Module 4 : Injecter des capacités IA dans votre prototype
Introduction au chapitre
1. Concepts de base des API
Comme mentionné précédemment, notre objectif est « d'intégrer les capacités IA », pour que le prototype ne soit plus une démonstration statique, mais un outil capable d'appeler de vrais services IA. Pour réaliser cela, la clé est de comprendre et d'utiliser les API (Application Programming Interface).
L'API est un concept d'abstraction important en informatique, que l'on peut comprendre simplement comme : vous envoyez une « question » dans le format requis, et l'autre partie vous renvoie un « résultat » dans le même format.
- Ce que vous envoyez : généralement inclut la « clé (API Key) » et « ce que vous voulez générer »
- Ce que vous recevez en retour : en cas de succès, le résultat ; en cas d'échec, la raison (par exemple « clé incorrecte », « solde insuffisant », « paramètre erroné »)
Concrètement, vous devez maîtriser les éléments clés suivants :
- API Key : votre « passe », aussi votre « clé de portefeuille ». Si quelqu'un d'autre l'obtient, il peut utiliser l'API en votre nom et engendrer des frais.
- Endpoint (chemin de l'interface) : le chemin spécifique de la requête API, indiquant au serveur quelle fonctionnalité vous souhaitez accéder. L'adresse complète se compose généralement du « URL de base + chemin de l'endpoint ». Par exemple :
- Génération de texte : URL de base (
https://api.service.com) + Endpoint (/v1/chat/completions) = URL complètehttps://api.service.com/v1/chat/completions - Génération d'images : URL de base (
https://api.service.com) + Endpoint (/v1/images/generations) = URL complètehttps://api.service.com/v1/images/generations
- Génération de texte : URL de base (
- Appel/Requête : le processus d'envoi d'une tâche au service IA et d'obtention du résultat
- Contenu de la requête : ce que vous envoyez à l'IA, comme le sujet de l'article que vous voulez générer ou la description de l'image
- Réponse : ce que l'IA vous renvoie après traitement, comme l'article généré ou l'image
- Gestion des erreurs : savoir comment diagnostiquer et résoudre les problèmes (API Key incorrecte, requêtes trop fréquentes, etc.)
ℹ️ Qu'est-ce qu'une API
Pour une explication plus approfondie des API, consultez l'annexe : Introduction aux API.
🔐 Consignes de sécurité des API
L'API Key est votre « passe » pour accéder aux services IA. C'est une chaîne de caractères de type mot de passe, utilisée pour l'authentification et la facturation.
Puisque l'API Key est directement liée à votre compte et à vos frais, veillez à :
- Ne jamais la partager dans des chats, des captures d'écran publiées en ligne ou des forums publics
- Ne pas la coder en dur dans le code et la committer dans un dépôt Git (surtout un dépôt public)
- Si vous soupçonnez que la Key a été compromise, changez-la immédiatement
Dans ce qui suit, nous allons directement coller l'API KEY dans l'AI IDE pour les opérations. Ne faites pas ça dans un vrai projet !! Comme nous sommes en phase d'apprentissage, c'est acceptable. (Quand vous serez plus expérimenté, vous pourrez demander à l'IA de générer un fichier de configuration dans lequel vous placerez simplement l'API KEY)
2. Intégrer l'API de génération de texte : DeepSeek
Bien que les API impliquent des concepts techniques, la phase de développement de prototype peut être très simple et efficace. L'idée centrale est :
Trouver l'exemple officiel, obtenir l'API Key, demander à l'AI IDE de l'intégrer à votre bouton.
Une fois ces concepts maîtrisés, vous découvrirez que le processus est le même pour l'intégration de modèles de texte ou d'images : quand l'utilisateur clique sur un bouton, le frontend organise l'entrée et envoie la requête ; quand l'interface renvoie le résultat, il l'affiche sur la page. Voyons cela en pratique.
Dans la section 1.2, vous avez déjà créé un prototype interactif. Ce que nous allons faire maintenant, c'est transformer les « fonctionnalités qui ressemblent à de l'IA » en véritables capacités : quand l'utilisateur clique sur un bouton, le prototype envoie une requête à un service IA externe et affiche le texte renvoyé.
ℹ️ Pour aller plus loin sur les principes
Si vous voulez en savoir plus sur les principes, consultez l'annexe : Introduction aux grands modèles de langage (LLM).
Pour en savoir plus : Qu'est-ce que DeepSeek ?
Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., commercialisée sous le nom de DeepSeek, est une entreprise chinoise d'intelligence artificielle (IA) qui développe des grands modèles de langage (LLM). DeepSeek est basée à Hangzhou, dans la province du Zhejiang, et est détenue et financée par le fonds quantitatif chinois High-Flyer. DeepSeek a été fondée en juillet 2023 par Liang Wenfeng, cofondateur de High-Flyer, qui est également PDG des deux entreprises. L'entreprise a lancé son chatbot éponyme et son modèle DeepSeek-R1 en janvier 2025.
Regardons les performances de DeepSeek dans le classement GPQA par rapport à d'autres modèles de premier plan. Il est à noter que DeepSeek est un modèle open source (tout le monde peut télécharger le modèle depuis Internet), alors que d'autres modèles courants comme Grok, Google Gemini et ChatGPT sont propriétaires. Comme on peut le voir, DeepSeek s'est considérablement rapproché des modèles de premier rang.
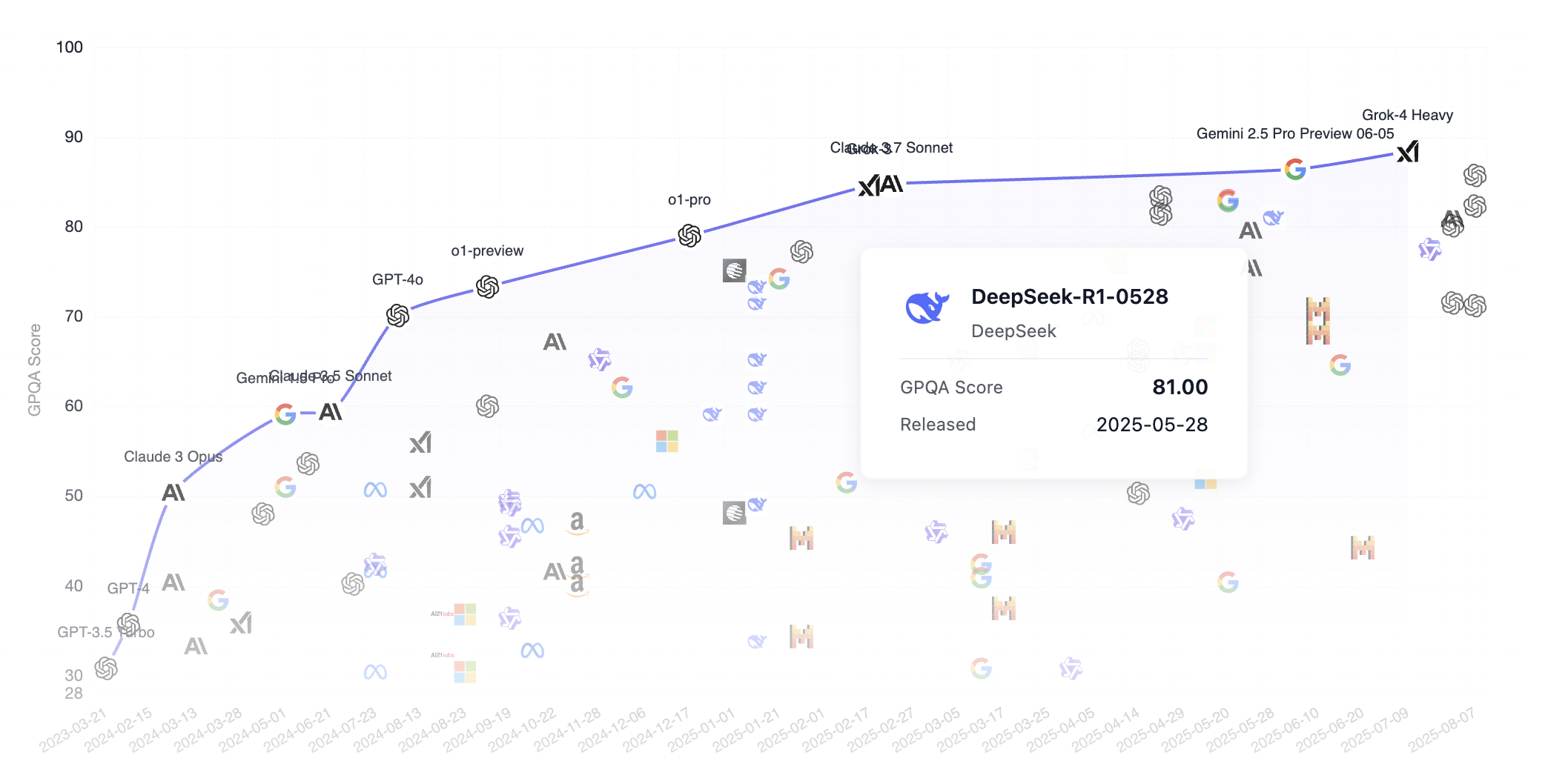
GPQA signifie « Graduate-Level Google-Proof Question Answering benchmark », un benchmark de niveau graduate pour les tâches de Q&R scientifiques.
