初級四:プロトタイプに AI 能力を注入する
章節ガイド
1. API の基礎概念
前述の通り、私たちの目標は「AI 能力を組み込む」ことで、プロトタイプを静的なデモではなく、実際の AI サービスを呼び出せるツールにすることです。これを実現する鍵は、API(Application Programming Interface)を理解し、使用することです。
API はコンピュータサイエンスにおける重要な抽象概念で、簡単に理解できます:相手が指定した形式で「質問」を送ると、相手も同じ形式で「結果」を返す。
- あなたが送る内容:通常は「API Key」と「何を生成したいか」
- 相手が返す内容:成功すれば結果を返す。失敗すれば理由を伝える(「Key が間違っている」「残高不足」「パラメータエラー」など)
具体的には、以下の核心的な要素を把握する必要があります:
- API Key:あなたの「通行証」であり「財布の鍵」。他人に渡されると、あなたの代わりに API を呼び出して費用が発生します。
- Endpoint(エンドポイント):API リクエストの具体的なパスで、どの機能にアクセスするかをサーバーに伝えます。完全なリクエスト URL は通常「ベース URL + Endpoint パス」で構成されます。例:
- テキスト生成:ベースURL (
https://api.service.com) + Endpoint (/v1/chat/completions) = 完全URLhttps://api.service.com/v1/chat/completions - 画像生成:ベースURL (
https://api.service.com) + Endpoint (/v1/images/generations) = 完全URLhttps://api.service.com/v1/images/generations
- テキスト生成:ベースURL (
- 呼び出し/リクエスト:AI サービスにタスクを送信し、結果を取得するプロセス
- リクエスト内容:AI に送信する具体的な内容。AI に書かせたい記事のテーマ、生成したい画像の説明など。
- レスポンス結果:AI が処理完了後に返す内容。生成された記事、画像など。
- エラーハンドリング:問題が発生した時(API Key エラー、リクエスト過多など)、どのようにトラブルシューティングするか。
ℹ️ API とは
API についてのより深い解説は、付録の API 入門 をご覧ください。
🔐 API セキュリティに関する注意事項
API Key は AI サービスにリクエストするための「通行証」であり、認証と課金に使用されるパスワード文字列です。
API Key はアカウントと課金に直接関連しているため、以下の点に注意してください:
- 絶対にグループチャット、スクリーンショットのネット投稿、公開フォーラムへの投稿はしない
- コードにハードコードして Git リポジトリにコミットしない(特に公開リポジトリ)
- Key の漏洩が疑われる場合は、直ちに新しい Key に変更する
以下の内容では、API KEY を AI IDE に直接貼り付けて操作します。正式なプロジェクトでは絶対にこの方法を使わないでください!!練習なのでこの方法を使います。(より熟练になったら、AI に設定ファイルを生成させ、API KEY を設定ファイルに配置するだけで済みます)
