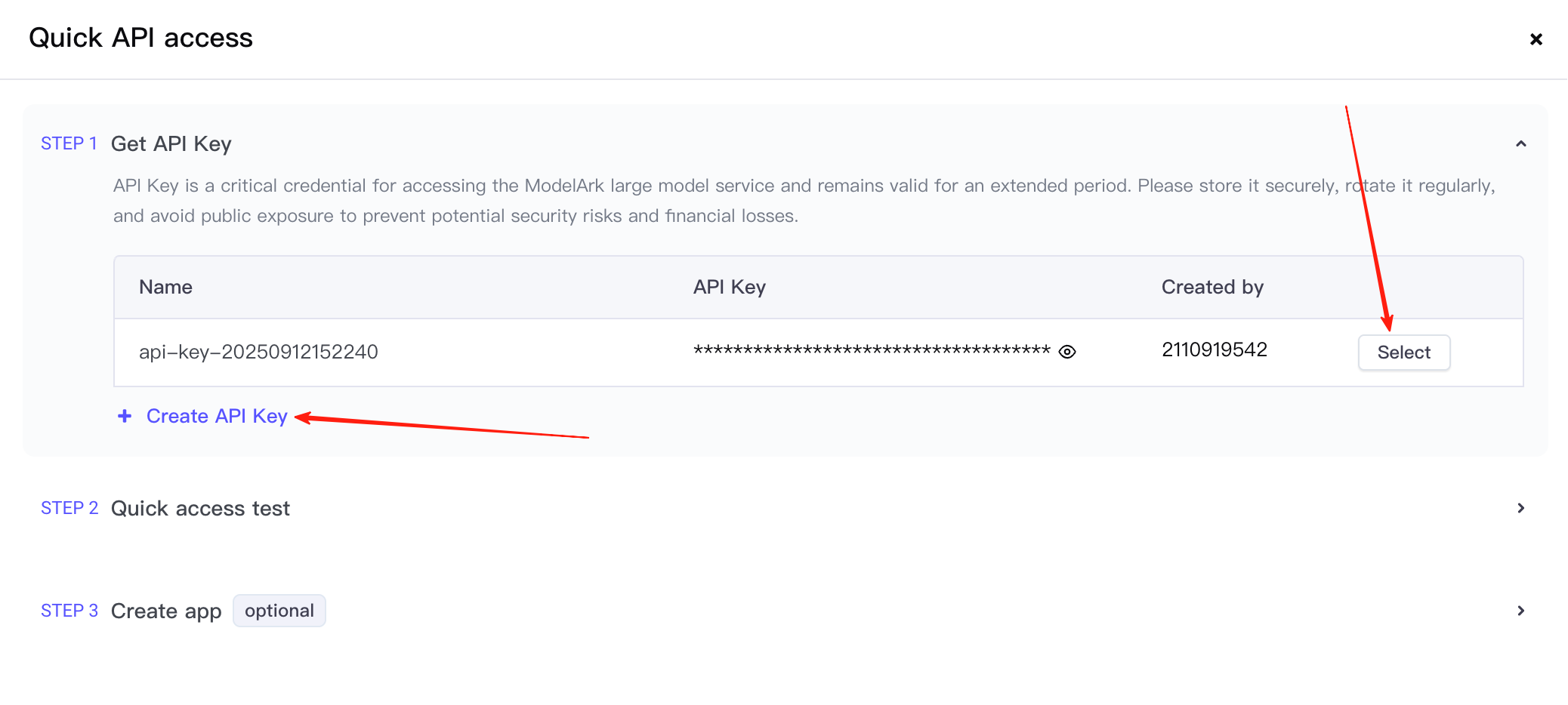
Dies bringt Sie zu Schritt 2. Hier müssen Sie bestätigen, dass der aufgerufene Dienst Seedream 4.5 ist, und das bereitgestellte Aufrufbeispiel kopieren. (Der Screenshot wurde früher erstellt, daher ist die Modellversion noch 4.0.)