GPQA contient 448 questions à choix multiples couvrant les sous-domaines de la biologie, de la physique et de la chimie, tels que la mécanique quantique, la chimie organique, la biologie moléculaire, etc. Ces questions ont été rédigées par 61 experts titulaires d'un doctorat ou en cours de doctorat, et ont fait l'objet d'un processus de validation rigoureux.
Suivez ces 3 étapes pour réaliser une intégration rapide de l'API de génération de texte :
- Créer une API Key sur la plateforme DeepSeek
- Trouver un exemple de génération de texte dans la documentation DeepSeek (il y a généralement du code prêt à copier)
- Ouvrir l'AI IDE, coller l'API Key + l'exemple officiel, et dire à l'IA ce que vous voulez accomplir :
Aide-moi à intégrer l'API de ce grand modèle de langage pour prendre en charge la fonction de génération de textes publicitaires de cette application
Ensuite, nous allons faire une démonstration que vous pouvez suivre. Tout d'abord, inscrivez-vous sur DeepSeek et créez une API Key, puis rechargez un petit montant pour vérifier.
Cliquez sur « API KEYS » et trouvez « create new API key » en bas de l'écran. Vous obtiendrez finalement une clé API comme sk-8573341c39fc44315aadc071c53rh7d2.
Une fois que vous avez la clé, vous avez l'autorisation d'appeler le modèle.
À ce stade, vous pouvez directement lire la documentation API, qui fournit généralement des exemples d'appel en curl ou Python.
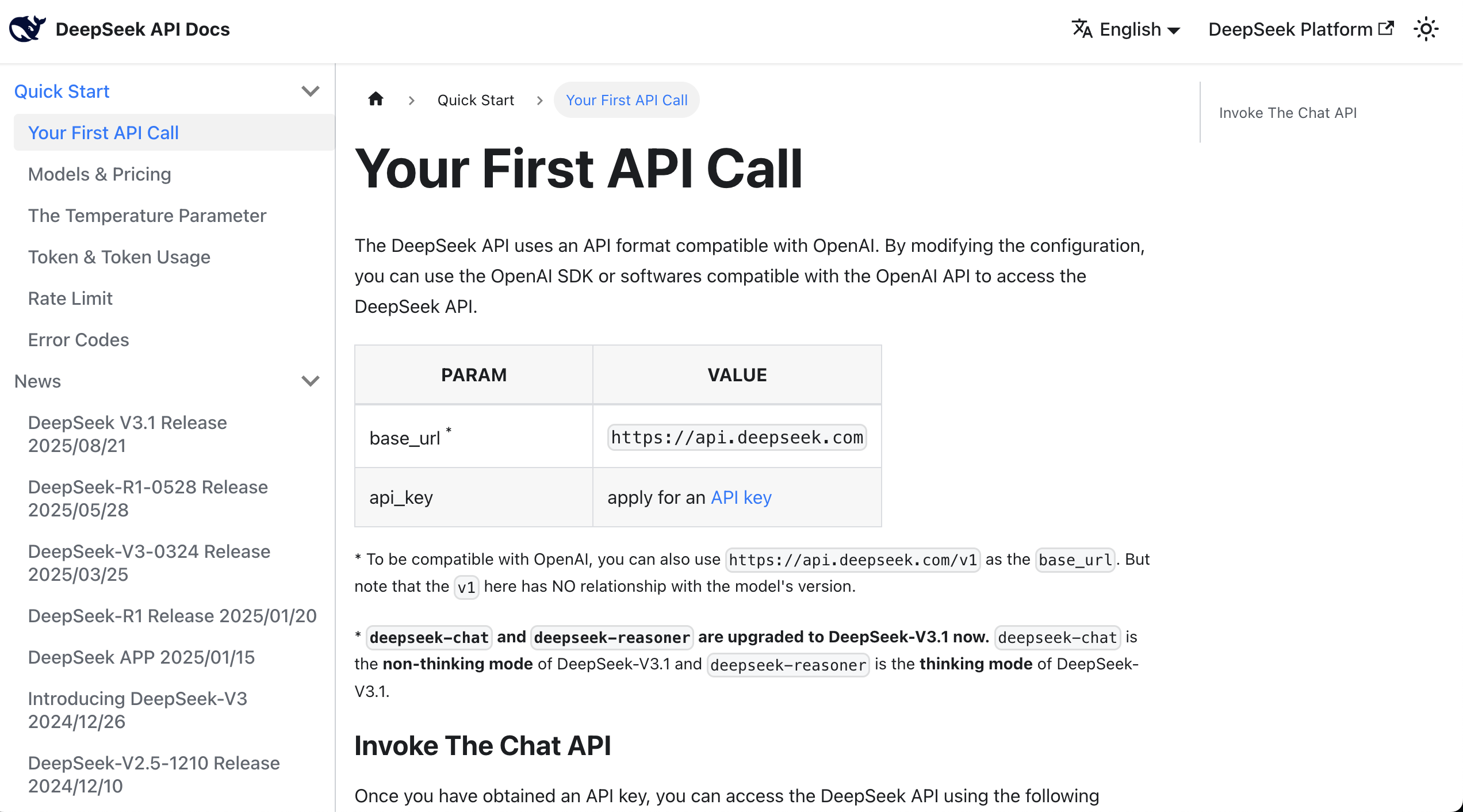
Après avoir trouvé l'exemple, vous pouvez copier tout le contenu de la documentation et votre clé dans la boîte de dialogue de l'AI IDE, et lui demander de vous aider à intégrer le grand modèle de langage dans le prototype déjà développé.
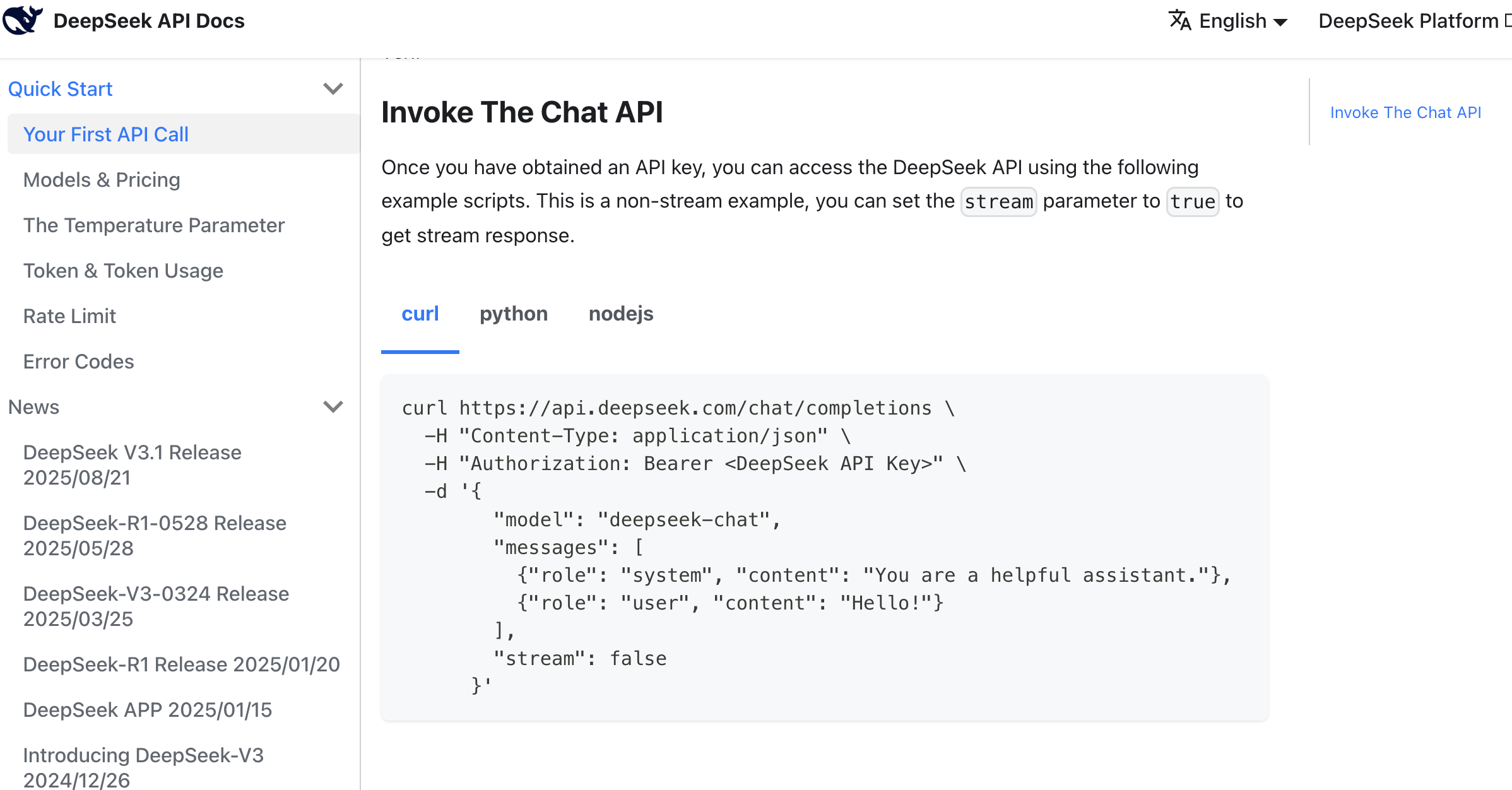
Référence de prompt à utiliser :
En te référant à cette méthode d'appel, aide-moi à prendre en charge la fonction de génération de textes publicitaires, qui peut générer des textes publicitaires pour le commerce électronique de Douyin en plusieurs styles sur la base des informations produit.