2. テキスト生成 API の統合:DeepSeek
API にはこれらの技術概念が含まれますが、プロトタイプ開発段階では、実際の操作は非常にシンプルで効率的です。核心的なアプローチは:
公式サンプルを見つけ、API Key を取得し、AI IDE にボタンに統合させる。
これらの概念を習得すると、テキストモデルでも画像モデルでも、本質的なフローは同じことがわかります:ユーザーがボタンをクリックすると、フロントエンドが入力を整理してリクエストを送信し、インターフェースが結果を返したら、ページに結果を表示する。次に、実際の操作でこれを確認します。
1.2 プロトタイプを作る で、あなたはすでにインタラクティブなプロトタイプを作りました。次にやることは、プロトタイプの中の「AI のように見える機能」を本当に使える能力に変えることです:ユーザーがボタンをクリックすると、プロトタイプが外部の AI サービスにリクエストを送信し、返されたテキストを表示する。
ℹ️ 原理の詳細
原理に関する詳細を知りたい場合は、付録の 大規模言語モデル(LLM)入門 をご覧ください。
詳細:DeepSeek とは?
杭州深度求索人工知能基礎技術研究有限公司(Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.)、DeepSeek を商号とする、大規模言語モデル(LLMs)を開発する中国の人工知能(AI)企業です。DeepSeek は本社を浙江省杭州に置き、中国のヘッジファンド幻方量化(High-Flyer)に所有・資金提供されています。DeepSeek は幻方量化の共同創業者である梁文鋒氏によって2023年7月に設立され、彼は両社の CEO も務めています。同社は2025年1月に同名のチャットボットと DeepSeek-R1 モデルをリリースしました。
DeepSeek の GPQA ベンチマークランキングにおける他のトップモデルとのパフォーマンス比較を見てみましょう。注目すべきは、DeepSeek はオープンソース(誰でもインターネットからモデルをダウンロード可能)モデルですが、Grok、Google Gemini、ChatGPT などの一般的なモデルはクローズドソースです。ご覧の通り、DeepSeek はすでに第一陣のモデルに大きく迫っています。
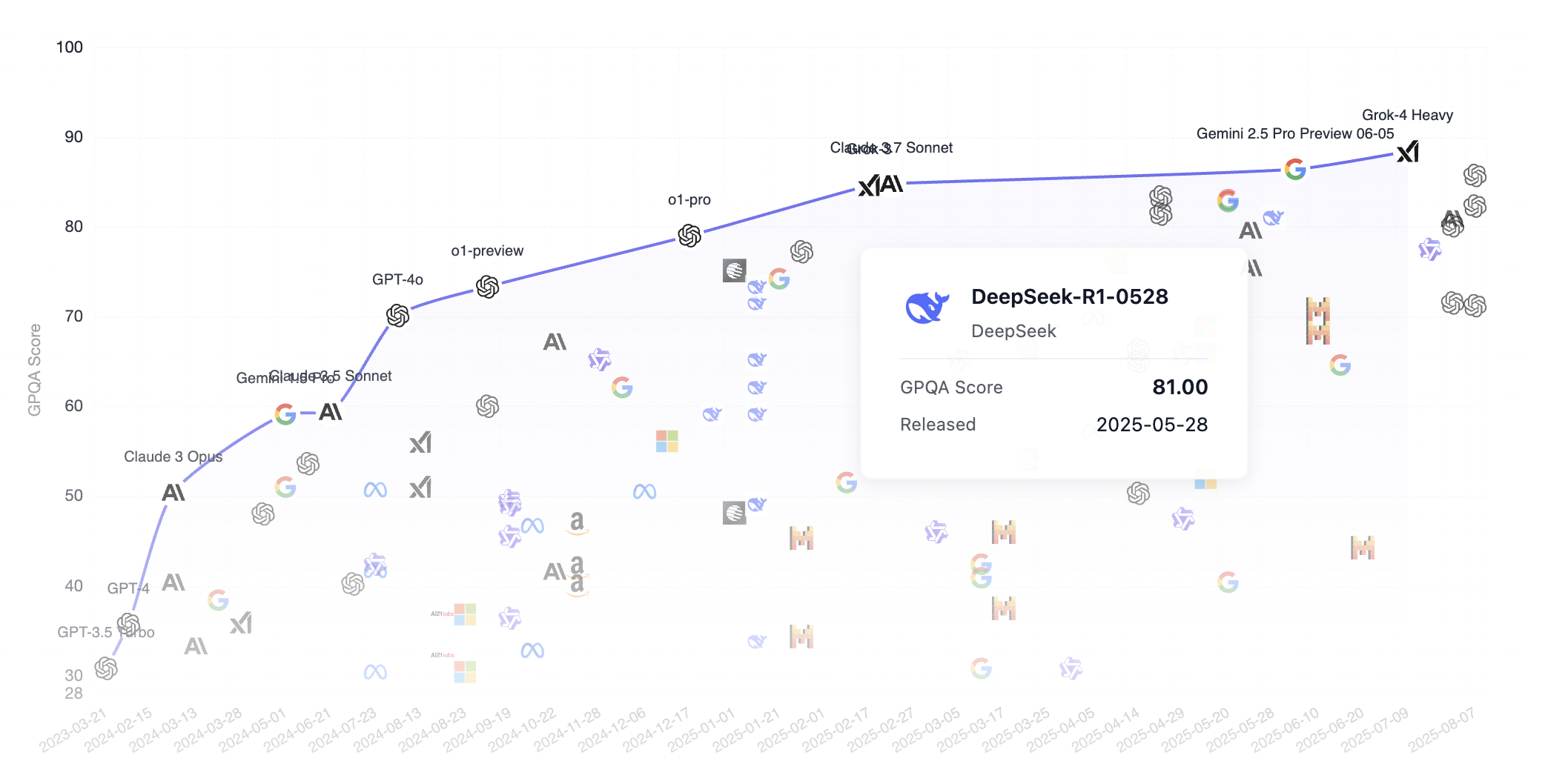
GPQA は「大学院レベル Google-Proof Q&A ベンチマーク」の略で、科学 Q&A タスクのための大学院レベルのベンチマークです。詳細は以下の通りです。
GPQA は448の多肢選択問題を含み、生物学、物理学、化学のサブ分野(量子力学、有機化学、分子生物学など)をカバーしています。これらの問題は61人の博士号取得者または博士課程在籍中の専門家によって作成され、厳格な検証プロセスを経ています。
この3ステップに従えば、大規模モデル生成 API の迅速な統合が可能です:
- DeepSeek プラットフォームで API Key を作成する
- DeepSeek ドキュメントでテキスト生成サンプルを見つける(通常はコピペで使えるサンプルコードがある)