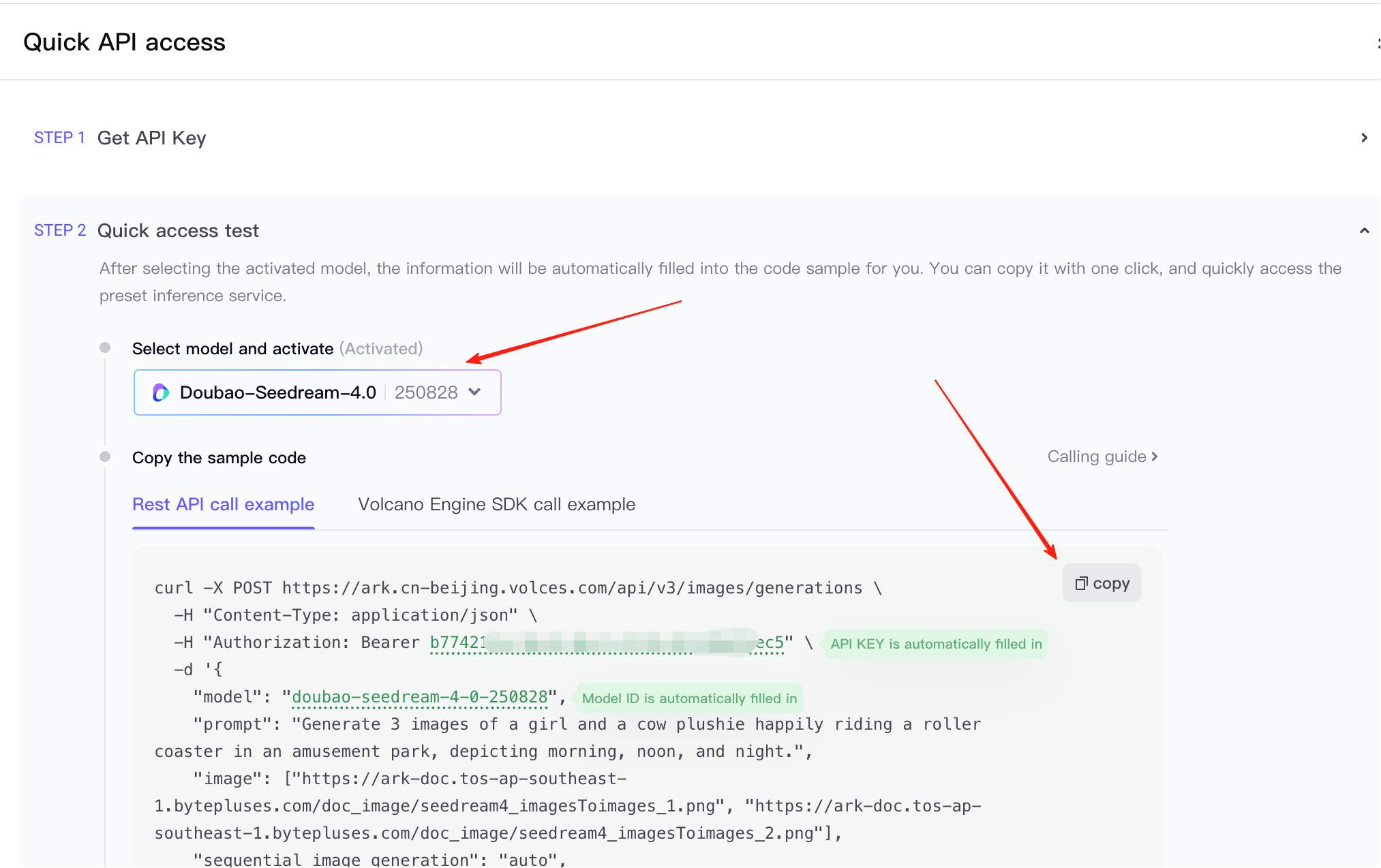
Nachdem Sie den API Key und das Aufrufbeispiel vorbereitet haben, können Sie diese direkt in die AI IDE einfügen und eine Frontend-Interaktionsdemo generieren lassen oder die Fähigkeit in einen bestehenden Prototypen integrieren. Beachten Sie, dass Sie im Bild auswählen können, ob Sie Text-zu-Bild oder Mehrere-Bilder-zu-einem-Bild verwenden möchten. Sie müssen den Referenzcode entsprechend Ihren aktuellen Anforderungen auswählen.