Matériel de référence :
clé API : sk-8573341c39aefa1efe
Référence de requête API :
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'Après un certain temps de génération de code par l'IA, nous pouvons facilement obtenir le bouton de génération de texte publicitaire correspondant pour le tester. Si vous ne trouvez pas l'entrée, vous pouvez demander à l'AI IDE de vous indiquer depuis quelle page vous pouvez accéder à cette page. Si vous ne trouvez vraiment pas, vous pouvez demander à l'AI IDE de reconstruire et d'améliorer directement votre idée.
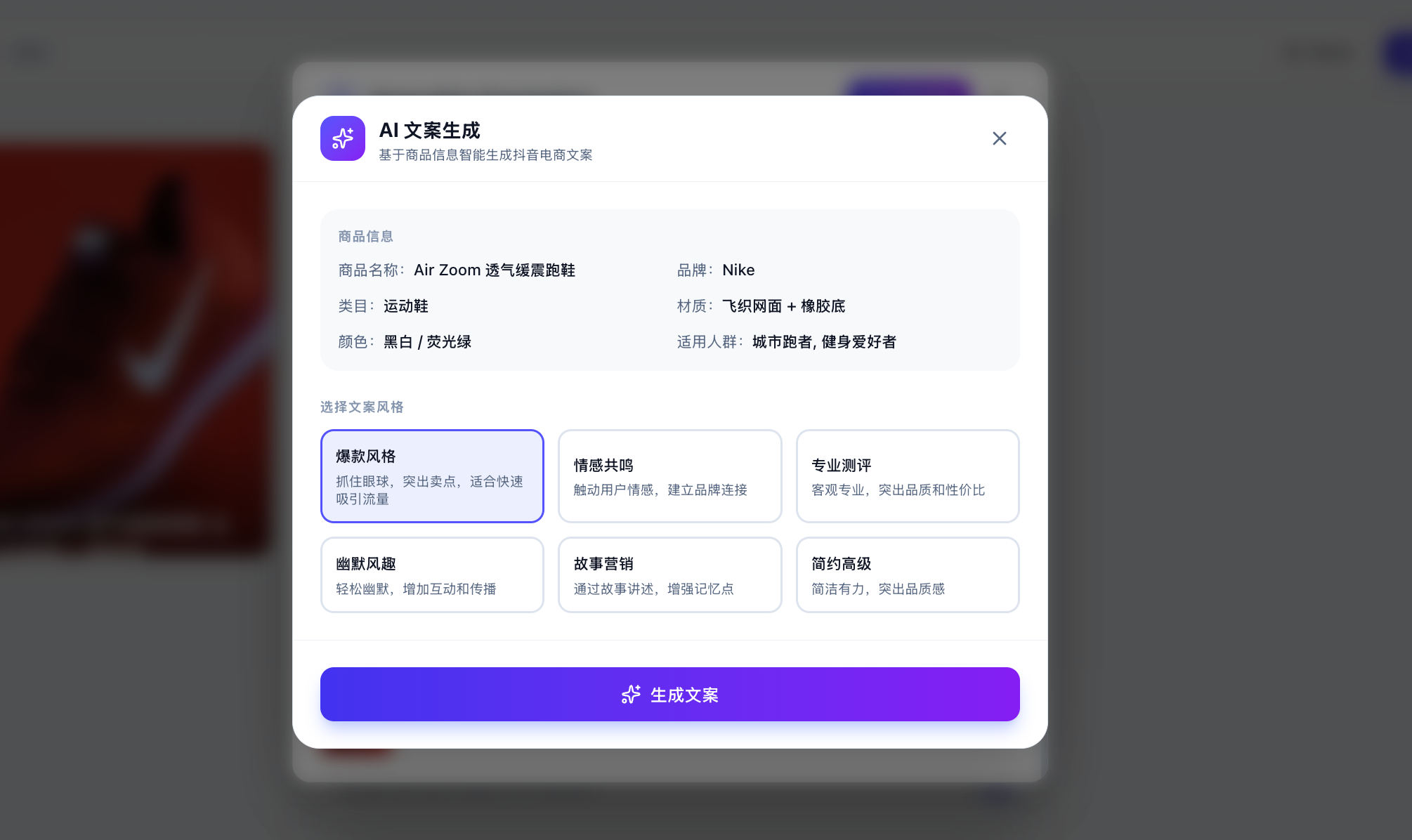
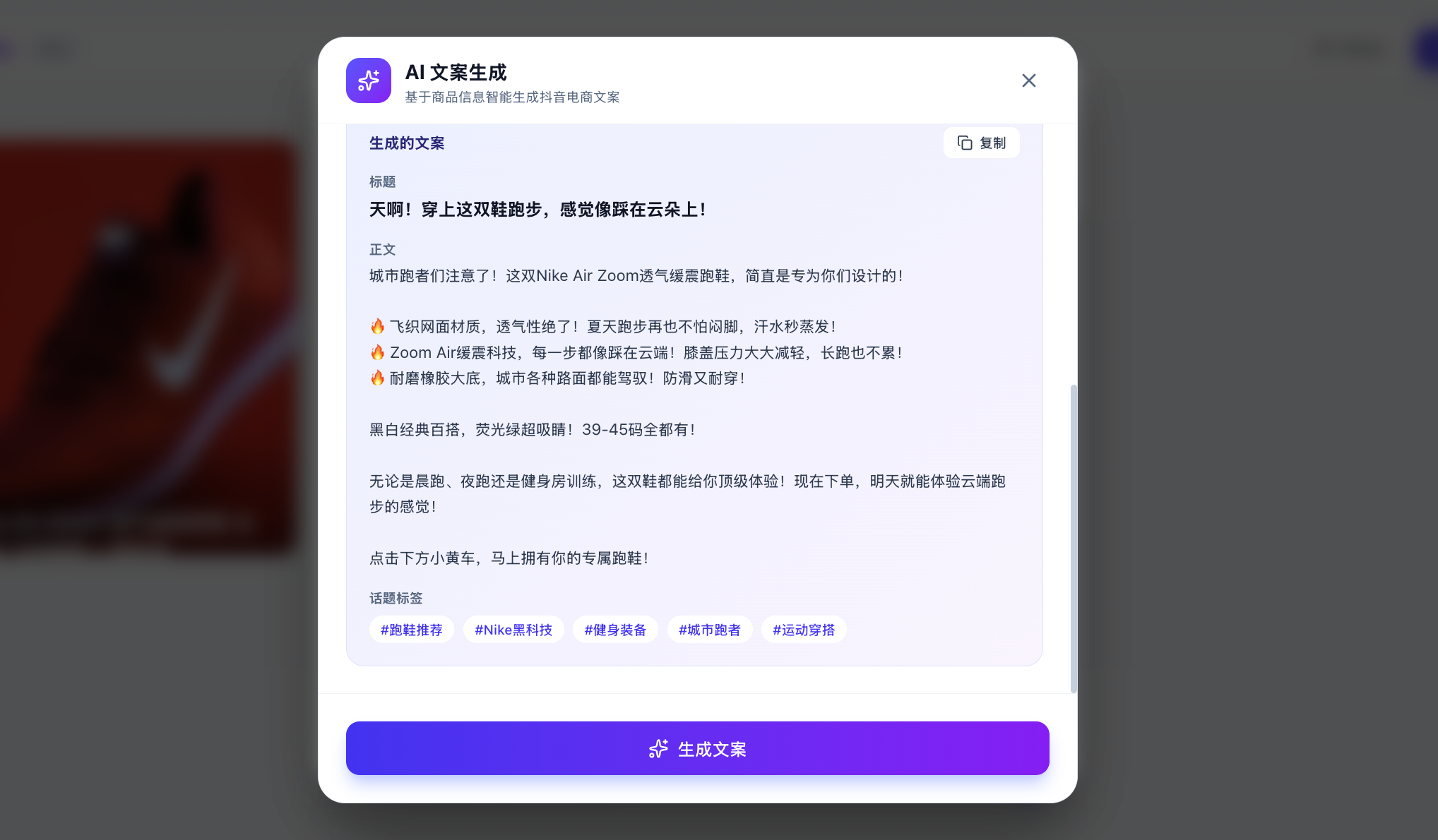
Bien sûr, vous pourriez vous demander : comment savoir si le grand modèle a vraiment été appelé et qu'il ne s'agit pas simplement d'une réponse figée intégrée ? Vous pouvez saisir du texte personnalisé et demander au modèle de générer le texte publicitaire correspondant en fonction de votre demande personnalisée.
Si vous constatez que les résultats sont différents à chaque fois et logiques, vous pouvez être sûr que l'API est appelée normalement. Vous pouvez aussi vérifier sur la plateforme de gestion d'utilisation de l'API si l'appel a réussi (bien qu'il puisse falloir attendre quelques minutes pour voir les résultats).