- AI IDE を開き、API Key +公式サンプルを貼り付け、AI に実現したい機能を伝える:
この大規模モデルの API を統合して、このアプリのコピーライティング生成タスクをサポートしてください
次にデモを行います。以下の全フローに沿って操作できます。まず DeepSeek にアカウントを登録し、API Key を作成して、少額をチャージして検証します。
「API KEYS」をクリックし、画面下部の「create new API key」を見つけます。最終的に sk-8573341c39fc44315aadc071c53rh7d2 のような API key が得られます。
Key を取得すると、モデルを呼び出す権限を持てます。
ここで、API ドキュメントを直接読むことができます。通常、curl または Python の呼び出しサンプルが提供されています。
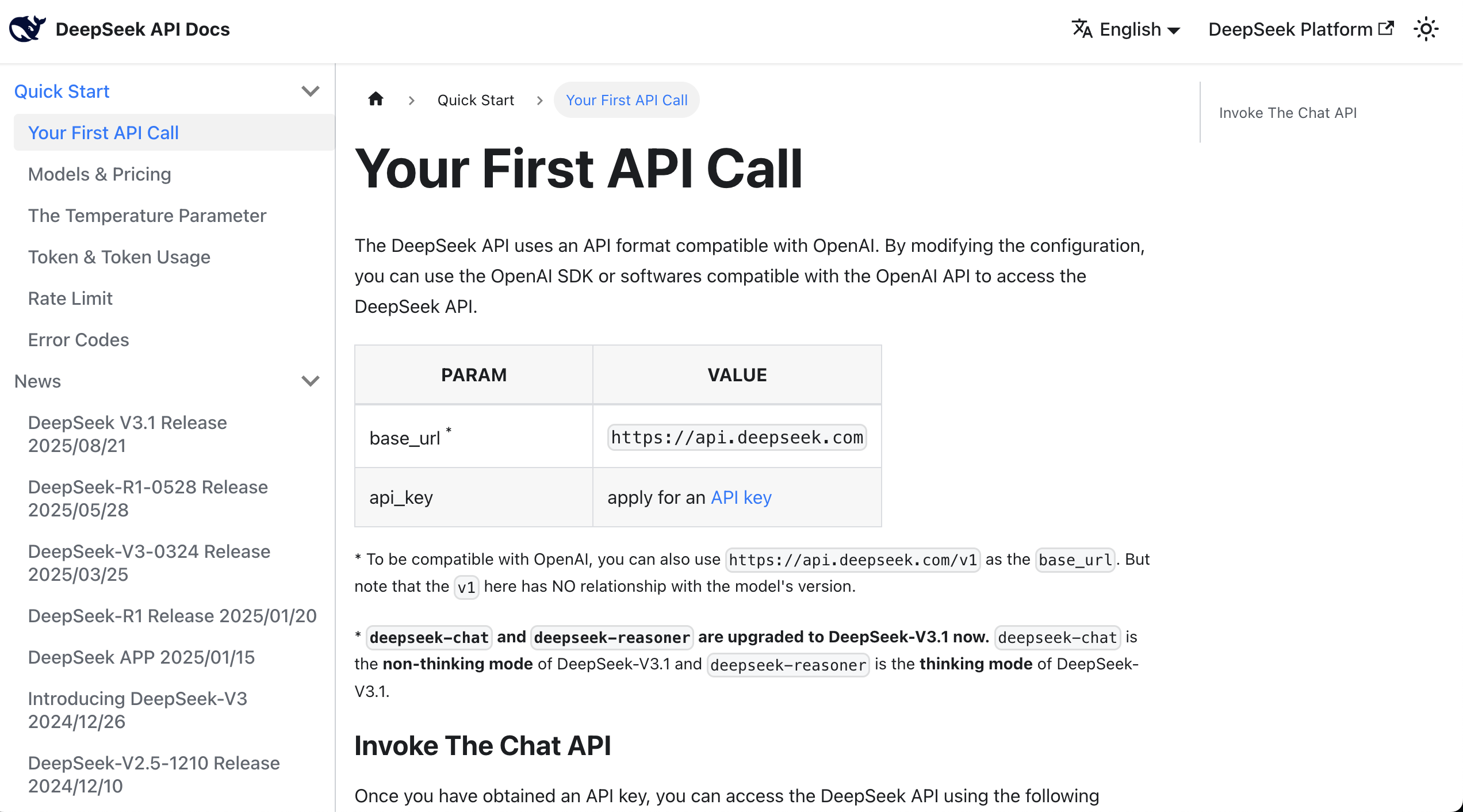
サンプルを見つけたら、ドキュメントの内容と Key をすべて AI IDE のチャットボックスにコピーし、大規模言語モデルを既存のプロトタイプに統合するよう依頼できます。
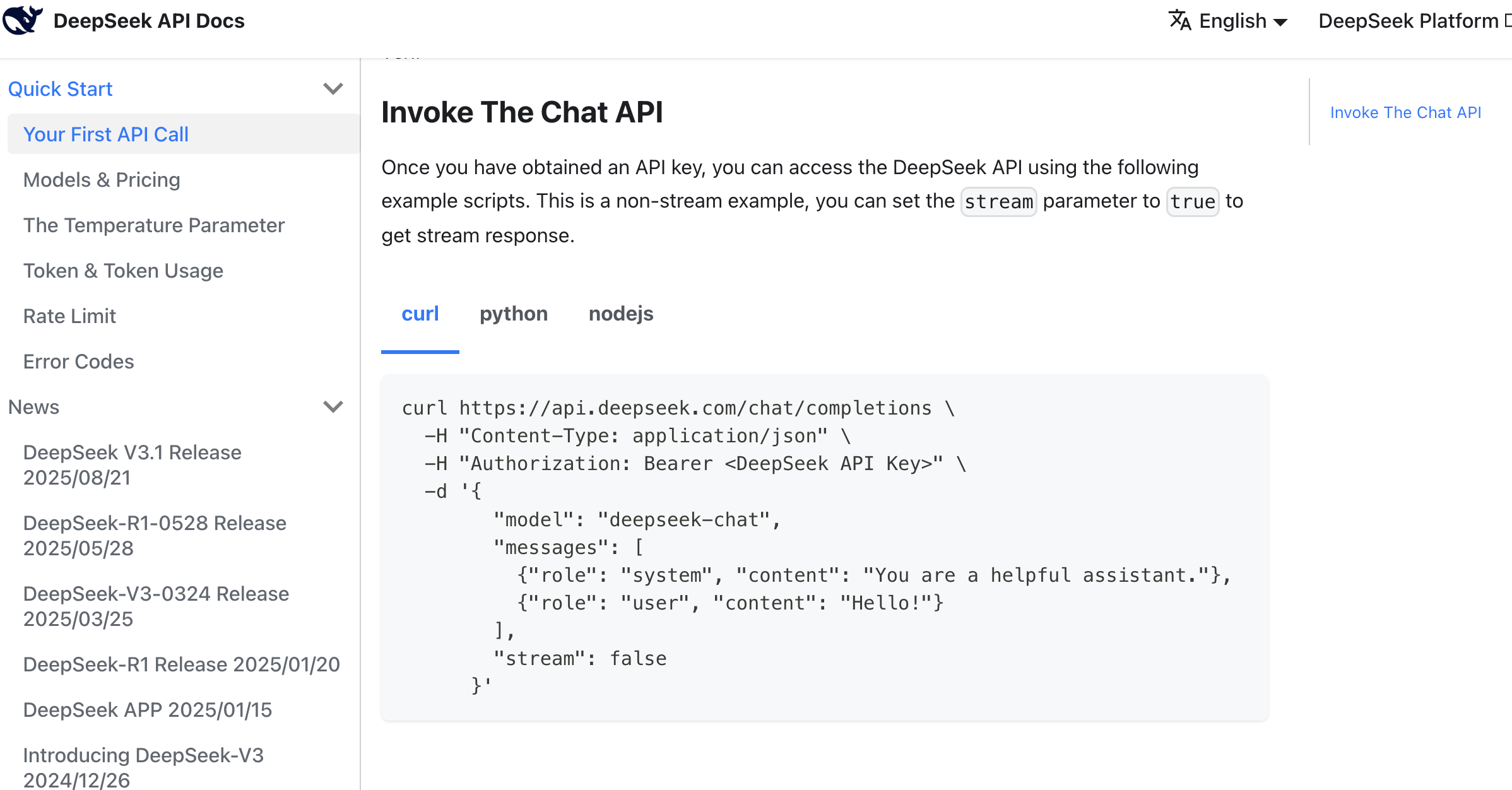
プロンプトの参考:
この呼び出し方法を参考に、コピーライティング生成機能をサポートしてください。商品情報に基づいてクリックすると対応する Douyin EC 用のキャッチコピーを生成し、複数のスタイルをサポートするようにしてください。
以下の参考資料:
api key:sk-8573341c39aefa1efe
api リクエスト参考:
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'AI のコード生成をしばらく待つと、対応するコピーライティング生成ボタンを簡単にテストできます。入口が見つからない場合は、AI IDE にどのページからそのページにアクセスできるか聞いてください。どうしても見つからない場合は、AI IDE に直接アイデアに基づいてリファクタリングと改良を依頼して、最終的なコピーライティング生成結果を得てください。
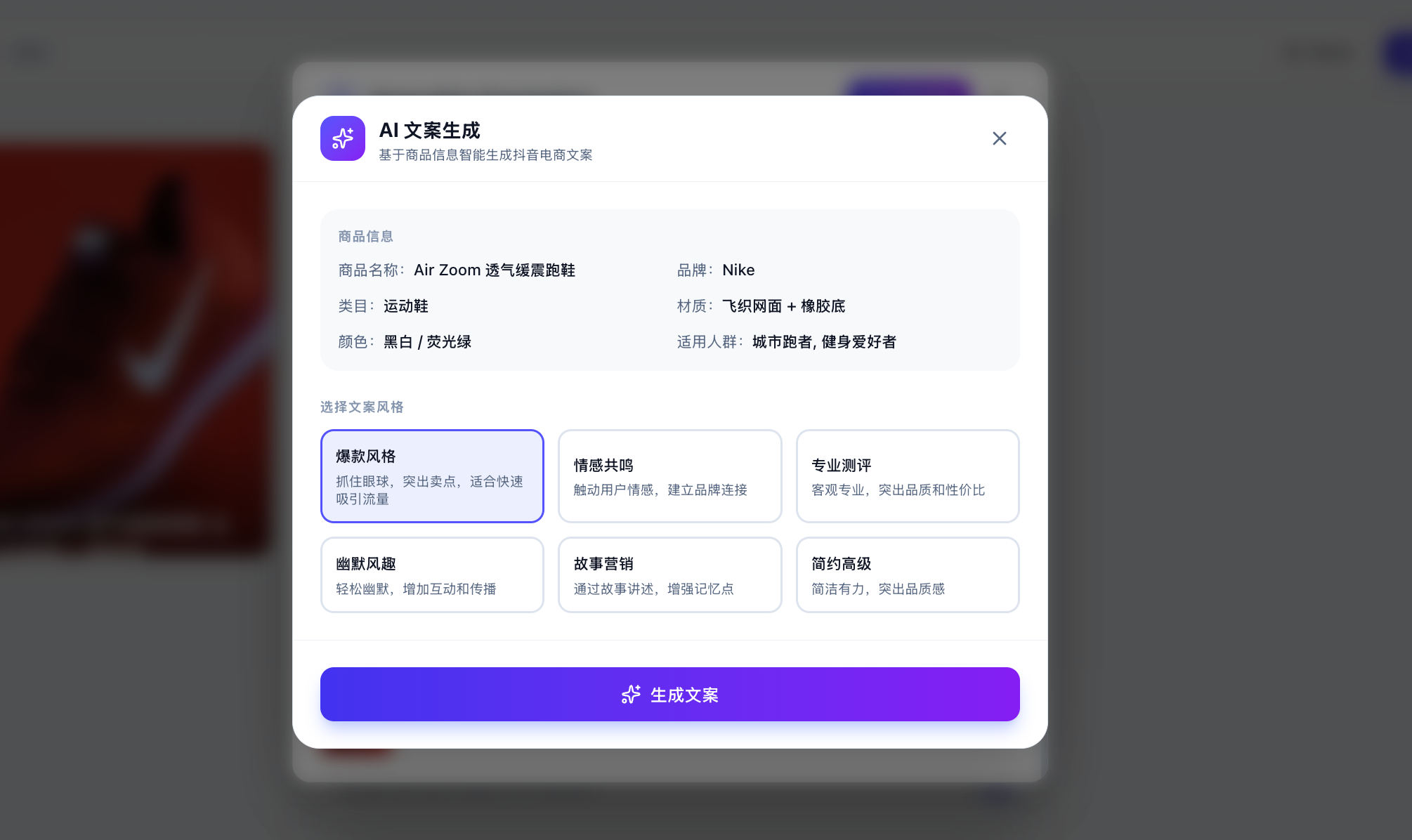
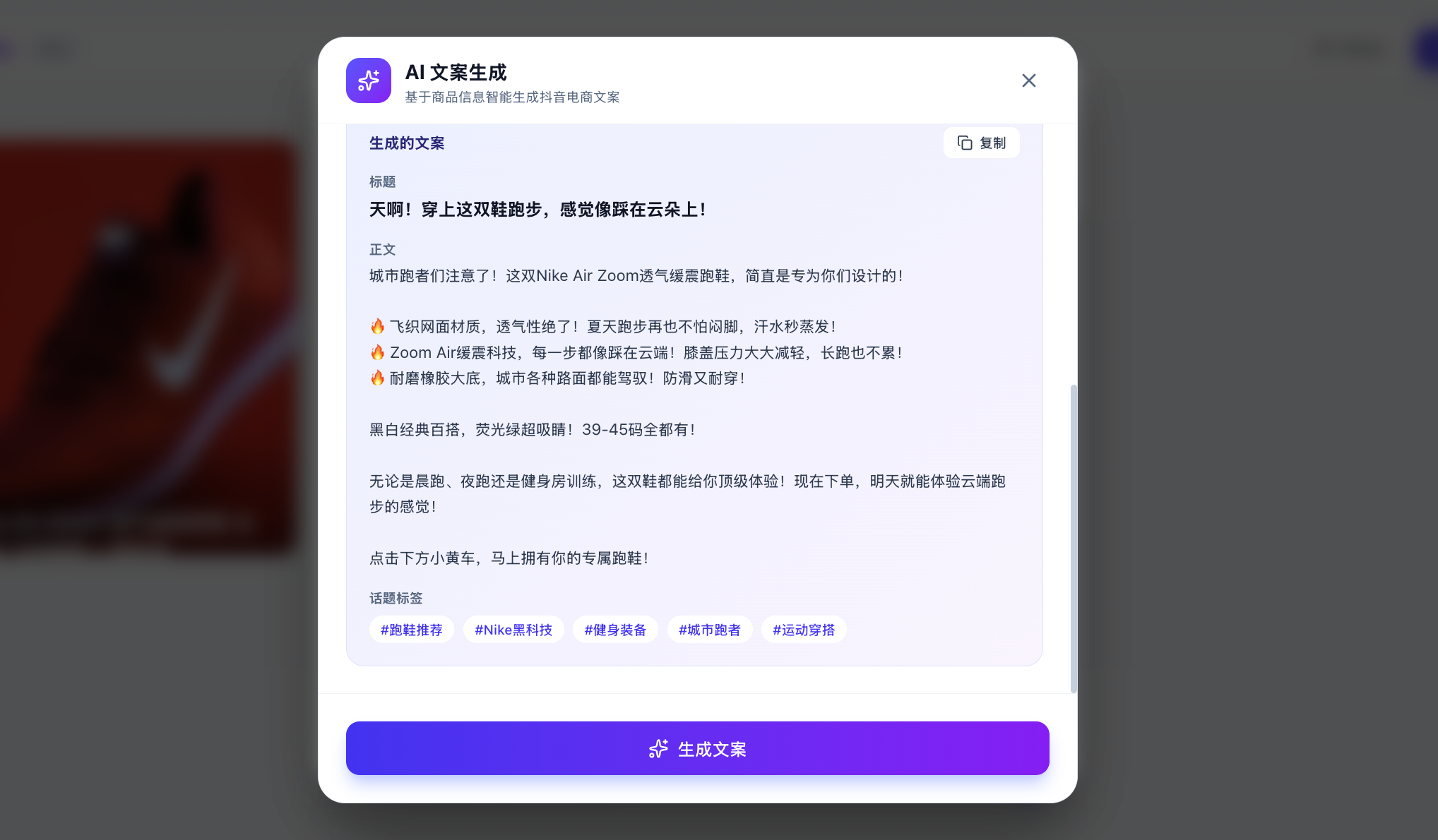
もちろん、ここで「本当に大規模モデルを呼び出しているのか、固定のレスポンスを内蔵しているだけなのか、どうやって確認するの?」と思うかもしれません。カスタムのテキストを入力して、大規模モデルがあなたが即座に指定したカスタム分析に基づいて対応するコピーライティングを生成させることで確認できます。
毎回結果が異なり、論理的であれば、API が正常に呼び出されていると安心できます。API 使用管理プラットフォームで呼び出しが成功したかどうかも確認できます(数分待つ必要がある場合があります)。
さらに多くのテキスト生成モデルの選択
DeepSeek 以外にも、他の大規模言語モデルも試せます。ほとんどのモデルは OpenAI 互換インターフェース を提供しているため、切り替えは非常に簡単です——API Key、ベース URL、モデル名を変更するだけです。
MiniMax 統合
詳細:MiniMax とは?