Wichtiger Hinweis
Das Standardbeispiel hier ist relativ komplex. Denken Sie daran, "Wasserzeichen hinzufügen" und "Streaming-Antwort" zu deaktivieren, um sicherzustellen, dass kein Wasserzeichen generiert wird und keine Anfragefehler auftreten.
Da wir später den Referenzbild-Generierungsmodus verwenden, wählen wir zunächst die Funktion Mehrere-Bilder-zu-einem-Bild. Der kopierte Referenzcode sieht wie folgt aus:
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "Ersetze die Kleidung in Bild 1 durch die Kleidung in Bild 2",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'Mit dem Bildreferenzcode lassen wir AI IDE gängige Bildaufgaben im E-Commerce unterstützen:
Bitte basierend auf der folgenden API hilf mir, die gängigen Funktionen im E-Commerce-Geschäft zu implementieren
(z.B. Plakatgenerierung, Douyin E-Commerce-Hauptbild-Generierung usw.)
<Hier API KEY und Bildbearbeitungscode einfügen>Das Ergebnis sieht wie folgt aus:
Es ist erwähnenswert, dass die Bildgenerierung oft zu seltsamen Problemen führen kann. Es wird empfohlen, AI IDE so einzustellen, dass es vollständige Fehlermeldungen anzeigt, um das Kopieren und Einfügen für Korrekturen zu erleichtern (andernfalls wird möglicherweise wiederholt "Generierung fehlgeschlagen" angezeigt, ohne dass klar ist, warum). Zum Beispiel können Sie sagen:
Zeige nicht nur "Bildgenerierung fehlgeschlagen", sondern zeige jedes Mal den vollständigen Fehlergrund,
wie z.B. Bildinkompatibilität, Anfragefehler, Timeout usw.!Manchmal werden Aktualisierungen nach einer Änderung nicht auf der Webseite angewendet. Wenn Sie feststellen, dass die Webseite nach einer Änderung weiterhin Fehler anzeigt (mehrmals hintereinander), können Sie auch versuchen, AI IDE direkt zu sagen: Bitte starten Sie dieses Projekt neu.