Autres modèles de génération de texte
En plus de DeepSeek, vous pouvez aussi essayer d'autres grands modèles de langage. Comme la plupart des modèles fournissent une interface compatible OpenAI, le changement est très simple -- il suffit de modifier l'API Key, l'URL de base et le nom du modèle.
Intégration MiniMax
Pour en savoir plus : Qu'est-ce que MiniMax ?
MiniMax est une entreprise chinoise d'intelligence artificielle dédiée à la recherche et au développement de technologies d'intelligence artificielle générale. MiniMax a lancé sa série de modèles de langage MiniMax-M2.7, qui affiche d'excellentes performances dans de nombreux benchmarks, avec un rapport qualité-prix exceptionnel.
Principales caractéristiques de la série MiniMax-M2.7 :
- Contexte ultra-long : prend en charge une fenêtre de contexte de 204 800 tokens, adaptée au traitement de documents longs et de dialogues multi-tours
- Rapport qualité-prix élevé : prix très compétitif
- Interface compatible OpenAI : peut être appelée directement avec le SDK OpenAI, sans apprentissage supplémentaire
- Deux modèles disponibles :
MiniMax-M2.7: modèle phare, adapté aux tâches complexesMiniMax-M2.7-highspeed: version haute vitesse, mêmes performances mais plus rapide
La méthode d'intégration est identique à DeepSeek, en 3 étapes :
- Allez sur la plateforme ouverte MiniMax et créez un compte et une API Key
- Trouvez un exemple d'appel dans la documentation MiniMax
- Collez l'API Key + l'exemple dans l'AI IDE
Comme MiniMax fournit une interface compatible OpenAI, vous pouvez directement copier l'exemple curl ci-dessous et votre clé API, et les envoyer à l'AI IDE pour l'intégration :
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.7",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'✅ Conseil
Le format d'API de MiniMax est presque identique à celui de DeepSeek (tous deux utilisent le format compatible OpenAI), donc si vous avez déjà réussi à intégrer DeepSeek, passer à MiniMax ne nécessite de modifier que trois choses :
- URL de base : changez en
https://api.minimax.io/v1 - API Key : utilisez l'API Key de MiniMax
- Nom du modèle : changez en
MiniMax-M2.7ouMiniMax-M2.7-highspeed
Pour plus d'informations, consultez la documentation de l'interface compatible OpenAI de MiniMax.
3. Intégrer l'API de conversion image-texte : Qwen3 VL
ℹ️ Pour aller plus loin sur les principes
Si vous voulez en savoir plus sur les principes, consultez l'annexe : Introduction aux modèles de langage visuel (VLM).
Pour en savoir plus : Qu'est-ce que Qwen3 VL ?
Qwen3 VL est la dernière version de la série de modèles de langage visuel multimodal développée par l'équipe Tongyi Qianwen d'Alibaba Cloud. VL signifie « Vision-Language », c'est-à-dire un modèle de langage visuel. Il est capable de comprendre le contenu des images et de générer des descriptions textuelles, de répondre à des questions sur les images et d'extraire des informations des images.


Principales capacités de Qwen3 VL :
- Compréhension d'images : capable d'identifier les objets, scènes, personnages et textes dans les images
- Questions-réponses visuelles : répondre avec précision aux questions sur les images
- Description d'images : générer des descriptions textuelles détaillées ou concises
- Compréhension multi-images : prendre en charge le traitement simultané de plusieurs images pour une analyse comparative
- Extraction de texte : extraire du contenu textuel des images (capacité OCR)
Pourquoi choisir Qwen3 VL ?
Par rapport au modèle de génération précédent, Qwen3 VL a significativement amélioré la précision de la compréhension d'images, prenant en charge des tâches d'analyse d'images plus longues et plus complexes. Il excelle dans la compréhension du chinois, avec un coût d'appel API relativement faible et un excellent rapport qualité-prix. De plus, sa fenêtre de contexte est plus grande, ce qui lui permet de gérer des tâches de raisonnement visuel plus complexes.
Scénarios d'application typiques :
- Commerce électronique : génération automatique de titres, descriptions et points forts à partir de photos de produits
- Création de contenu : génération automatique de textes publicitaires ou de suggestions d'images à partir de visuels
- Bureau : extraction du contenu d'images, reconnaissance automatique de rapports
- Éducation : analyse automatique de questions illustrées, extraction de points de connaissance
Dans la partie précédente, nous avons expliqué comment intégrer l'API de génération de texte. Mais pour le scénario de notre application, nous constatons un problème : nous téléchargeons une image, et si nous n'utilisons qu'un modèle de langage, il ne peut pas bien comprendre le contenu de l'image, ce qui peut entraîner des résultats imprécis.
Nous voulons un modèle capable de transformer une image en description textuelle, ce qui nécessite un modèle de langage visuel (VLM). Dans notre cas, nous utiliserons un modèle VLM pour générer des descriptions de points de vente de produits afin d'améliorer l'expérience utilisateur.
Pour plus de simplicité, nous utiliserons l'API fournie par la plateforme cloud SiliconFlow pour l'intégration de l'API de conversion image-texte.
Pour en savoir plus : Qu'est-ce que SiliconFlow ?
SiliconFlow est une plateforme chinoise bien connue d'agrégation de modèles IA, offrant des services d'API pour de nombreux modèles de langage et de vision grand public et open source.
Caractéristiques de la plateforme :
- Support multi-modèles : intègre de nombreux modèles IA populaires, notamment DeepSeek, Qwen, Llama et d'autres modèles open source
- Optimisation technique : optimisation d'inférence pour les modèles open source, offrant des services API à faible latence et haute concurrence
- Compatibilité d'interface : fournit des API compatibles avec le format OpenAI pour une intégration facile
- Paiement à l'usage : facturation à l'utilisation
SiliconFlow est relativement mature dans les services d'inférence de modèles open source et constitue un choix courant pour l'utilisation de modèles IA open source chinois.
Sur la page d'accueil de SiliconFlow, vous pouvez voir qu'il y a beaucoup de modèles disponibles. Trouvez le filtre dans le coin supérieur gauche, cliquez pour l'ouvrir, sélectionnez le tag « vision », et vous verrez plusieurs modèles de conversion image-texte, comme GLM-4.6V de Zhipu ou Qwen3-VL.
Vous pouvez choisir n'importe lequel pour tester, ici nous prenons Qwen/Qwen3-VL-8B-Instruct comme exemple.
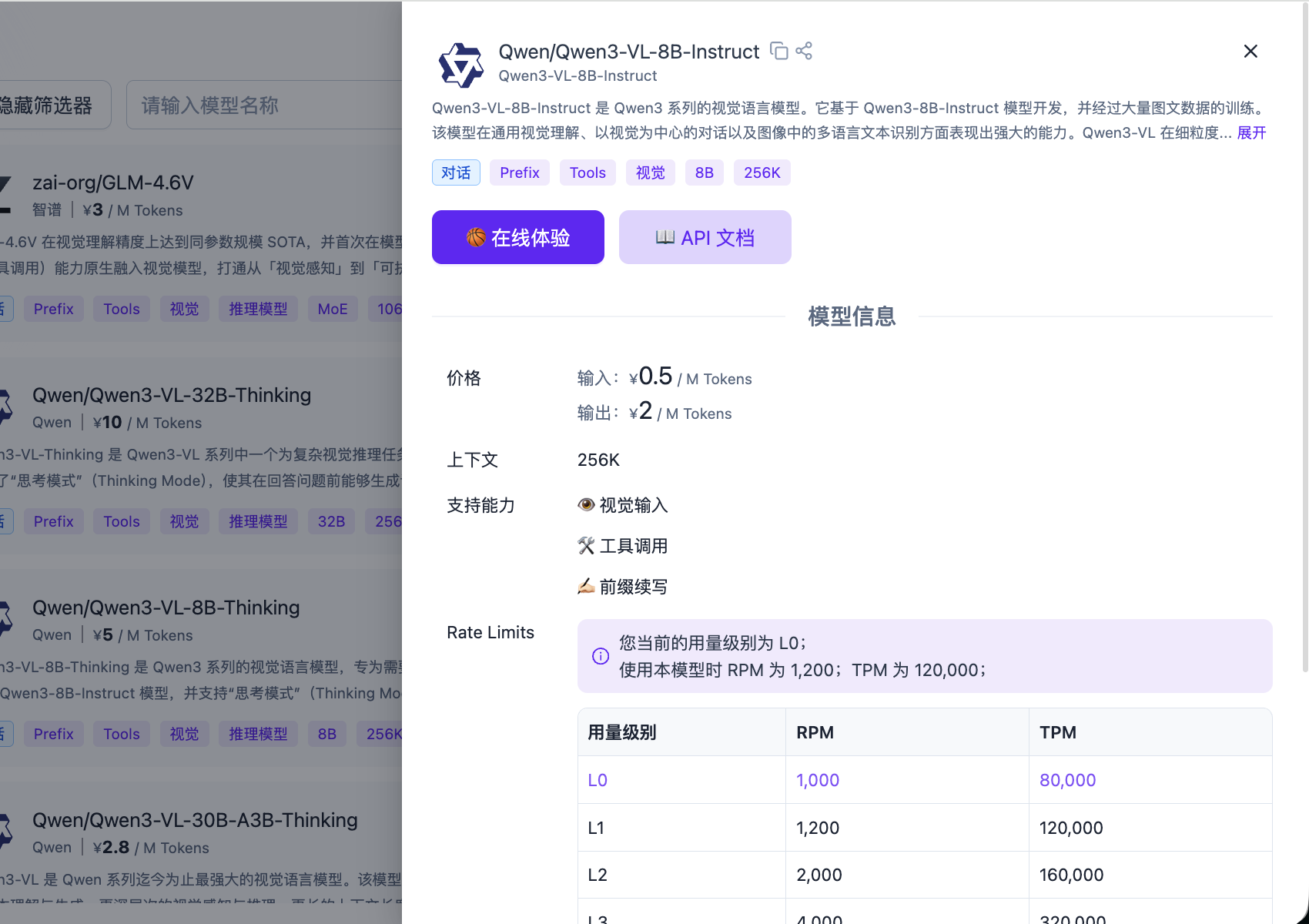
Accédez à la plateforme SiliconFlow, cliquez sur « Nouvelle clé API » dans la section des clés API, et créez une nouvelle clé API.