MiniMax は中国の人工知能企業で、汎用人工知能技術の研究開発に取り組んでいます。MiniMax は自社開発の MiniMax-M2.7 大規模言語モデルシリーズをリリースしており、多くのベンチマークテストで優れたパフォーマンスを示し、非常に高いコストパフォーマンスを誇ります。
MiniMax-M2.7 シリーズの主な特徴:
- 超長いコンテキスト:204,800 トークンのコンテキストウィンドウをサポート。長文書、多ラウンド対話に適している
- 高コストパフォーマンス:非常に競争力のある価格
- OpenAI 互換インターフェース:OpenAI SDK を直接使用して呼び出し可能。新しい API 形式を学ぶ必要がない
- 2つの利用可能なモデル:
MiniMax-M2.7:フラグシップモデル、複雑なタスクに適しているMiniMax-M2.7-highspeed:高速版、同じパフォーマンスを維持しながらより高速
統合方法は DeepSeek と同じで、3ステップだけです:
- MiniMax オープンプラットフォーム にアクセスしてアカウントを登録し、API Key を作成
- MiniMax ドキュメントで呼び出しサンプルを見つける
- API Key +サンプルを AI IDE に貼り付ける
MiniMax は OpenAI 互換インターフェースを提供しているため、以下の curl サンプルとあなたの API Key をコピーして、AI IDE に統合を依頼できます:
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.7",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'✅ ヒント
MiniMax の API 形式は DeepSeek とほぼ完全に同じです(どちらも OpenAI 互換形式)。したがって、DeepSeek の統合がすでに成功していれば、MiniMax に切り替えるには3つの箇所を変更するだけです:
- ベース URL:
https://api.minimax.io/v1に変更 - API Key:MiniMax の API Key を使用
- モデル名:
MiniMax-M2.7またはMiniMax-M2.7-highspeedに変更
詳細は MiniMax OpenAI 互換インターフェースドキュメント を参照してください。
3. 画像からテキスト API の統合:Qwen3 VL
ℹ️ 原理の詳細
原理に関する詳細を知りたい場合は、付録の 視覚言語モデル(VLM)入門 をご覧ください。
詳細:Qwen3 VL とは?
Qwen3 VL はアリババクラウドの通義千問チームがリリースしたマルチモーダル視覚言語モデルシリーズの最新版です。VL は「Vision-Language」、つまり視覚言語モデルを表します。画像内容を理解し、画像に基づいてテキストの説明を生成、画像に関する質問に回答、画像情報の抽出などができます。


Qwen3 VL の主な機能:
- 画像理解:画像中の物体、シーン、人物、テキストなどを認識
- 視覚 QA:ユーザーの質問に基づき、画像に関する質問に正確に回答
- 画像説明:詳細または簡潔な画像のテキスト説明を生成
- 複数画像理解:複数の画像を同時に処理し、比較分析をサポート
- テキスト抽出:画像からテキスト内容を抽出(OCR 機能)
なぜ Qwen3 VL を選ぶのか?
前世代モデルと比較して、Qwen3 VL は画像理解の正確さが大幅に向上し、より長く複雑な画像分析タスクをサポートしています。中国語理解で優れたパフォーマンスを示し、API 呼び出しコストが比較的低く、コストパフォーマンスが高いです。また、コンテキストウィンドウが大きく、より複雑な視覚推論タスクを処理できます。
典型的な応用シーン:
- EC:商品画像から自動的にタイトル、説明、セールスポイントを生成
- コンテンツ制作:素材画像に基づいて自動的にコピーや画像提案を生成
- オフィス:画像内容の抽出、帳票の自動認識
- 教育:画像問題の自動解析、知識ポイントの抽出
前のパートではテキスト生成 API の統合方法について説明しましたが、前のアプリケーションシーンでは一つの問題に気づきます。アップロードするのは画像ですが、大規模言語モデルだけでは画像の内容をうまく理解できず、生成結果に差が出る可能性があります。
画像をテキストの説明に変換してくれるモデルが欲しい。これには視覚言語モデル(VLM)が必要です。このケースでは、視覚言語モデルを使って商品のセールスポイント説明を生成し、ユーザー体験を向上させます。
利便性のため、クラウドプラットフォーム SiliconFlow が提供する API インターフェースを使用して、画像からテキストへの API を統合します。
詳細:SiliconFlow とは?