Im E-Commerce-Geschäft möchten wir möglicherweise, dass Nutzer hochgeladene Kleidung automatisch auf einer Person tragen können, oder automatisch attraktive Verkaufsimages und Plakate für Produkte generieren. Hier probieren wir einen Prompt aus, um ein E-Commerce-Plakat zu generieren:
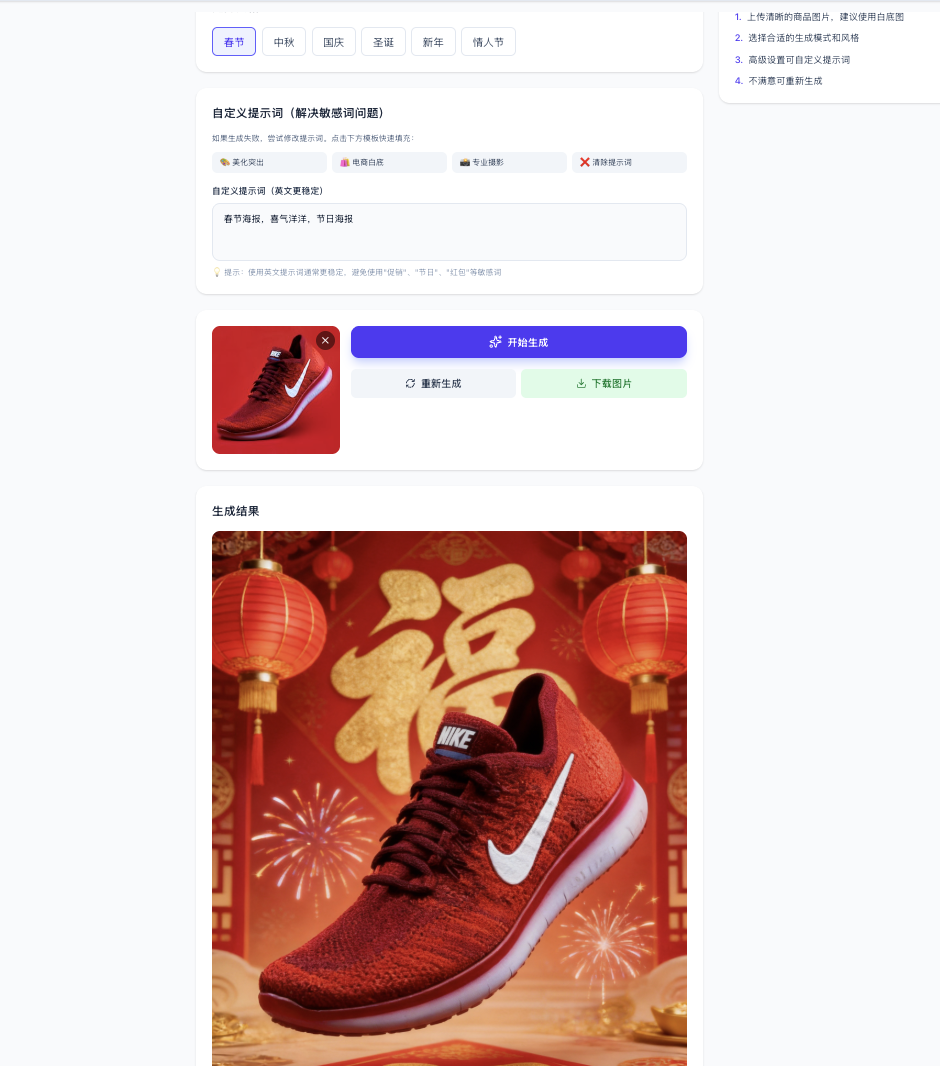
Sie können je nach Ihren eigenen Geschäftsszenarien die Text-zu-Bild- oder Bild-zu-Bild-API verwenden, um verschiedene Funktionen zu implementieren.
Weitere Bildgenerierungsdienste
Nachfolgend finden Sie weitere Optionen. Es wird empfohlen, zunächst die Qwen-Bildgenerierung erfolgreich zum Laufen zu bringen und dann basierend auf Ergebnissen und Kosten die folgenden Dienste als Ersatz auszuprobieren (wählen Sie nach persönlichem Erfahrungseindruck).
Recraft-Integration
Wenn Ihr Prototyp eher in Richtung "Design-Produktion" geht (z.B. Generierung von Marken-Stil-Illustrationen, Marketing-Plakaten, Vektor-Stil-Materialien), ist Recraft oft die bessere Wahl. Die Integration erfolgt genau wie im vorherigen Abschnitt: Key besorgen + offizielles Beispiel finden + AI IDE das Beispiel in Ihren Button/Ihre Seite integrieren lassen.
Mehr erfahren: Was ist Recraft?