Vous pouvez utiliser directement le code ci-dessous comme référence et l'envoyer à l'AI IDE avec votre clé API générée pour l'intégration fonctionnelle.
Code de référence pour la conversion image-texte
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
caption = caption_image(image_path)Dans ce scénario, nous allons directement demander à l'AI IDE de nous aider à implémenter la fonction de génération automatique de texte de points de vente et de mots-clés à partir des images téléchargées, comme suit :
Sur la base de l'API de conversion image-texte ci-dessous, aide-moi à implémenter la fonction de génération automatique de texte de points de vente et de mots-clés à partir des images téléchargées.
<Collez ici le code de référence et la clé>Résultat final : 
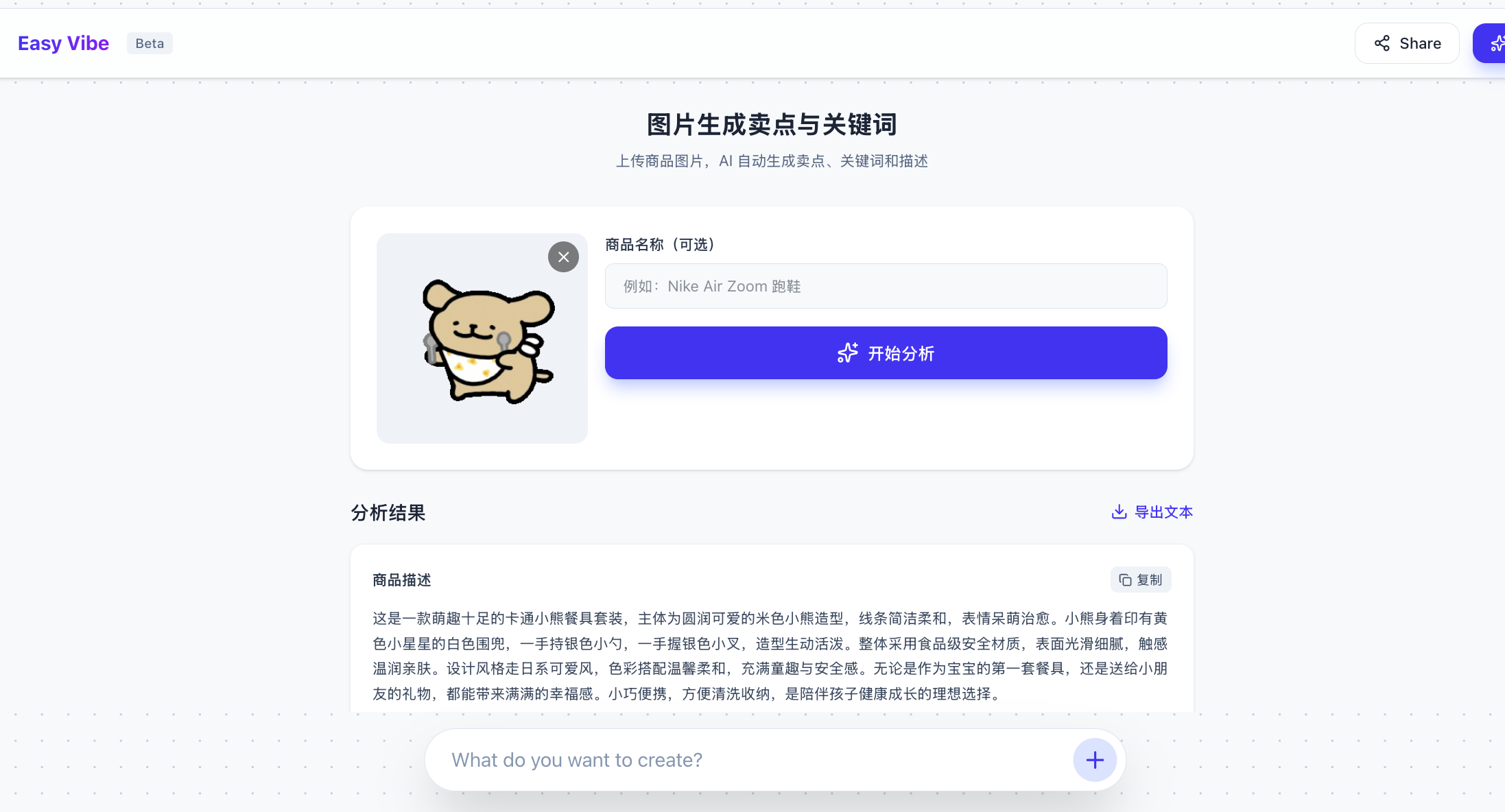
4. Intégrer l'API de génération d'images : Seedream Jimeng
Dans les parties précédentes, nous avons principalement traité des tâches liées au texte. Nous allons maintenant essayer d'intégrer la génération d'images, en prenant en charge la génération d'images à partir de descriptions textuelles ou la modification d'images.
ℹ️ Pour aller plus loin sur les principes
Si vous voulez en savoir plus sur les principes, consultez l'annexe : Introduction à la génération d'images.
Pour en savoir plus : Qu'est-ce que Seedream Jimeng ?

Vous connaissez peut-être déjà Nano Banana (développé par Google), mais vous ne devriez pas manquer Seedream. Seedream 4.5 est le nouveau modèle de création d'images de ByteDance. Il intègre la génération et l'édition d'images dans une architecture unifiée, ce qui lui permet de gérer de manière flexible des tâches multimodales complexes comme la génération basée sur la connaissance, le raisonnement complexe et la cohérence de référence. De plus, sa vitesse d'inférence est bien supérieure à celle de la génération précédente, et il peut générer des images haute définition jusqu'à 4K.


Principales capacités :
- Texte vers image : générer des images à partir de descriptions textuelles, prenant en charge plusieurs styles (réaliste, cartoon, encre, cyberpunk, etc.)
- Transfert de style : convertir une image dans un style artistique spécifié
- Variantes d'images : générer de nouvelles images de style similaire à partir d'une image de référence
- Amélioration de la résolution : augmenter la clarté et les détails des images
- Édition d'images : modifier et retoucher des images existantes via des instructions en langage naturel
Pourquoi choisir Seedream ?
- Accès stable depuis la Chine : vitesse d'accès rapide et latence faible
- Excellents résultats : performances stables et fiables dans les scénarios de commerce électronique et de création de visuels
- Optimisé pour le chinois : meilleure compréhension des prompts en chinois, adapté aux utilisateurs chinois
- Rapidité : efficacité de génération élevée, temps de réponse court
- Qualité stable : génération d'images haute définition jusqu'à 4K
Scénarios d'application typiques :
- Commerce électronique : génération d'images principales, de visuels pour les pages de détails, de posters promotionnels
- Réseaux sociaux : génération d'avatars, de stickers, d'images d'accompagnement
- Design : création rapide de concepts, de visuels, d'images d'arrière-plan
- Marketing : création de publicités, de bannières d'événements, de posters de fêtes
Complémentarité avec Qwen3 VL :
Ces deux API peuvent être utilisées en chaîne : d'abord utilisez Qwen3 VL pour analyser l'image de référence et comprendre le contenu visuel, puis utilisez Seedream pour générer une nouvelle image basée sur le prompt dérivé de l'analyse de l'image de référence.
Beaucoup de « posters IA / images principales IA / images de personnages IA » que vous voyez sur Douyin, Bilibili ou YouTube utilisent essentiellement la technologie présentée ici. Ce que vous devez faire est simple : organiser l'entrée de l'utilisateur en une phrase, envoyer une requête à l'API d'image, puis afficher l'image renvoyée. Le modèle utilisé ici s'appelle un modèle de génération d'images / d'édition d'images.
Nous allons démontrer progressivement comment intégrer l'API Seedream dans votre projet (avec l'aide de l'AI IDE).
Accédez à la page d'accueil puis cliquez sur connexion.
Après connexion, trouvez l'option de recharge dans le coin supérieur droit.
La recharge nécessite une vérification d'identité.
Une fois la vérification réussie, vous pouvez recharger 1 yuan pour tester.
Retournez à la page initiale et cliquez sur Accès API.
Créez d'abord une clé API, puis cliquez sur les options de sélection.