硅基流動(SiliconFlow) は中国国内で有名な AI モデル集約プラットフォームで、各種主流の大規模言語モデルと視覚言語モデルの API インターフェースサービスを提供しています。
プラットフォームの特徴:
- 多モデルサポート:DeepSeek、Qwen、Llama シリーズなどのオープンソースモデルを含む各種主流 AI モデルを統合
- 技術最適化:オープンソースモデルの推論を最適化し、低遅延・高並行の API サービスを提供
- インターフェース互換:OpenAI 形式と互換性のある API インターフェースを提供。既存のアプリケーション統合に便利
- 従量課金:呼び出し量に応じた課金に対応
SiliconFlow はオープンソース大規模モデルの推論サービスで比較的成熟しており、中国産オープンソース AI モデルを使用する際の一般的な選択肢の一つです。
SiliconFlow プラットフォームのホームページに入ると、多くのモデルが選択できることがわかります。左上のフィルターを見つけて展開し、視覚タグを選択すると、智譜 GLM-4.6V や Qwen3-VL など、多くの画像からテキストへのモデルが表示されます。
どれでも選んでテストできます。ここでは Qwen/Qwen3-VL-8B-Instruct を例にします。
SiliconFlow プラットフォーム に入り、API キーで「新建 API 密钥」をクリックして、新しい API Key を作成します。
以下のコードを参考コードとして、生成した API Key と一緒に AI IDE に送信し、機能統合を行えます。
画像からテキストへの参考コード
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
caption = caption_image(image_path)このシーンでは、AI IDE にアップロードされた画像から EC のセールスポイントテキストやキーワードを自動生成する機能を実装させます。以下のように指示します:
以下の画像からテキストへの API を基に、アップロードされた画像から EC のセールスポイントテキストとキーワードを自動生成する機能を実装してください。
<ここにコードを省略、キーと参考コードを自分で貼り付ける必要があります>最終的に生成結果が得られます: 
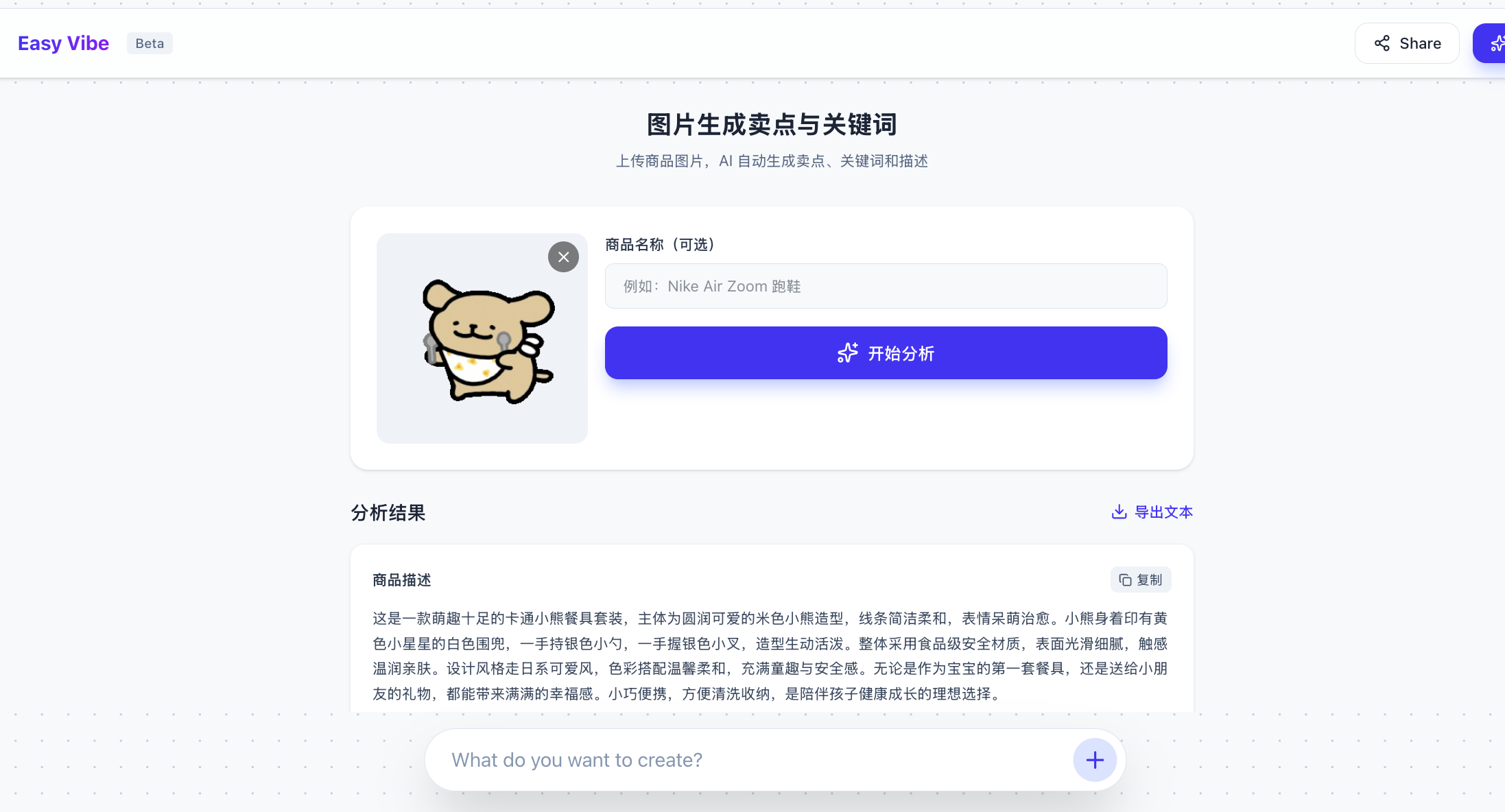
4. 画像生成 API の統合:Seedream 即梦
前のパートでは主にテキスト関連のタスクを扱いました。次は画像生成機能の統合に挑戦し、テキストの説明から画像を生成したり、画像を編集したりできるようにします。
ℹ️ 原理の詳細
原理に関する詳細を知りたい場合は、付録の 画像生成入門 をご覧ください。
詳細:Seedream 即梦 とは?

Google が開発した Nano Banana は知っているかもしれませんが、Seedream も見逃せません。Seedream 4.5 は ByteDance が開発した次世代画像クリエイティブモデルです。画像生成と画像編集の機能を統一アーキテクチャに統合しています。これにより、知識に基づく生成、複雑な推論、参照の一貫性などの複雑なマルチモーダルタスクを柔軟に処理できます。さらに、推論速度は前世代より大幅に高速で、最大4K解像度の驚くべき高画質画像を生成できます。


主な機能:
- テキストから画像(文生图):テキストの説明から画像を生成。複数のスタイル(リアル、カートゥーン、水墨、サイバーパンクなど)をサポート
- スタイル変換:画像を指定したアートスタイルに変換
- 画像バリエーション:参照画像に基づいて類似スタイルの新しい画像を生成
- 解像度向上:画像の鮮明さとディテールを向上
- 画像編集:自然言語の指示で既存の画像を編集・修正
なぜ Seedream を選ぶのか?
- 国内ネットワークが安定:国内からのアクセスが速く、遅延が低い
- 効果が優秀:EC、素材シーンで安定した信頼性
- 中国語最適化:中国語プロンプトの理解がより正確。国内ユーザーに適している
- 速度が速い:生成効率が高く、レスポンスタイムが短い