Recraft ist ein AI-Tool für Designer, Illustratoren und Vermarkter – 2022 in den USA gegründet, mit Hauptsitz in London. Es hilft bei der Generierung/Iteration von visuellen Elementen (Bilder, Vektorgrafiken, 3D-Grafiken) mit Vorteilen wie hochwertiger Ausgabe (jede Textgröße/-länge), präziser Elementplatzierung und markenkonsistentem Design. Vertraut von über 3 Millionen Nutzern in 200 Ländern (einschließlich Ogilvy, Netflix) und über 350 Millionen generierten Bildern. Das Team zielt darauf ab, es zu einem unverzichtbaren Designer-Tool zu machen und sicherzustellen, dass Creator ihre AI-gestützten Workflows kontrollieren können.


Zunächst müssen wir den API-Zugang finden, um den API Key zu erhalten.
Da hier kein kostenloses Kontingent bereitgestellt wird, müssen wir 1.000 Credits selbst aufladen. Diese Website unterstützt Alipay und WeChat Pay, sodass es einfach ist, 1.000 Credits zu erhalten (Hinweis: Nicht mehr als notwendig aufladen).

Danach folgen wir weiterhin derselben Methode: Zur offiziellen Dokumentation gehen und die entsprechenden Anfragebeispiele finden:
Qwen Image / Qwen Image Edit Integration
Wenn Sie einen einfacheren Weg zur Integration eines Bildgenerierungsdienstes bevorzugen, können Sie Qwen Image (Tongyi Wanxiang) in Betracht ziehen. Der Ansatz bleibt derselbe: Behandeln Sie es als "Bildgenerierungs-API" und binden Sie es an den Button Ihres Prototyps an.
Mehr erfahren: Was ist Qwen Image / Qwen Image Edit?
Qwen Image (auch bekannt als Tongyi Wanxiang) ist eine Bildgenerierungsmodellserie des Qwen-Teams von Alibaba Cloud, die hauptsächlich zwei Modelle umfasst:
1. Qwen Image — Text-zu-Bild-Modell
Generiert basierend auf Textbeschreibungen völlig neue Bilder. Sie geben einen Prompt ein, das Modell versteht Ihre Absicht und generiert ein Bild, das der Beschreibung entspricht.

Hauptfähigkeiten:
- Text-zu-Bild: Bilder aus Textbeschreibungen generieren, unterstützt verschiedene Stile (realistisch, Cartoon, Tuschmalerei, Cyberpunk usw.)
- Stiltransfer: Ein Bild in einen bestimmten Kunststil umwandeln
- Bildvarianten: Neue Bilder im ähnlichen Stil basierend auf einem Referenzbild generieren
- Auflösungsverbesserung: Bildklarheit und Details verbessern
2. Qwen Image Edit — Bild-zu-Bild-Modell
Bearbeitet und verändert bestehende Bilder. Durch natürlichsprachliche Anweisungen versteht das Modell Ihre Änderungsabsicht und generiert das Ergebnis.
Hauptfähigkeiten:
- Lokaler Austausch: Ein bestimmtes Objekt oder eine Person im Bild ersetzen (z.B. "Hintergrund zum Strand ändern")
- Elemententfernung: Unerwünschte Elemente aus dem Bild entfernen
- Stiltransfer: Filter oder künstlerische Effekte auf das Bild anwenden
- Bilderweiterung: Bildränder erweitern und neue Inhalte generieren
- Intelligente Bildbearbeitung: Automatische Verschönerung, Lichtanpassung, Fehlerkorrektur



Warum die Qwen Image Serie wählen?