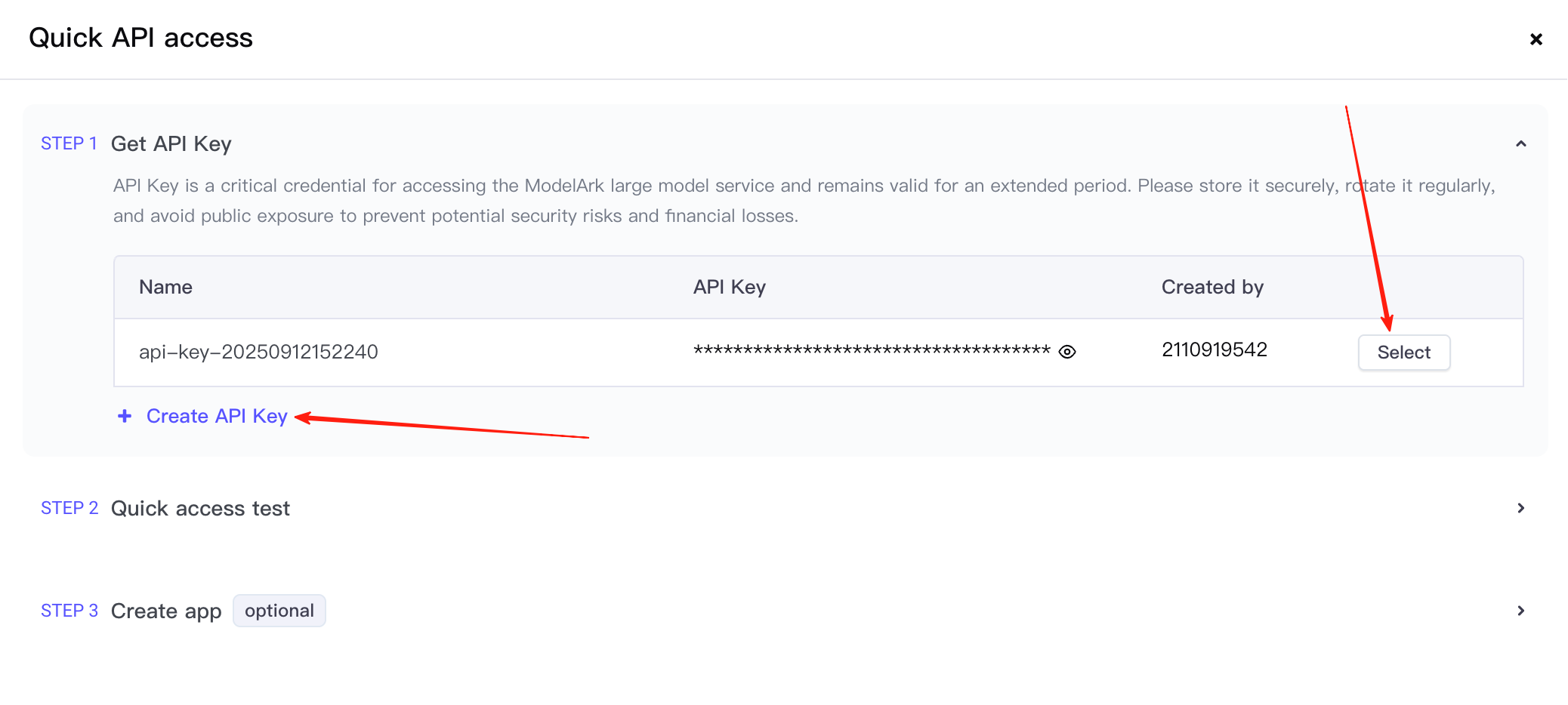
Cela vous amènera à l'étape 2. Ici, vous devez confirmer que le service appelé est Seedream 4.5 et copier l'exemple d'appel fourni. (Les captures d'écran ici datent d'une période antérieure, la version du modèle affichée est donc encore la 4.0)
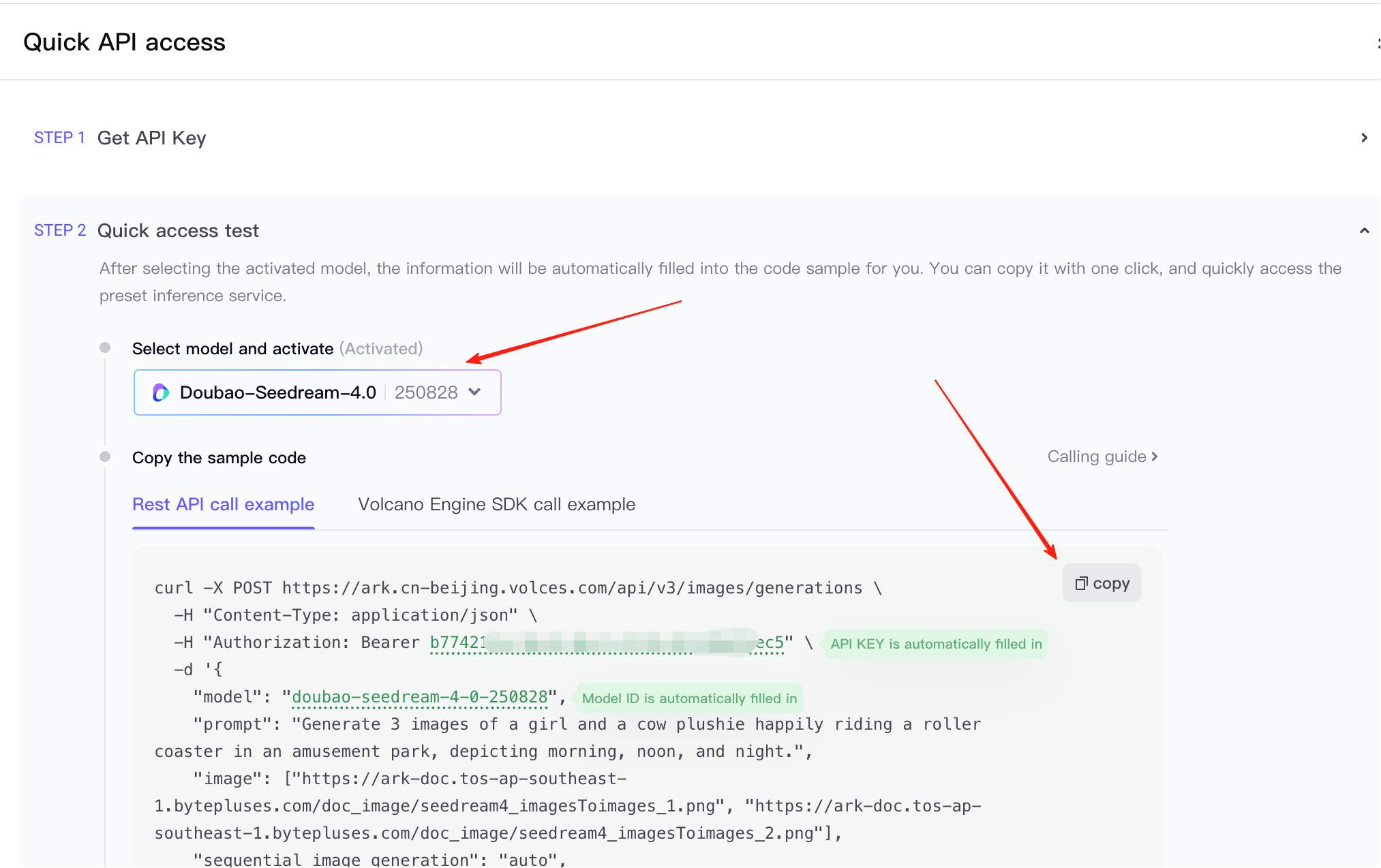
Une fois que vous avez la clé API et l'exemple d'appel, vous pouvez les coller directement dans l'AI IDE pour qu'il génère la démo frontend ou intègre la capacité dans votre prototype existant. Notez que dans l'image, vous pouvez choisir entre le mode texte-vers-image ou la génération d'une image à partir de plusieurs images. Vous devez sélectionner le code de référence en fonction de vos besoins actuels.
⚠️ Remarque importante
L'exemple par défaut est relativement complexe. N'oubliez pas de désactiver « Ajouter un filigrane » et « Réponse en flux continu » pour éviter de générer un filigrane et de provoquer des échecs de requête.
Comme nous utilisons ensuite le mode de génération à partir d'images de référence, nous allons d'abord vers la fonctionnalité de génération d'une image à partir de plusieurs images. Le code de référence est le suivant :
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "Remplacer la tenue de l'image 1 par celle de l'image 2",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'Avec le code de référence d'image, nous demandons à l'AI IDE de prendre en charge les tâches d'image courantes dans le commerce électronique :
Sur la base de l'API ci-dessous, aide-moi à implémenter les fonctionnalités courantes du commerce électronique dans ce projet (par exemple, la génération de posters, la génération d'images principales pour Douyin, etc.)