- 品質が安定:最大4K解像度の高画質画像を生成
典型的な応用シーン:
- EC:メイン画像、詳細ページ画像、プロモーションポスターの生成
- SNS:アバター、スタンプ、画像の生成
- デザイン:コンセプトアート、素材画像、背景画像の迅速な制作
- マーケティング:広告画像、イベントバナー、祝日ポスターの制作
Qwen3 VL との連携:
これら2つの API は直列で使用できます:まず Qwen3 VL で参照画像を分析し、画面内容を理解。次に Seedream で分析結果を基にプロンプトを生成し、新しい画像を作成します。
Douyin、Bilibili、YouTube で見かける「AI ポスター / AI メイン画像 / AI キャラクター画像」は、本質的にここで紹介する技術を使っています。あなたがやるべきことは非常にシンプルです:ユーザーの入力を一文に整理し、画像 API にリクエストを送り、返された画像を表示する。ここで使うモデルを画像生成 / 画像編集モデルと呼びます。
Seedream API をプロジェクトに統合する手順を順番にデモします(AI IDE のサポートを活用)。
ホームページにアクセスし、ログインをクリックします。
ログイン後、右上のチャージオプションを見つけます。
チャージには本人確認が必要です。
認証成功後、1元をチャージしてテストできます。
初期画面に戻り、API アクセスをクリックします。
まず、API key を作成し、オプション選択をクリックします。
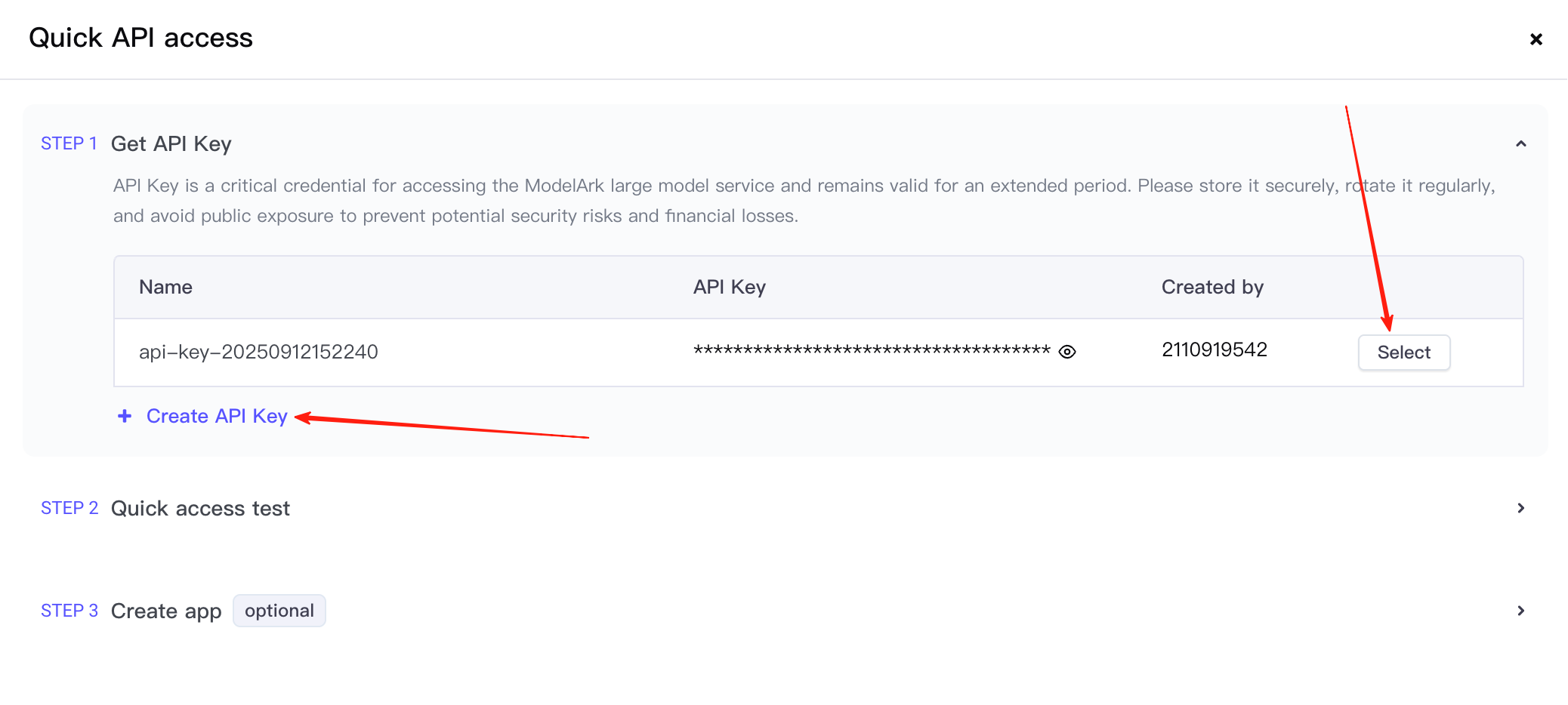
これでステップ2に進みます。ここで、呼び出すサービスが Seedream 4.5 であることを確認し、提供された呼び出しサンプルをコピーします。(スクリーンショットが比較的早い時期のものなので、モデルバージョンはまだ4.0です)
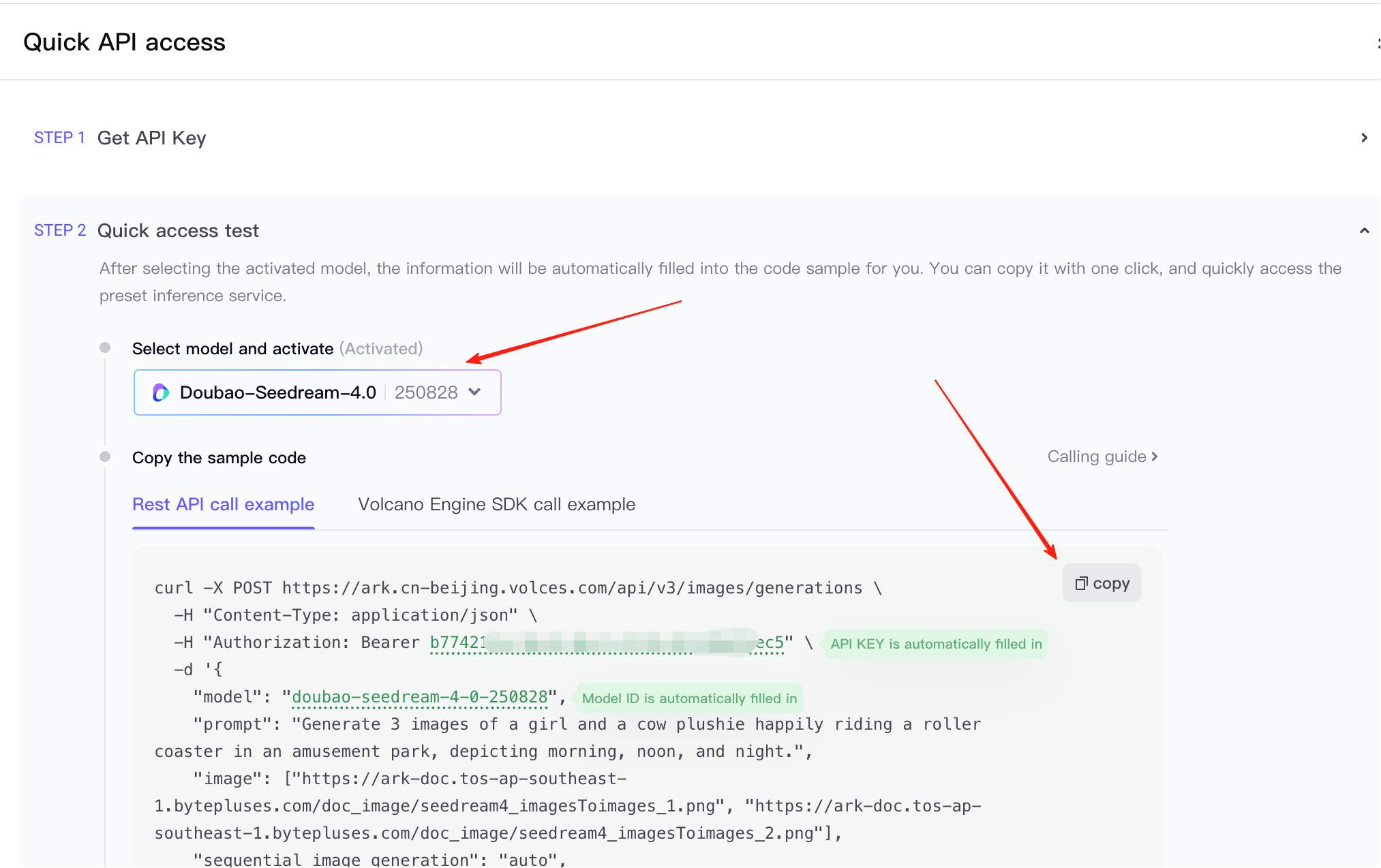
API Key と呼び出しサンプルの準備ができたら、AI IDE に直接貼り付けて、フロントエンドのインタラクティブデモを生成させるか、既存のプロトタイプに機能を統合させます。画像でテキストから画像か複数画像から単一画像かを選択できることに注意してください。現在のニーズに応じて参考コードを選択してください。
⚠️ 重要なヒント
ここでのデフォルトのサンプルは比較的複雑です。「ウォーターマーク追加」 と 「ストリーミングレスポンス」 を無効にすることを忘れないでください。ウォーターマークが生成されず、リクエスト失敗が発生しないようにするためです。
後で参照画像生成モードを使用するため、まずは複数画像から単一画像への機能に行きます。参考コードは以下の通り:
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "将图1的服装换为图2的服装",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'画像参照コードが得られたら、AI IDE に EC で一般的に使われる画像タスク機能をサポートさせます:
以下の API を基に、このプロジェクトの EC ビジネスの一般的な機能(ポスター生成、Douyin EC メイン画像生成など)を実装してください。
<ここに API KEY と画像編集コードを貼り付けてください>実装効果は以下の通り:
注目すべき点として、画像生成では奇妙な問題に頻繁に遭遇する可能性があるため、AI IDE に完全なエラーメッセージを表示させることをお勧めします。コピー&ペーストで修正しやすくするためです(そうしないと、「生成に失敗しました」と何度も表示されるが、理由が分からないという状況になる可能性があります)。例えば、次のように言えます:
画像生成失敗とだけ表示せず、毎回完全な失敗理由(画像不一致、リクエストエラー、タイムアウトなど)を表示してください!修正後に更新がウェブページに反映されないことがあります。修正後もウェブページでエラーが出続ける場合(何度も)、AI IDE に直接「このプロジェクトを再起動してください」と言ってみてください。