- Chinesisch-Optimierung: Genaueres Verständnis für chinesische Prompts, geeignet für inländische Nutzer
- Niedrige Kosten: Im Vergleich zu internationalen Wettbewerbern erschwinglicher
- Hohe Geschwindigkeit: Hohe Generierungseffizienz, kurze Antwortzeiten
- Stabile Qualität: Stabile und zuverlässige Leistung in E-Commerce- und Material-Szenarien
- Vielfältige Stile: Unterstützt verschiedene Kunststile und kreative Effekte
Typische Anwendungsszenarien:
- E-Commerce: Hauptbilder, Detailseiten-Illustrationen, Werbeplakate generieren
- Social Media: Avatare, Memes, Illustrationen generieren
- Design: Schnelle Konzeptbilder, Materialbilder, Hintergrundbilder erstellen
- Marketing: Werbebilder, Event-Banner, Festtagsplakate erstellen
Besuchen Sie die offizielle Website von SiliconFlow. Auf der linken Seite gibt es einen "Playground"-Bereich, in dem Sie verschiedene Modelle ohne API-Aufruf ausprobieren können. Oben auf der Seite gibt es einen "Filters"-Button; klicken Sie darauf, um die Modellliste auf der rechten Seite zu filtern.
Wenn Sie "Image" auswählen, sehen Sie nur die aktuell unterstützten Text-zu-Bild-Modelle. In diesem Fall verwenden wir Qwen/Qwen-Image.
Nachdem alles eingerichtet ist, müssen wir die entsprechende Bildgenerierungs-API-Dokumentation konsultieren. Sie können auf der offiziellen Dokumentationsseite jeden Abschnitt finden, der als "API Reference" markiert ist. Klicken Sie darauf und navigieren Sie zum API-Bereich für Bildgenerierung, um das entsprechende Anfragebeispiel zu finden.
Sie können das folgende Anfragebeispiel zusammen mit dem API Key an die AI IDE senden, um die Bildgenerierungsfunktion zu implementieren.
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'Hier können Sie entweder Qwen/Qwen-Image oder Qwen/Qwen-Image-Edit-2509 als Modell verwenden.
Bildbearbeitungs-Referenzcode
Kopieren Sie den folgenden Code zusammen mit dem Key und senden Sie beides an AI IDE:
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "Verwandle den Himmel in eine Abendstimmung mit Mond und Sternen, im traumhaften Stil"
negative_prompt: str = "verschwommen, niedrige Qualität, verzerrt"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")Anhang: Wie man "aktuell stärkere" AI-Modelle findet
Die Entwicklung von Textmodellen (auch oft als "große Sprachmodelle" bezeichnet) verläuft sehr schnell. Wir müssen immer sicherstellen, dass wir eines der leistungsstärkeren Modelle verwenden. Über die folgenden zwei Websites können Sie bequem sehen, "welche Modelle aktuell häufig verwendet und besser bewertet werden".
Im Allgemeinen können diese Websites als "Modell-Arenen" verstanden werden: Sie stellen die Ausgaben zweier Modelle nebeneinander, und Sie stimmen für diejenige, die Ihnen besser gefällt. Modelle mit mehr Stimmen bedeuten in der Regel, dass mehr Menschen sie "besser" finden.
Darüber hinaus sehen Sie möglicherweise gelegentlich mysteriöse anonyme Modelle ("Unknown Model") in diesen Großmodell-Arenen. Dies bedeutet normalerweise: Jemand hat ein "internes Testmodell" für Blindtests eingeschleust, und Sie haben möglicherweise die Chance, stärkere Fähigkeiten vorab zu erleben.