<Collez ici la clé API et le code d'édition d'image>Résultat de l'implémentation :
Il est à noter que la génération d'images peut rencontrer des problèmes inhabituels. Il est recommandé de demander à l'AI IDE d'afficher les messages d'erreur complets pour faciliter le copier-coller et la modification (sinon, vous risquez de voir s'afficher « échec de la génération » à répétition sans savoir pourquoi). Par exemple, vous pouvez dire :
N'affiche pas seulement « échec de la génération d'image », affiche systématiquement la raison complète de l'échec, comme une incompatibilité d'image, une erreur de requête, un délai d'attente, etc. !Parfois, après une modification, la mise à jour n'est pas appliquée à la page web. Si vous constatez que la page continue de générer des erreurs après plusieurs modifications, vous pouvez aussi essayer de dire directement à l'AI IDE : redémarre ce projet.
Dans le contexte du commerce électronique, nous pourrions vouloir que les vêtements téléchargés par l'utilisateur s'habillent automatiquement sur un personnage, ou que des images de vente attrayantes et des posters soient générés automatiquement pour les produits. Ici, le prompt que nous avons essayé consistait à lui faire générer un poster pour le commerce électronique :
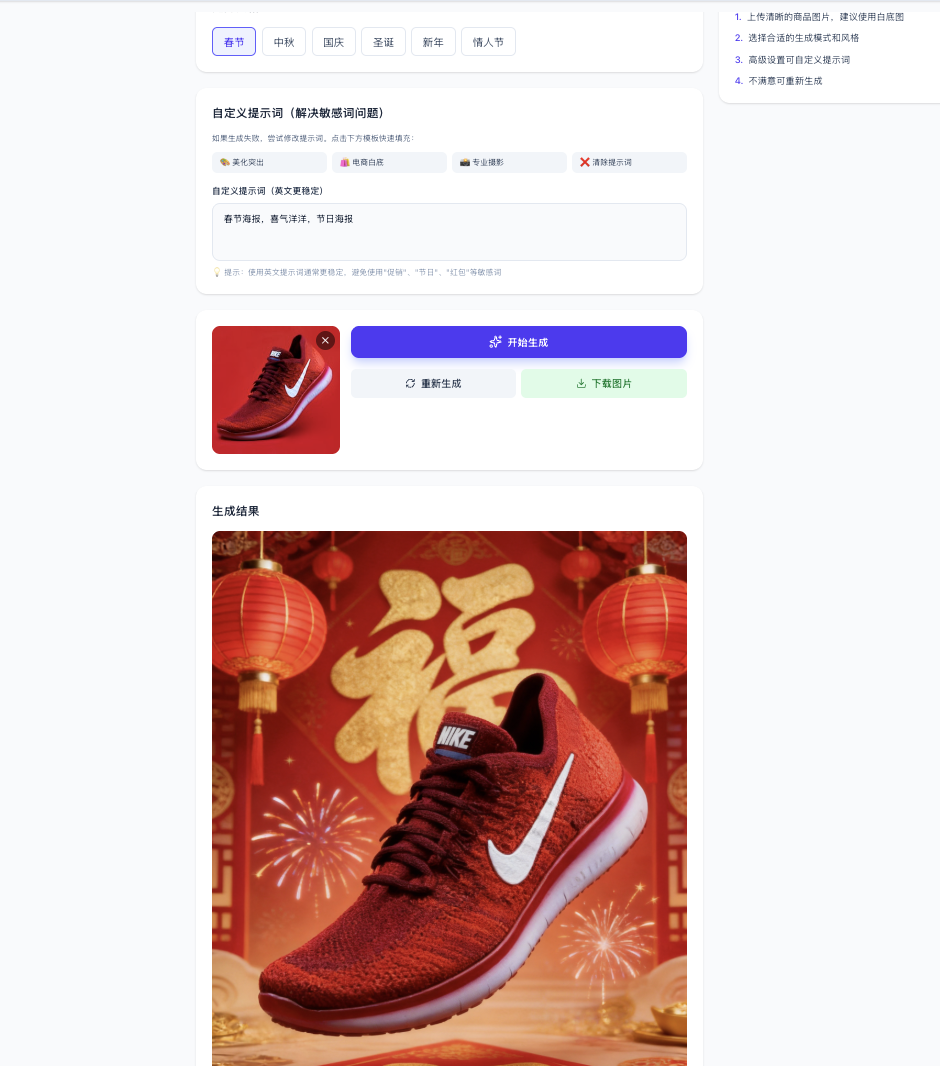
Vous pouvez utiliser l'API texte-vers-image ou image-vers-image pour implémenter différentes fonctionnalités en fonction de vos scénarios métier imaginés.
Autres services de génération d'images
Voici d'autres options. Il est recommandé de d'abord réussir l'intégration avec Qwen, puis de remplacer par les services suivants en fonction des résultats et des coûts (choisissez en fonction de votre expérience réelle).
Intégration Recraft
Si votre prototype est plus orienté vers la « production de design » (par exemple, la génération d'illustrations de style de marque, de posters marketing, de ressources vectorielles), Recraft peut être plus adapté. La méthode d'intégration est identique à la section précédente : obtenir la clé + trouver l'exemple officiel + demander à l'AI IDE d'intégrer l'exemple dans votre bouton/page.
Pour en savoir plus : Qu'est-ce que Recraft ?
Recraft est un outil IA pour les designers, illustrateurs et professionnels du marketing -- fondé en 2022 aux États-Unis, basé à Londres. Il aide à générer/itérer des visuels (images, art vectoriel, graphiques 3D), avec des avantages comme une sortie de haute qualité (pour toute taille/longueur de texte), un positionnement précis des éléments et un design cohérent de marque. Approuvé par plus de 3 millions d'utilisateurs dans 200 pays (dont Ogilvy et Netflix), avec plus de 350 millions d'images créées, son équipe vise à en faire un outil indispensable pour les designers, en s'assurant que les créateurs gardent le contrôle de leur flux de travail assisté par IA.


Il faut d'abord trouver l'entrée API pour obtenir une clé API.
Comme il n'y a pas de crédit gratuit ici, nous devons recharger 1 000 crédits nous-mêmes. Ce site accepte Alipay et WeChat Pay, il est donc facile d'obtenir 1 000 crédits (attention : ne rechargez pas plus que nécessaire).

Ensuite, nous suivons toujours la même méthode : aller dans la documentation officielle pour trouver l'exemple de requête correspondant :
Intégration Qwen Image / Qwen Image Edit
Si vous souhaitez utiliser une approche plus simple pour intégrer un service de génération d'images, vous pouvez envisager Qwen Image (Tongyi Wanxiang). L'approche reste la même : considérez-le comme une « API de génération d'images » et connectez-la à votre bouton de prototype.
Pour en savoir plus : Qwen Image / Qwen Image Edit ?
Qwen Image (aussi appelé Tongyi Wanxiang) est la série de modèles de génération d'images de l'équipe Tongyi d'Alibaba Cloud, comprenant deux modèles principaux :
1. Qwen Image -- modèle texte-vers-image (Text-to-Image)
Génère de nouvelles images à partir de descriptions textuelles. Vous entrez un prompt, le modèle comprend votre intention et génère une image correspondante.

Principales capacités :
- Texte vers image : générer des images à partir de descriptions textuelles, prenant en charge plusieurs styles (réaliste, cartoon, encre, cyberpunk, etc.)
- Transfert de style : convertir une image dans un style artistique spécifié
- Variantes d'images : générer de nouvelles images de style similaire à partir d'une image de référence
- Amélioration de la résolution : augmenter la clarté et les détails des images
2. Qwen Image Edit -- modèle image-vers-image (Image-to-Image)
Modifie et retouche des images existantes via des instructions en langage naturel. Le modèle comprend votre intention de modification et génère le résultat.
Principales capacités :
- Remplacement partiel : remplacer un objet ou un personnage dans une image (par exemple « changer le fond pour la mer »)
- Suppression d'éléments : retirer les éléments indésirables d'une image
- Conversion de style : ajouter des filtres ou des effets artistiques à une image
- Extension d'image : étendre les bords d'une image et générer du nouveau contenu
- Retouche intelligente : embellissement automatique, ajustement de la lumière et des ombres, correction de défauts



Pourquoi choisir la série Qwen Image ?
- Optimisé pour le chinois : meilleure compréhension des prompts en chinois, adapté aux utilisateurs chinois
- Coût réduit : prix plus abordable par rapport aux concurrents internationaux
- Rapidité : efficacité de génération élevée, temps de réponse court
- Qualité stable : performances stables et fiables dans les scénarios de commerce électronique et de création de visuels
- Styles variés : prise en charge de nombreux styles artistiques et effets créatifs
Scénarios d'application typiques :
- Commerce électronique : génération d'images principales, de visuels pour les pages de détails, de posters promotionnels
- Réseaux sociaux : génération d'avatars, de stickers, d'images d'accompagnement
- Design : création rapide de concepts, de visuels, d'images d'arrière-plan
- Marketing : création de publicités, de bannières d'événements, de posters de fêtes
Consultez le site SiliconFlow. Sur le côté gauche, il y a une section « Playground » où vous pouvez tester différents modèles sans appel API. En haut de la page, il y a un bouton « Filters » ; cliquez pour filtrer la liste de modèles.
Si vous sélectionnez « Image », vous ne verrez que les modèles de génération d'images actuellement supportés. Dans ce cas, nous utiliserons Qwen/Qwen-Image.