EC ビジネスでは、ユーザーがアップロードした服を自動的にキャラクターに着せたり、商品の魅力的な販売画像やポスターを自動生成したりしたい場合があります。ここでは、EC ポスターを生成させるプロンプトを試します:
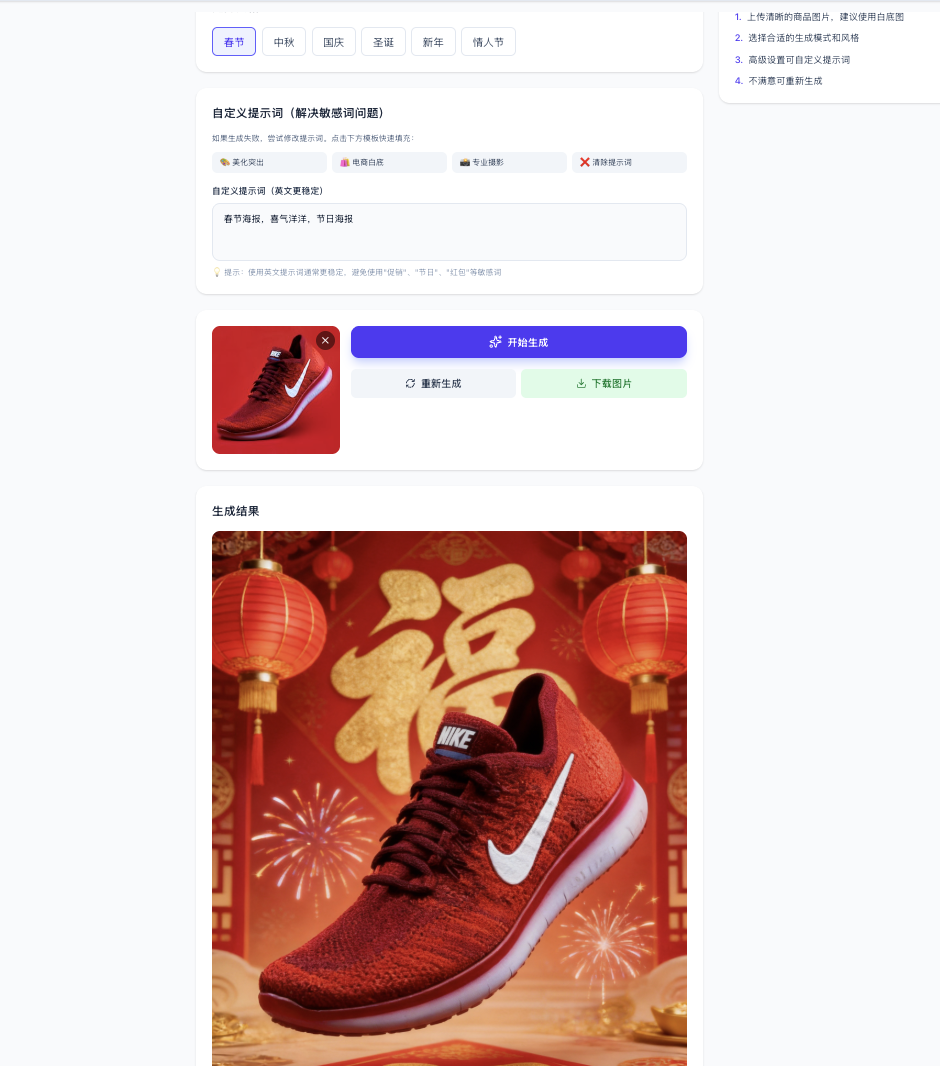
自分の想像するビジネスシーンに応じて、テキストから画像または画像から画像 API を使って異なる機能を実装できます。
さらに多くの画像サービスの選択
以下に他の選択肢を示します。まず Qwen 画像生成の結果を動かし、効果とコストに応じて以下のサービスで差し替えることをお勧めします(実際の使用感に基づいて選択)。
Recraft 統合
プロトタイプが「デザイン制作」寄りの場合(ブランドスタイルのイラスト、マーケティングポスター、ベクタースタイル素材の生成など)、Recraft の方が使いやすいことが多いです。統合方法は前のセクションと完全に同じです:Key を取得 + 公式サンプルを見つける + AI IDE にサンプルをボタン/ページに落とし込ませる。
詳細:Recraft とは?
Recraft はデザイナー、イラストレーター、マーケター向けの AI ツールで、2022年に米国で設立され、本社はロンドンにあります。ビジュアル効果(画像、ベクターアート、3D グラフィックス)の生成・イテレーションを支援し、高品質な出力(任意のテキストサイズ/長さ)、正確な要素の配置、ブランドの一貫性のあるデザインなどの利点があります。200カ国/地域の300万人以上のユーザー(Ogilvy、Netflix など含む)に信頼され、3.5億枚以上の画像が作成されています。チームはこれをデザイナーの必須ツールにすることを目指し、クリエイターが AI 補助ワークフローをコントロールできるようにしています。


まず、API エントリ を見つけて API Key を取得する必要があります。
ここでは無料枠が提供されていないため、1,000 クレジットを自分でチャージする必要があります。このサイトは Alipay と WeChat Pay に対応しているため、1,000 クレジットは簡単に取得できます(注意:必要以上にチャージしないでください)。

その後も同じ方法に従います:公式ドキュメントで対応するリクエストサンプルを見つけます:
Qwen Image / Qwen Image Edit 統合
画像生成サービスをよりシンプルな方法で統合したい場合は、Qwen Image(通義万相)を検討できます。アプローチは同じです:「画像生成 API」として扱い、プロトタイプのボタンに接続するだけです。
詳細:Qwen Image / Qwen Image Edit とは?
Qwen Image(通義万相とも呼ばれる)は、アリババクラウドの通義チームがリリースした画像生成モデルシリーズで、主に2つのモデルを含みます:
1. Qwen Image——テキストから画像(Text-to-Image)モデル
テキストの説明から全く新しい画像を生成します。プロンプトを入力すると、モデルがあなたの意図を理解し、説明に合った画像を生成します。

主な機能:
- テキストから画像(文生图):テキストの説明から画像を生成。複数のスタイル(リアル、カートゥーン、水墨、サイバーパンクなど)をサポート
- スタイル変換:画像を指定したアートスタイルに変換
- 画像バリエーション:参照画像に基づいて類似スタイルの新しい画像を生成
- 解像度向上:画像の鮮明さとディテールを向上
2. Qwen Image Edit——画像から画像(Image-to-Image)モデル
既存の画像を編集・修正します。自然言語の指示で、モデルに修正の意図を理解させ、結果を生成させます。
主な機能:
- 部分置換:画像中の特定の物体や人物を置換(「背景を海辺に変えて」など)
- 要素削除:画像から不要な要素を削除
- スタイル変換:画像にフィルターやアート効果を追加
- 画像拡張:画像の境界を拡張し、新しいコンテンツを生成
- スマートレタッチ:自動美化、光影調整、欠陥修正



なぜ Qwen Image シリーズを選ぶのか?