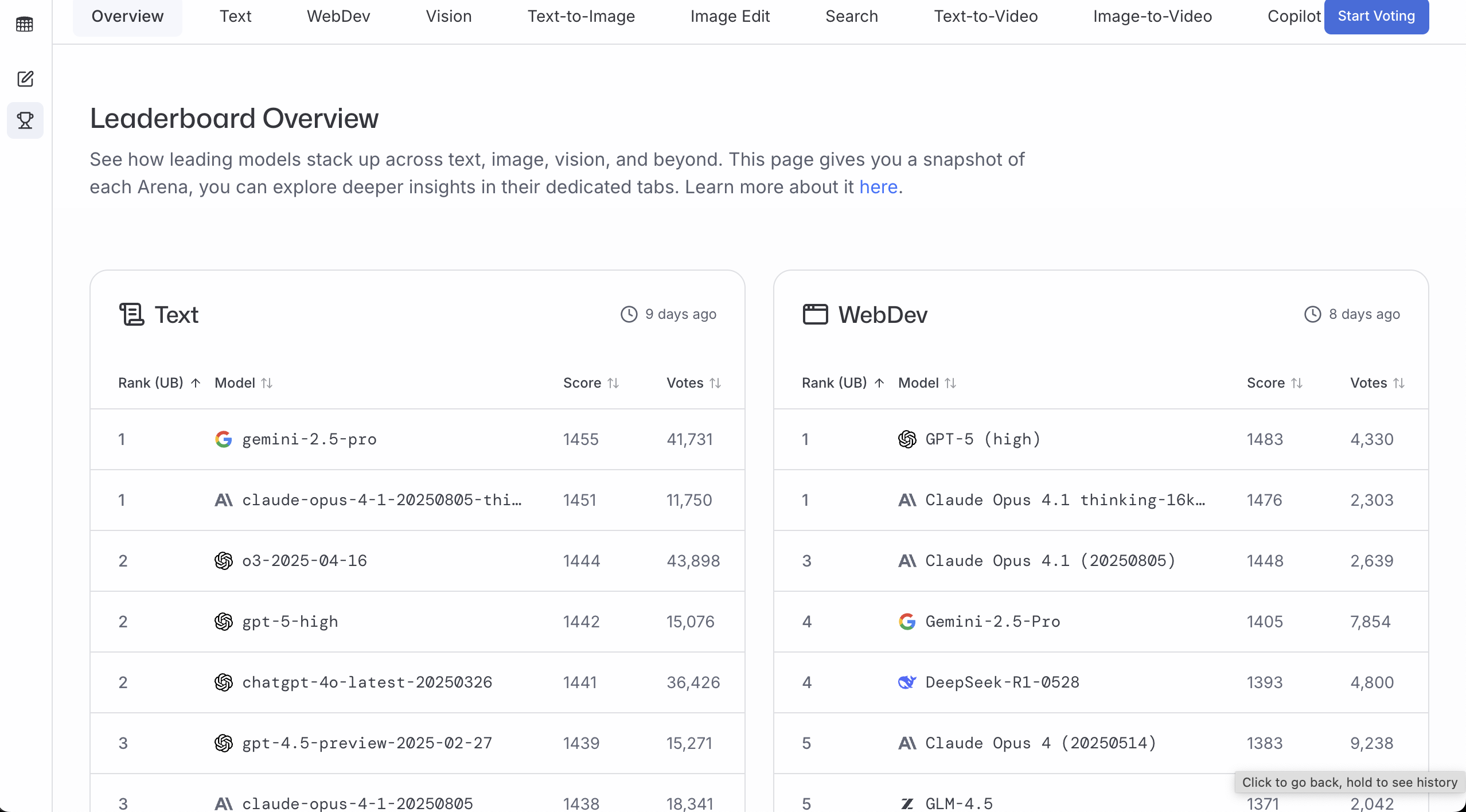
LMArena
Website: https://lmarena.ai/
LMArena eignet sich besser dafür zu beurteilen, "welches Modell die meisten Nutzer bevorzugen". Mehr Stimmen und höhere Scores bedeuten in der Regel, dass es in realen Anwendungsszenarien stabiler ist.
Eine einfache Nutzung:
- Direkt das Leaderboard ansehen
- Zunächst eine Richtung wählen (z.B. allgemeiner Dialog / Programmierung / Vision)
- Wählen Sie eines der Top 3, das Sie nutzen können (zugänglich, Preis akzeptabel, Latenz akzeptabel)
Artificial Analysis
Website: https://artificialanalysis.ai/
Artificial Analysis eignet sich besser dafür, "Leistung / Preis / Geschwindigkeit" in einer Tabelle zu vergleichen. Sie können es als Parametertabelle für die Modellauswahl verwenden.