Une fois tout configuré, vous devez vous référer à la documentation correspondante de l'API de génération d'images. Vous pouvez trouver la section « API Reference » sur la page de documentation officielle. Cliquez dessus, puis naviguez vers la section API de génération d'images et trouvez l'exemple de requête correspondant.
Vous pouvez envoyer l'exemple de requête suivant et votre clé API à l'AI IDE pour intégrer la fonctionnalité de génération d'images.
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'Ici, le modèle peut être Qwen/Qwen-Image ou Qwen/Qwen-Image-Edit-2509.
Code de référence pour l'édition d'images
Copiez le code ci-dessous et la clé, puis envoyez-les ensemble à l'AI IDE :
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "Transformer le ciel en soirée, avec la lune et les étoiles, dans un style onirique"
negative_prompt: str = "flou, basse qualité, déformé"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")Annexe : Comment trouver « le modèle le plus puissant actuellement »
Le développement des modèles de texte (souvent appelés « grands modèles de langage ») est très rapide, et nous devons toujours nous assurer que nous utilisons l'un des modèles les plus performants. Grâce aux deux sites suivants, vous pouvez facilement voir « quels modèles sont les plus utilisés et les mieux notés actuellement ».
En général, ces sites peuvent être compris comme des « arènes de modèles » : ils mettent côte à côte les résultats de deux modèles, et vous votez pour celui que vous préférez. Plus un modèle reçoit de votes, plus il est probablement considéré comme « meilleur ».
De plus, vous pouvez occasionnellement voir des modèles anonymes mystérieux (« Unknown Model ») dans ces arènes. Cela signifie généralement que quelqu'un a discrètement introduit un « modèle de test interne » pour un test en aveugle, et vous pourriez avoir l'opportunité d'expérimenter des capacités plus avancées avant les autres.
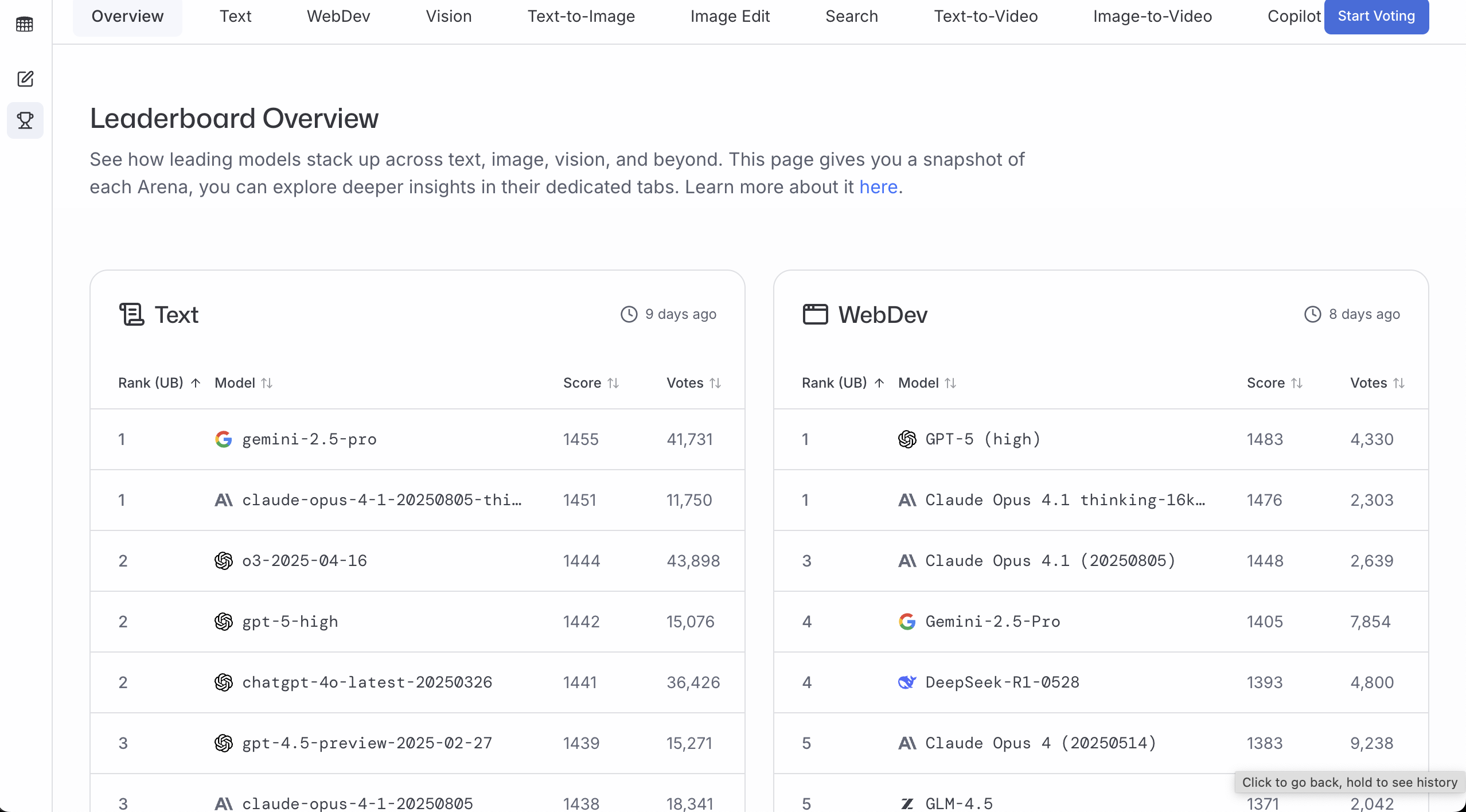
LMArena
Site : https://lmarena.ai/
LMArena est plus adapté pour déterminer « quel modèle est préféré par la majorité ». Plus il y a de votes et plus le score est élevé, plus le modèle est probablement fiable dans les scénarios d'utilisation réels.
Une utilisation simple est de :
- Consulter directement le classement (Leaderboard)
- Choisir d'abord une direction (par exemple, conversation générale / programmation / vision)
- Choisir parmi les 3 premiers celui que vous pouvez utiliser (accès disponible, prix acceptable, latence acceptable)
Artificial Analysis
Site : https://artificialanalysis.ai/
Artificial Analysis est plus adapté pour comparer « qualité / prix / vitesse » dans un même tableau. Vous pouvez l'utiliser comme tableau de référence pour la sélection de modèles.
L'utilisation courante est de :
- Trouver la catégorie de modèles qui vous intéresse (texte / génération d'images, etc.)
- Consulter les indicateurs de qualité (Quality) + prix (Price) + latence/débit (Latency/Throughput)
- Choisir celui qui offre le meilleur rapport qualité-prix pour votre produit
✅ Conseil
Ne vous disputez pas au feeling sur « lequel est le plus puissant ». Une approche plus fiable est de tester 2 à 3 modèles avec les mêmes entrées, puis de combiner les classements et les prix pour prendre une décision.
Résumé
Lors de l'intégration de divers services IA, il n'est pas nécessaire de considérer les API comme trop complexes. Si vous maîtrisez les concepts clés suivants, vous pourrez gérer la plupart des scénarios :
L'essence de l'API est un pont de communication. Ce qu'elle fait est simple : envoyer votre requête et ramener la réponse du modèle. Vous n'avez pas besoin de savoir ce qui se passe en coulisses, il suffit d'organiser correctement le format de la requête.
Le SDK est une encapsulation de l'API. Si l'API est l'interface brute, le SDK est une boîte à outils prête à l'emploi -- il s'occupe des détails fastidieux comme la signature des requêtes, la gestion des erreurs et la validation des paramètres. Dans le développement quotidien, privilégiez le SDK plutôt que l'appel direct à l'API, cela vous évitera bien des tracas.
Quand vous lisez la documentation, concentrez-vous sur trois choses : l'adresse du service (endpoint), les identifiants (clé API) et comment remplir les paramètres d'appel. Une fois ces trois points clarifiés, la mise en marche n'est qu'une question de temps.
Le reste du travail sera accompli par l'IDE et les outils de développement modernes. Concentrez-vous sur votre logique métier, laissez le travail d'appel de bas niveau aux SDK et aux chaînes d'outils matures.
5. 📚 Devoir : Intégrer votre première capacité IA
En vous référant aux prompts et au contenu de cette leçon, complétez un cycle complet :
- Pratique complète en boucle fermée
- Choisissez et intégrez un service IA (LLM / texte-vers-image / image-vers-image) -> Implémentez l'interaction frontend-backend -> Intégrez dans votre prototype
- Partage des résultats
- Capturez d'écran votre page fonctionnelle et partagez-la avec le groupe
- Question de réflexion
- Réservez de l'espace pour le prochain chapitre « Projet complet », réfléchissez à l'avance : comment combiner ces capacités IA pour créer une fonctionnalité intéressante ?
Prochaine étape
Dans le prochain chapitre, nous allons relier ces capacités IA dispersées et créer un produit complet basé sur un scénario métier réel :
- Connecter les étapes de planification de contenu, de mise en ligne de produits et d'analyse de données en un flux métier complet
- Intégrer les capacités IA apprises dans ce chapitre (génération de textes publicitaires LLM, texte-vers-image, édition d'images) dans les étapes métier réelles
- Réaliser un « espace de travail IA commerce électronique » véritablement utilisable, et non une démo isolée