- 中国語最適化:中国語プロンプトの理解がより正確。国内ユーザーに適している
- 低コスト:海外競合と比較して価格が手頃
- 高速:生成効率が高く、レスポンスタイムが短い
- 安定した品質:EC、素材シーンで安定した信頼性
- 多様なスタイル:様々なアートスタイルとクリエイティブ効果をサポート
典型的な応用シーン:
- EC:メイン画像、詳細ページ画像、プロモーションポスターの生成
- SNS:アバター、スタンプ、画像の生成
- デザイン:コンセプトアート、素材画像、背景画像の迅速な制作
- マーケティング:広告画像、イベントバナー、祝日ポスターの制作
SiliconFlow の公式サイトを確認してください。左側に「Playground」セクションがあり、API 呼び出しなしで様々なモデルを試せます。ページ上部に「Filters」ボタンがあります。クリックすると右側のモデルリストをフィルタリングできます。
「Image」を選択すると、現在サポートされているすべてのテキストから画像へのモデルだけが表示されます。ここでは Qwen/Qwen-Image を使用します。
すべての設定が完了したら、対応する画像生成 API ドキュメントを参照する必要があります。公式ドキュメントページで「API Reference」とマークされたセクションを見つけてください。クリックして 画像生成の API セクション にナビゲートし、関連するリクエストサンプルを見つけます。
以下のリクエストサンプルと API KEY を AI IDE に送信するだけで、画像生成機能を実装できます。
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'ここでのモデルは Qwen/Qwen-Image または Qwen/Qwen-Image-Edit-2509 を使用できます。
画像編集参考コード
以下のコードと Key をコピーして、AI IDE に送信します:
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "让天空变成傍晚,有月亮和星星,梦幻风格"
negative_prompt: str = "模糊, 低质量, 扭曲"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")付録:「現在より強力な」AI モデルを見つける方法
テキストモデル(大規模言語モデルとも呼ばれる)の発展は非常に速く、常により良いパフォーマンスを示すモデルを使用していることを確認する必要があります。以下の2つのウェブサイトで、「現在よく使われ、評価も高いモデル」を簡単に確認できます。
一般的に、この種のウェブサイトは 「モデルアリーナ」 と理解できます:2つのモデルの出力を並べて表示し、より好きな方に投票します。票が多いモデルは、より多くの人が「使いやすい」と思っていることを意味します。
また、これらの大規模モデルアリーナで謎の匿名モデル(「Unknown Model」)が表示されることがあります。これは通常、「内部テストモデル」がこっそりブラインドテストに参加していることを意味し、より強力な能力に先取りして体験できるチャンスがあるかもしれません。
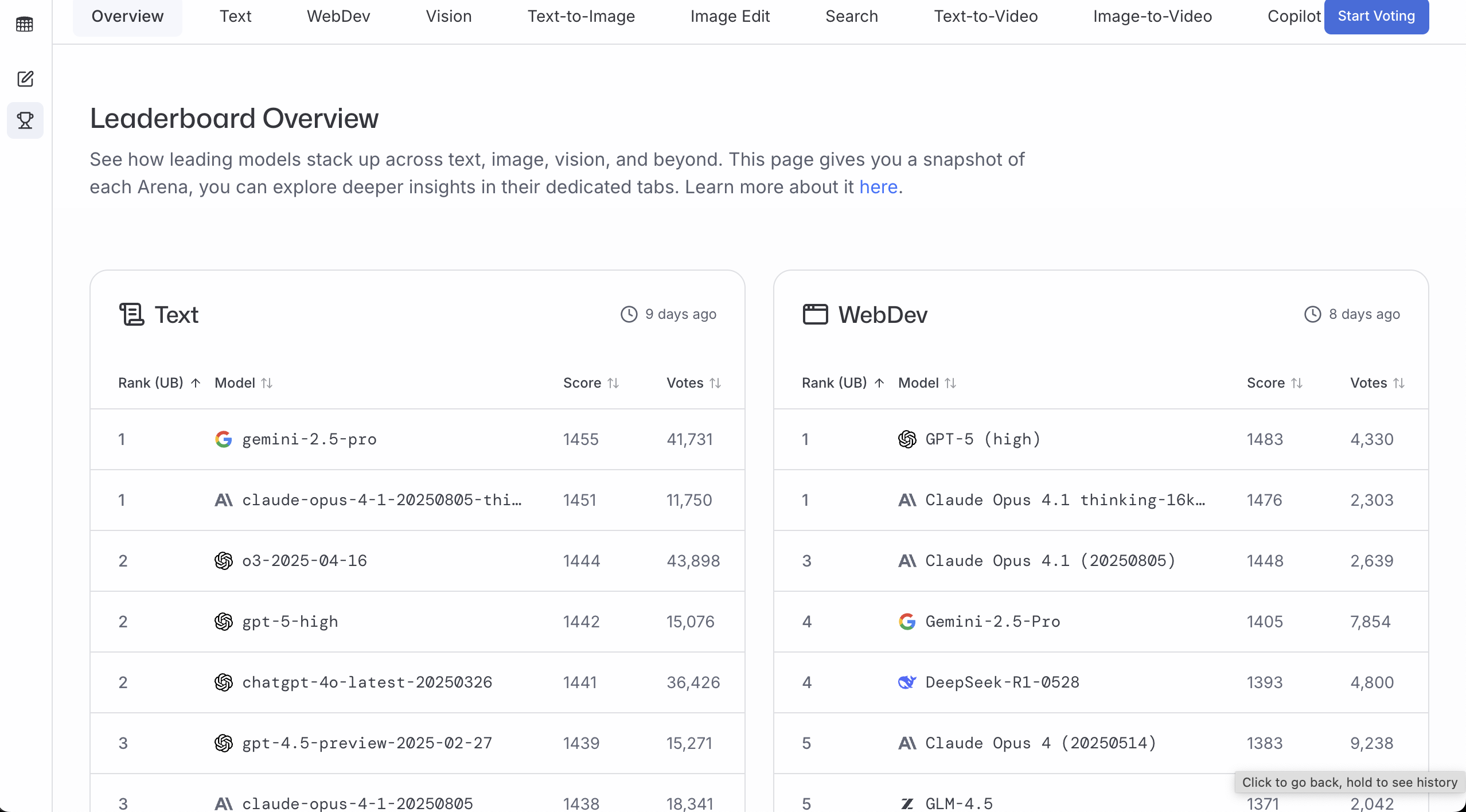
LMArena
ウェブサイト:https://lmarena.ai/
LMArena は「より多くの人がどのモデルの回答を好むか」を判断するのに適しています。投票数が多く、スコアが高いほど、実際の使用シーンでより安定していることを意味します。
簡単な使い方:
- リーダーボード(Leaderboard)を直接見る
- 目的の方向(一般対話 / プログラミング / ビジョンなど)を選ぶ
- トップ3の中で使えるもの(アクセス可能、価格が受け入れられる、遅延が受け入れられる)を選ぶ
Artificial Analysis
ウェブサイト:https://artificialanalysis.ai/
Artificial Analysis は「効果 / 価格 / 速度」を同じ表で比較するのに適しています。モデル選定のパラメータシートとして使えます。
一般的な使い方:
- 関心のあるモデルカテゴリ(テキスト / 画像生成など)を見つける
- 品質指標(Quality)+価格(Price)+遅延/スループット(Latency/Throughput)を見る
- 「総合的なコストパフォーマンス」がプロダクトに最も合うものを選ぶ
✅ 推奨
「どちらが強いか」を感覚で議論しないでください。より信頼性のある方法は:同じ入力で2〜3つのモデルを同時にテストし、ランキングと価格を組み合わせて決定することです。
まとめ
各種 AI サービスを統合する際、API を複雑に想像する必要はありません。以下の核心的な概念を把握すれば、ほとんどのシーンに対応できます:
API の本質は通信の橋渡しです。やっていることはシンプル:あなたのリクエストを送信し、モデルのレスポンスを持ち帰る。背後で何が起きているかを気にする必要はなく、リクエスト形式を正しく組織するだけで済みます。
SDK は API のラッパーです。API が raw インターフェースだとすれば、SDK は既成のツールキットです——リクエスト署名、エラーハンドリング、パラメータ検証などの面倒な詳細をすべて処理してくれます。日常の開発では、直接 API を呼び出すより SDK を優先して使うと、多くの手間が省けます。
ドキュメントを読むときは、3つのことに注目するだけで十分です:サービスアドレス(endpoint)、認証情報(API key)、呼び出しパラメータの書き方。この3点を明確にすれば、統合は時間の問題です。
残りの作業は、IDE とモダンな開発ツールがやってくれます。ビジネスロジックに集中し、低レベルの呼び出しはこれらの成熟した SDK とツールチェーンに任せましょう。
5. 📚 課題:最初の AI 能力を統合する
この授業のプロンプトと内容を参考に、完全なクローズドループを完了してください:
- 完全なクローズドループの実践
- 一つの AI サービス(LLM / テキストから画像 / 画像から画像)を選択し統合 → フロントエンドとバックエンドのインタラクションを実装 → プロトタイプに統合
- 成果の共有
- 機能ページのスクリーンショットをみんなにシェアする
- 思考問題
- 次の「完全なプロジェクト実践」のために空間を確保し、事前に考える:これらの AI 能力をどのように組み合わせて、面白い機能を作るか?
次のステップ
次のセクションでは、これらの分散した AI 能力を繋ぎ合わせ、実際のビジネスシーンに基づいた完全なプロダクトを作ります:
- コンテンツ企画、商品出品、データ分析などのプロセスを一つの完全なビジネスフローに繋げる
- この授業で学んだ AI 能力(LLM コピーライティング生成、テキストから画像、画像編集など)を実際のビジネスノードに組み込む
- 孤立したデモではなく、本当に使える「EC AI ワークスペース」を実装する