Typische Nutzung:
- Finden Sie die Modellkategorie, die Sie interessiert (Text / Bildgenerierung usw.)
- Qualitätsindikatoren (Quality) + Preis (Price) + Latenz/Durchsatz (Latency/Throughput) vergleichen
- Wählen Sie das Modell mit dem besten "Gesamtpreis-Leistungs-Verhältnis" für Ihr Produkt
Empfehlung
Verlassen Sie sich nicht auf Ihr Bauchgefühl, um zu argumentieren, "welches besser ist". Ein zuverlässigerer Ansatz: Testen Sie 2-3 Modelle gleichzeitig mit denselben Eingaben und treffen Sie dann Ihre Entscheidung basierend auf dem Ranking und den Preisen.
Zusammenfassung
Bei der Integration verschiedener AI-Dienste müssen Sie APIs nicht als zu kompliziert betrachten. Wenn Sie die folgenden Kernkonzepte beherrschen, können Sie die meisten Szenarien bewältigen:
Eine API ist im Kern eine Kommunikationsbrücke. Was sie tut, ist einfach: Ihre Anfrage senden und die Antwort des Modells zurückbringen. Sie müssen sich nicht um das kümmern, was im Hintergrund passiert, sondern nur das Anfrageformat korrekt zusammenstellen.
Ein SDK ist eine Kapselung der API. Wenn API die rohe Schnittstelle ist, dann ist ein SDK ein fertiges Werkzeugkasten – es übernimmt die mühsamen Details wie Anfragesignaturen, Fehlerbehandlung und Parametervalidierung für Sie. Im täglichen Entwicklungsalltag sollten Sie SDKs gegenüber direkten API-Aufrufen bevorzugen, um sich viel Mühe zu sparen.
Beim Lesen der Dokumentation genügt es, auf drei Dinge zu achten: Die Dienstadresse (Endpoint), die Anmeldeinformationen (API Key) und wie die Aufrufparameter ausgefüllt werden. Wenn Sie diese drei Punkte geklärt haben, ist es nur eine Frage der Zeit, bis der Aufruf funktioniert.
Die restliche Arbeit erledigen IDEs und moderne Entwicklungstools für Sie. Konzentrieren Sie sich auf Ihre Geschäftslogik und überlassen Sie die zugrunde liegenden Aufrufe diesen ausgereiften SDKs und Toolchains.
5. Hausaufgabe: Ihre erste AI-Fähigkeit integrieren
Beziehen Sie sich auf die Prompts und Inhalte dieser Lektion und schließen Sie einen vollständigen Zyklus ab:
- Vollständiger Praxis-Zyklus
- Wählen und integrieren Sie einen AI-Dienst (LLM / Text-zu-Bild / Bild-zu-Bild) → Frontend-Backend-Interaktion implementieren → In Ihren Prototypen integrieren
- Ergebnisse teilen
- Machen Sie Screenshots Ihrer Funktionsseite und teilen Sie sie mit allen
- Denkaufgabe
- Bereiten Sie sich auf das nächste Kapitel "Vollständiges Projektpraktikum" vor, indem Sie im Voraus überlegen: Wie möchten Sie diese AI-Fähigkeiten kombinieren, um interessante Funktionen zu schaffen?
Nächste Schritte
Im nächsten Kapitel werden wir diese verteilten AI-Fähigkeiten verketten und in einem realen Geschäftsszenario ein vollständiges Produkt erstellen:
- Content-Planung, Produkteinstellung, Datenanalyse und andere Schritte zu einem vollständigen Geschäftsprozess verketten
- Die in dieser Lektion gelernten AI-Fähigkeiten (LLM-Copywriting-Generierung, Text-zu-Bild, Bildbearbeitung usw.) in tatsächliche Geschäftsknotenpunkte einbetten
- Einen wirklich nutzbaren "E-Commerce AI Workspace" erstellen, keine isolierte Demo